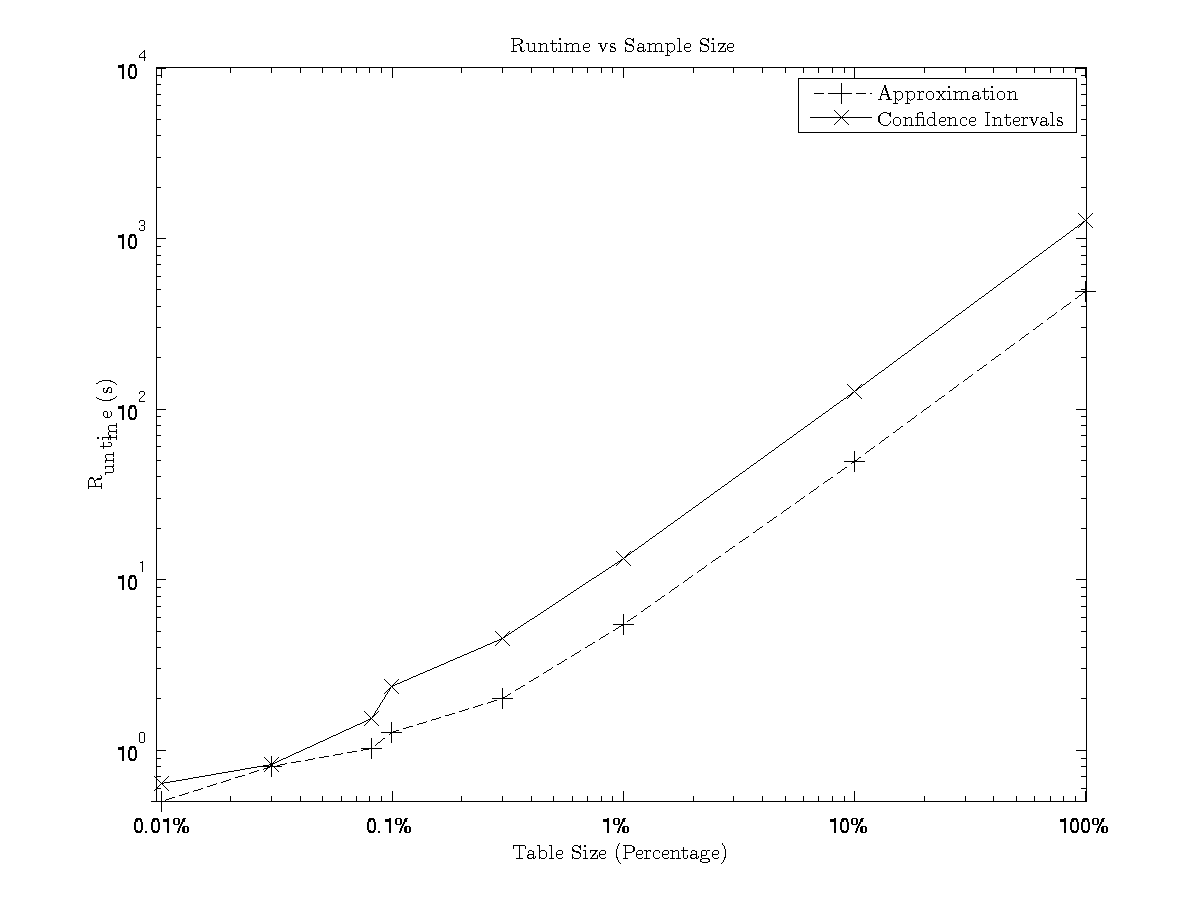
Least Squares at Scale is a UDAF extension to BlinkDB for performing linear regression on very large data sets. By leveraging the underlying BlinkDB sampling abilities, we can perform accurate least squares in near realtime on large HDFS datasets, as well as provide confidence intervals. Least squares at scale is able to both train as well as apply linear regression. For more information, see the whitepaper.
BlinkDB is a large-scale data warehouse system built on Shark and Spark and is designed to be compatible with Apache Hive. It can answer HiveQL queries up to 200-300 times faster than Hive by executing them on user-specified samples of data and providing approximate answers that are augmented with meaningful error bars. BlinkDB 0.1.0 is an alpha developer release that supports creating/deleting samples on any input table and/or materialized view and executing approximate HiveQL queries with those aggregates that have statistical closed forms (i.e., AVG, SUM, COUNT, VAR and STDEV).
- Scala 2.10.x
- Spark 0.9.x