檔案說明:
1.dataset:假新聞資料集,因為github有容量限制,所以只傳部分檔案,需要完整檔案請至kaggle下載。
2.suicide_dataset:自殺留言資料集。
3.BertForSequenceClassification.ipynb:用假新聞資料集來訓練BERT來做分類任務。
4.suicide_bert.ipynb:用自殺留言資料集來訓練BERT來做分類任務。
BERT介紹
BERT 全名為 Bidirectional Encoder Representations from Transformers,是 Google 以無監督的方式利用大量無標註文本「煉成」的語言代表模型,其架構為 Transformer 中的 Encoder。
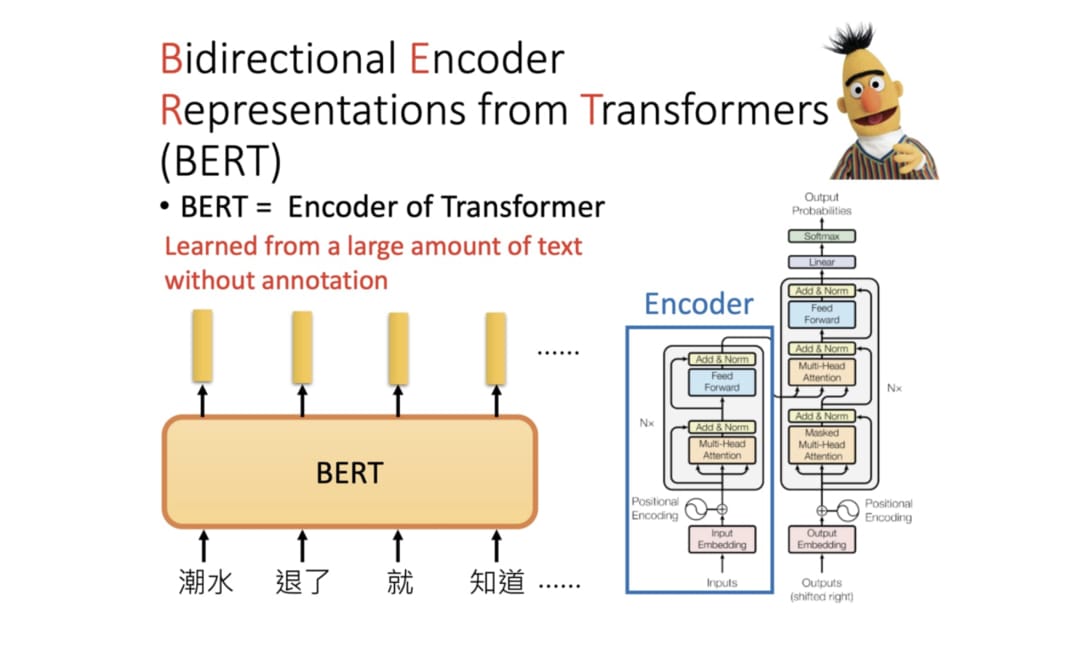
Google 在預訓練 BERT 時讓它同時進行兩個任務:
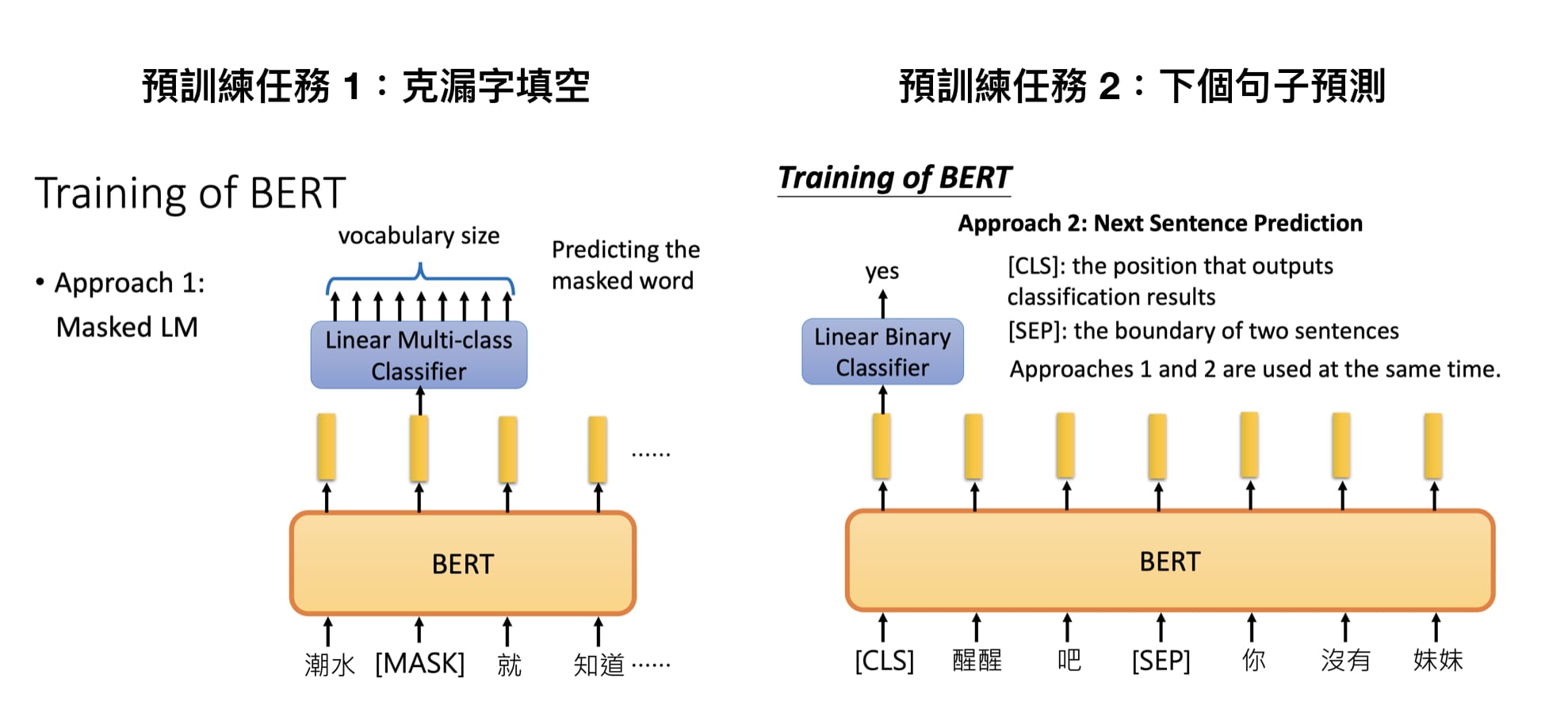
克漏字填空(1953 年被提出的 Cloze task,學術點的說法是 Masked Language Model, MLM) 判斷第 2 個句子在原始文本中是否跟第 1 個句子相接(Next Sentence Prediction, NSP
目前在Hugging Face transformers的開源套件提供幾個BERT預訓練模型1.bert-base-chinese 2.bert-base-uncased 3.bert-base-cased 4.bert-base-german-cased 5.bert-base-multilingual-uncased 6.bert-base-multilingual-cased 7.bert-large-cased 8.bert-large-uncased 9.bert-large-uncased-whole-word-masking 10.bert-large-cased-whole-word-masking
這些模型的參數都已經被訓練完成,而主要差別在於: 1.預訓練步驟時用的文本語言 2.有無分大小寫 3.層數的不同 4.預訓練時遮住 wordpieces 或是整個 word
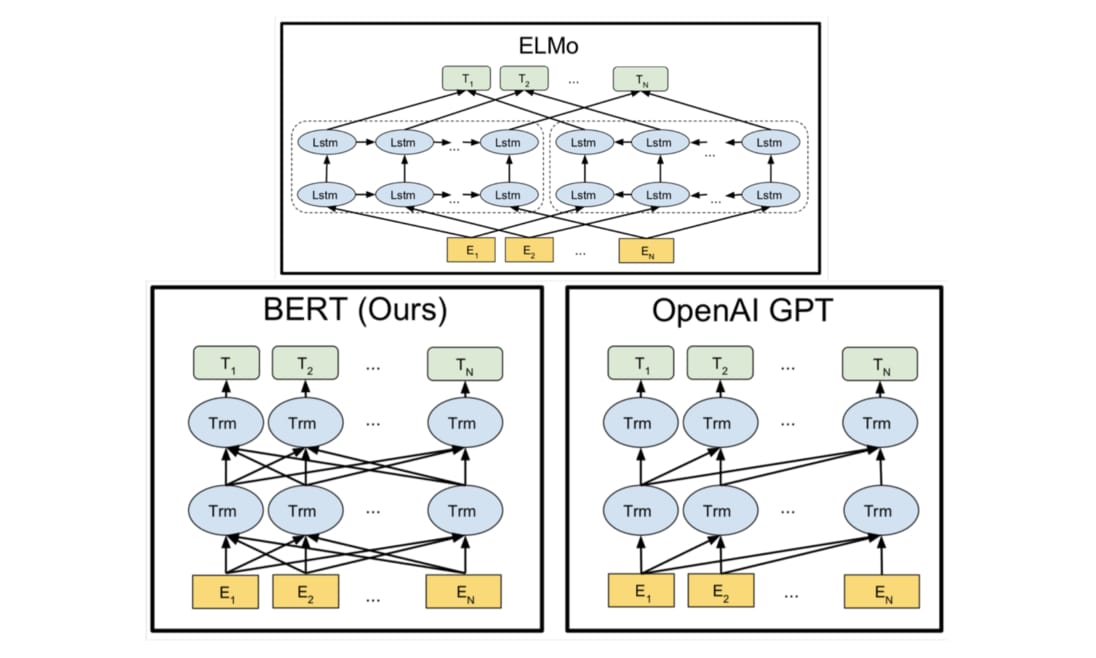
ELMo 利用獨立訓練的雙向兩層 LSTM 做語言模型並將中間得到的隱狀態向量串接當作每個詞彙的 contextual word repr.;GPT 則是使用 Transformer 的 Decoder 來訓練一個中規中矩,從左到右的單向語言模型。 BERT 跟它們的差異在於利用 MLM(即克漏字)的概念及 Transformer Encoder 的架構,擺脫以往語言模型只能從單個方向(由左到右或由右到左)估計下個詞彙出現機率的窘境,訓練出一個雙向的語言代表模型。這使得 BERT 輸出的每個 token 的 repr. Tn 都同時蘊含了前後文資訊,真正的雙向 representation。
有了這樣的概念以後,我們接下來要做的事情很簡單,就是將自己感興趣的 NLP 任務的文本丟入 BERT ,為文本裡頭的每個 token 取得有語境的 word repr.,並以此 repr. 進一步 fine tune 當前任務,取得更好的結果。
fine tune BERT 來解決新的下游任務有 5 個簡單步驟: 1.準備原始文本數據 2.將原始文本轉換成 BERT 相容的輸入格式 3.在 BERT 之上加入新 layer 成下游任務模型 4.訓練該下游任務模型 5.對新樣本做推論
我們可看出步驟 1、4 及 5 都跟訓練一般模型所需的步驟無太大差異。跟 BERT 最相關的細節事實上是步驟 2 跟 3: 如何將原始數據轉換成 BERT 相容的輸入格式? 如何在 BERT 之上建立 layer(s) 以符合下游任務需求?
以假新聞分類任務為例回答這些問題。這個任務的輸入是兩個句子,輸出是 3 個類別機率的多類別分類任務(multi-class classification task)。
準備原始文本數據 以 BERT fine tune 一個假新聞的分類模型,可以先前往該 Kaggle 競賽下載資料集。下載完數據你的資料夾裡應該會有兩個壓縮檔,分別代表訓練集和測試集:


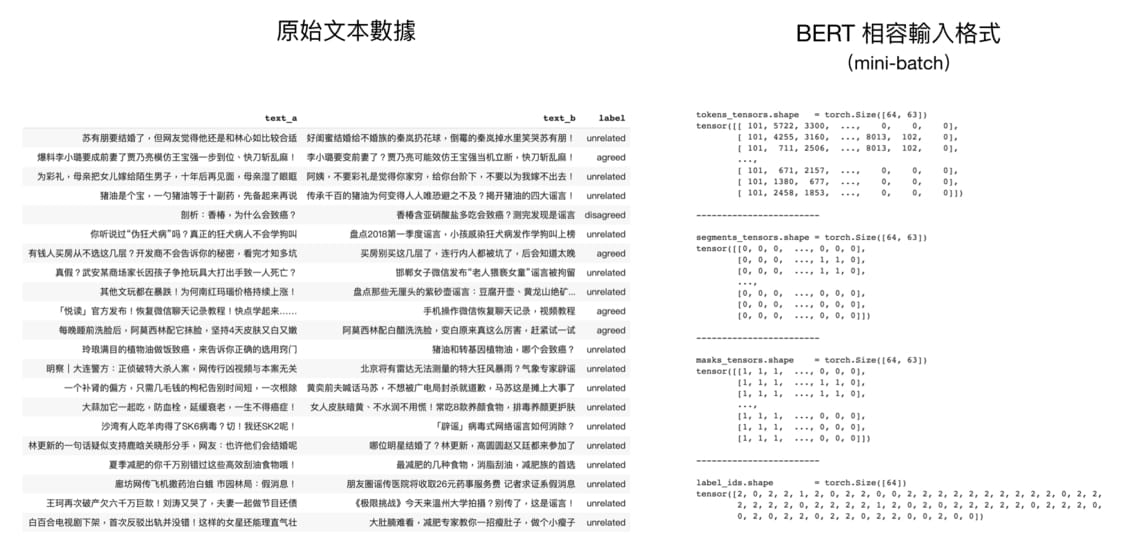
將原始文本轉換成 BERT 相容的輸入格式 處理完原始數據以後,最關鍵的就是了解如何讓 BERT 讀取這些數據以做訓練和推論。這時候我們需要了解 BERT 的輸入編碼格式。
這步驟是本文的精華所在,你將看到在其他只單純說明 BERT 概念的文章不會提及的所有實務細節。以下是原論文裡頭展示的成對句子編碼示意圖:
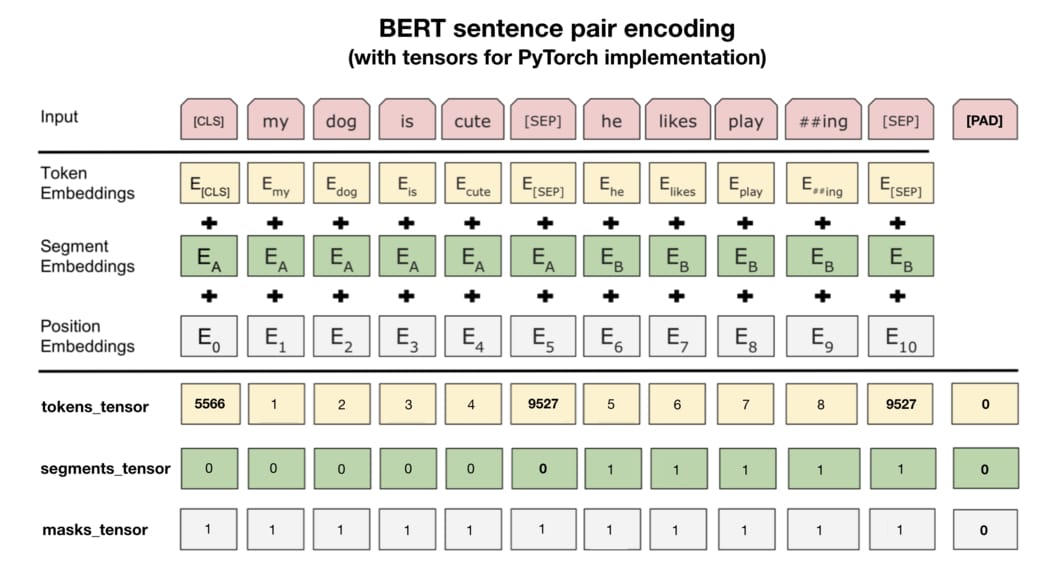
實際運用 BERT 時最重要的則是在第二條分隔線之下的資訊。我們需要將原始文本轉換成 3 種 id tensors: 1.tokens_tensor:代表識別每個 token 的索引值,用 tokenizer 轉換即可 2.segments_tensor:用來識別句子界限。第一句為 0,第二句則為 1。另外注意句子間的 [SEP] 為 0 3.masks_tensor:用來界定自注意力機制範圍。1 讓 BERT 關注該位置,0 則代表是 padding 不需關注
論文裡的例子並沒有說明 [PAD] token,但實務上每個 batch 裡頭的輸入序列長短不一,為了讓 GPU 平行運算我們需要將 batch 裡的每個輸入序列都補上 zero padding 以保證它們長度一致。另外 masks_tensor 以及 segments_tensor 在 [PAD] 對應位置的值也都是 0,切記切記。
在 BERT 之上加入新 layer 成下游任務模型 原論文提到的 4 種 fine-tuning BERT 情境,並整合了一些有用資訊:
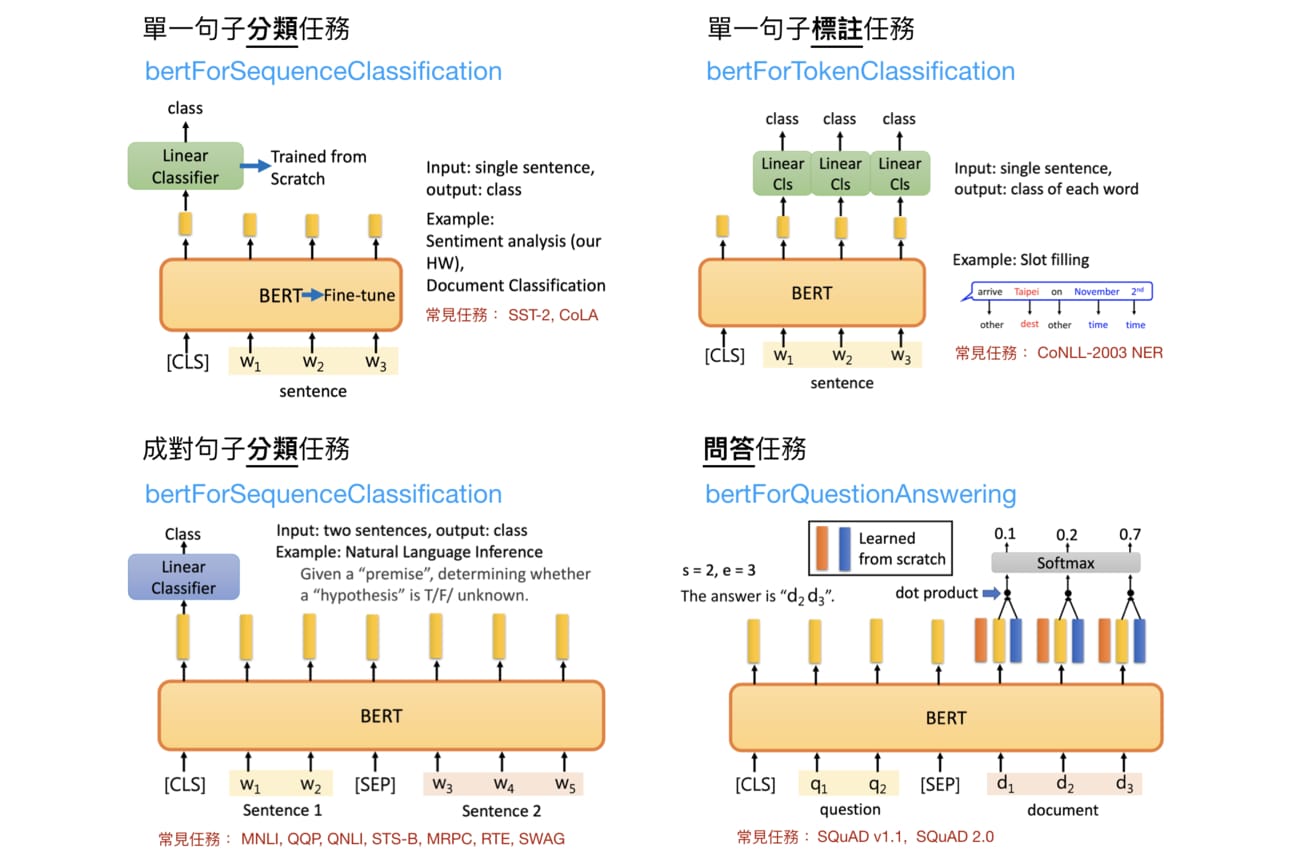
首先,我們前面一直提到的 fine-tuning BERT 指的是在預訓練完的 BERT 之上加入新的線性分類器(Linear Classifier),並利用下游任務的目標函式從頭訓練分類器並微調 BERT 的參數。這樣做的目的是讓整個模型(BERT + Linear Classifier)能一起最大化當前下游任務的目標。 不過現在對我們來說最重要的是圖中的藍色字體。多虧了 HuggingFace 團隊,要用 PyTorch fine-tuing BERT 是件非常容易的事情。每個藍色字體都對應到一個可以處理下游任務的模型,而這邊說的模型指的是已訓練的 BERT + Linear Classifier。 按圖索驥,因為假新聞分類是一個成對句子分類任務,自然就對應到上圖的左下角。FINETUNE_TASK 則為 bertForSequenceClassification
訓練該下游任務模型 接下來沒有什麼新玩意了,除了需要記得我們前面定義的 batch 數據格式以外,訓練分類模型 model 就跟一般你訓練模型做的事情相同。
對新樣本做推論 看看 BERT 本身在 fine tuning 之前與之後的差異。以下程式碼列出模型成功預測 disagreed 類別的一些例子:

{kind=link}
其實用肉眼看看這些例子,以你對自然語言的理解應該能猜出要能正確判斷 text_b 是反對 text_a,首先要先關注「謠」、「假」等代表反對意義的詞彙,接著再看看兩個句子間有沒有含義相反的詞彙。
結語 1.何謂 BERT以及其運作的原理 2.將文本數據轉換成 BERT 相容的輸入格式 3.依據下游任務 fine tuning BERT 並進行推論
相關連結:
1.https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html
2.https://www.kaggle.com/c/fake-news-pair-classification-challenge/