Example with random graph and random time-series signal. Implementation of the algorithm from Anomaly detection in the dynamics of web and social networks paper.
In this example, we use a random graph. The results largely depend on the structure of the graph. The results are much better when the structure of network makes sense (for example, social network or hyperlinks network). This is just a (very inefficient) demonstration for practitioners.
Below, you can see the result of the code example provided here where the graph and time-series signals are random. Even though example initializes with a very dense random network, which does not provide any structural insights, we manage to get a prominent anomalous cluster. In order to get better results with your data, use underlying graph structure instead (social network, hyperlinks network). Unless you have that kind of graph, constructing a nearest neighbours graph is a better option than a random graph.
| Initial graph | Anomalous cluster (bold edges) |
|---|---|
 |
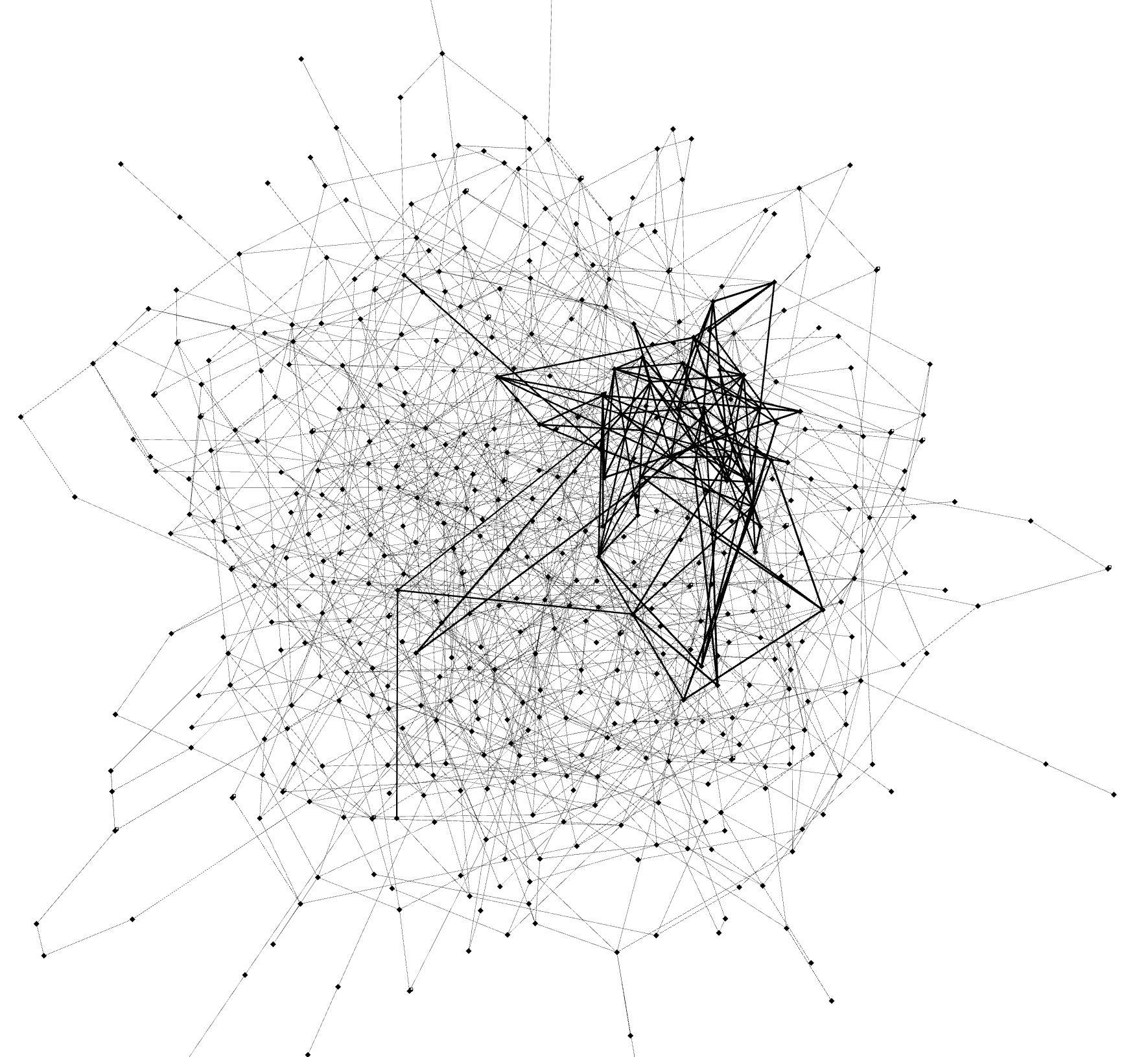 |
If you need a scalable version and more efficient implementation, use the following code.
To run the code, you will need to pre-process Wikipedia pagedumps and pagecounts. To do that, follow the instructions.
Once you have pre-processed the dumps, you can run the algorithm using spark-submit from the sparkwiki repository that you've used for dumps pre-processing. See an example of the command below:
spark-submit --class ch.epfl.lts2.wikipedia.PeakFinder --master 'local[*]' --executor-memory 30g --driver-memory 30g --packages org.rogach:scallop_2.11:3.1.5,com.datastax.spark:spark-cassandra-connector_2.11:2.4.0,com.typesafe:config:1.3.3,neo4j-contrib:neo4j-spark-connector:2.4.0-M6,com.github.servicenow.stl4j:stl-decomp-4j:1.0.5,org.apache.commons:commons-math3:3.6.1,org.scalanlp:breeze_2.11:1.0 target/scala-2.11/sparkwiki_<VERSION OF SPARKWIKI>.jar --config config/peakfinder.conf --language en --parquetPagecounts --parquetPagecountPath <PATH TO THE OUTPUT OF PagecountProcessor> --outputPath <PATH WHERE YOU'LL HAVE RESULTING GRAPHS WITH ANOMALIES>
Parameters explained:
spark-submit
--class ch.epfl.lts2.wikipedia.PeakFinder
--master 'local[*]' [use all available cores]
--executor-memory [amount of RAM allocated for executor (30% of available RAM)]
--driver-memory [amount of RAM allocated for driver (40% of available RAM)]
--packages org.rogach:scallop_2.11:3.1.5,
com.datastax.spark:spark-cassandra-connector_2.11:2.4.0,
com.typesafe:config:1.3.3,
neo4j-contrib:neo4j-spark-connector:2.4.0-M6,
com.github.servicenow.stl4j:stl-decomp-4j:1.0.5,
org.apache.commons:commons-math3:3.6.1,
org.scalanlp:breeze_2.11:1.0 target/scala-2.11/sparkwiki_<VERSION OF SPARKWIKI>.jar
--config [path to config file where you specify parameters of the algorithm]
--language [language code. You can choose any language code but you should have a graph of a corresponding language edition of Wikipedia]
--parquetPagecounts
--parquetPagecountPath [path to the output files of ch.epfl.lts2.wikipedia.PagecountProcessor]
--outputPath [output path where you will have your graphs with anomalous pages]