This guide will show how and why cities can convert MDS trip data to anonymized open data, while respecting rider privacy. This method is being used in Louisville's public dockless open trip data and uses MySQL queries only. It bins data in both space and time.
- Points to Consider
- Example Geographic Data Outcomes
- Data Processing
- Final format of Open Data
- Anonymization Deep Dive
- Cities with Dockless Trip Open Data
- References
- Feedback
We welcome feedback on this method of publishing. We want to preserve rider privacy while being transparent with our methods and the data we collect.
- Cities need to be transparent with the kinds of data we and private companies collect on residents. Publishing a subset of this data helps with this goal.
- The trip data in its raw form is considered highly sensitive. The data potentially contains PII if merged with other data sources/information and since it anonymously tracks use of transportation devices in space and time. This is why we process the data before releasing. Cities collect information that can include PII as required to provide services to residents, and similar processing is done before releasing this publicly. Examples include crime report, permit, property, health, transit, fire, salary, HR, fee, tax, violation, ticket, citation, business registration, car crash, bikeshare, financial, 311, and 911 data.
- The data cities receive does not include traditional PII or any other information about the rider like name, home/billing address, credit card number, cell phone number, email address, birthdate, sex, drivers license info, height, weight, or trip history. Only the dockless vehicle companies have that information and can connect it to each trips.
- Sharing a subset of this data is required in many jurisdictions by open records laws, local policy, state law, and federal law, so defining the details of what to share is important. There are typically exceptions for personally identifiable information, trade secrets of companies, and sensitive data which this method should account for.
- When publishing open data in this form, talk to your mobility service provider and third party aggregators to ensure the resulting data is accurate.
- Cities need to balance transparency requirements and open records laws with privacy best practices.
Note this is not legal advice, but considerations from Louisville's perspective.
Starting with the raw location data (red), we will use binning and k-anonymity to fuzz the locations, while still providing useful, granular data (green) to comply with local, state, and federal open records laws.
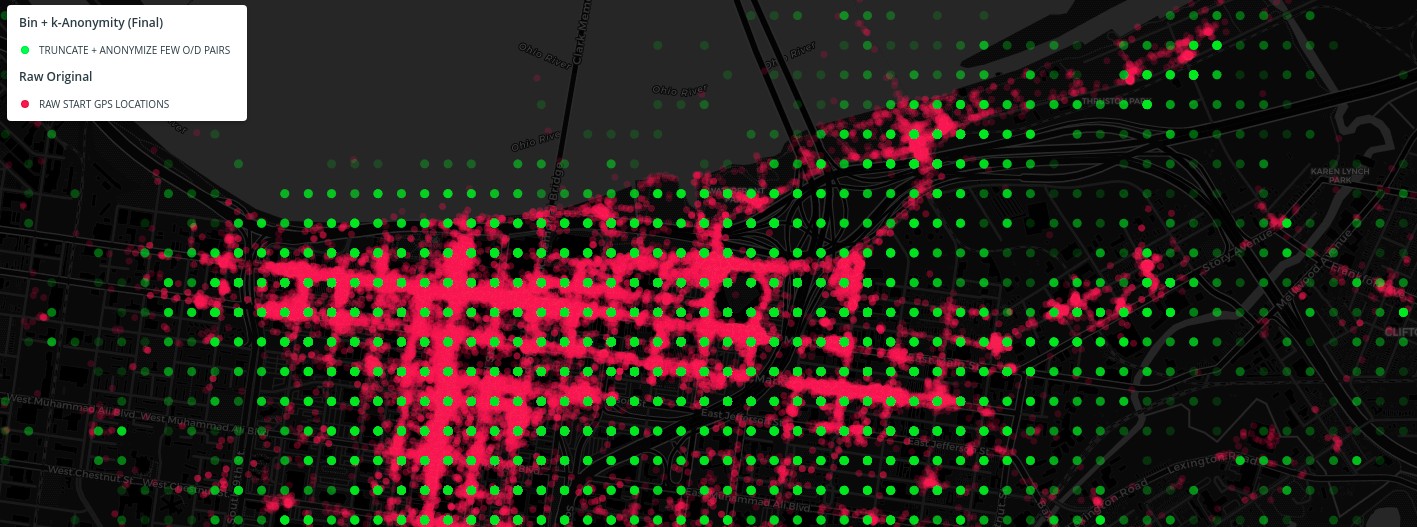
This image shows 100,000 dockless vehicle trip starting points (in red) from one provider selected randomly from raw Louisville data, and zoomed into downtown for detail. After we bin the location to about 100 meters, we then use a k-anonymity generalization method to arrive at the final open data (point grid in green).
The first thing we do to the raw data is bin the start and end location timestamps into 15 minute increments. This temporal resolution reduction helps with data anonymization. Note that we store times in our city's local time. We also are using ISO 8601 to be clear you should be accounting for timezones and Daylight Saving Time in your local area.
The raw start/end data comes to us through MDS as GPS points. Note some have inherent GPS error already, as can be seen by points in the Ohio River to the north. We use this data internally for policy compliance, planning, complaint resolution, parking compliance, and equitable distribution checks.

The first thing we do is simply truncate the latitude and longitude to 3 decimal places, which clearly bins the starting and ending locations into a grid that is about 100 meters tall and 80 meters wide at this location (Louisville) on the planet. This effectively creates a spatial histogram of rectangular tessellation across the city -- instead of displaying this as points, you could show the data as weighted rectangles.

Next, we run those binned locations through a k-anonymity generalization function. If there are 4 or less origin/destination pairs to/from the same location then we move both the start and end points further. In the Louisville data, this is about one third of all the trips. We randomly move the locations in a 400 meter radius, which is up to 5 binning locations away in any direction.
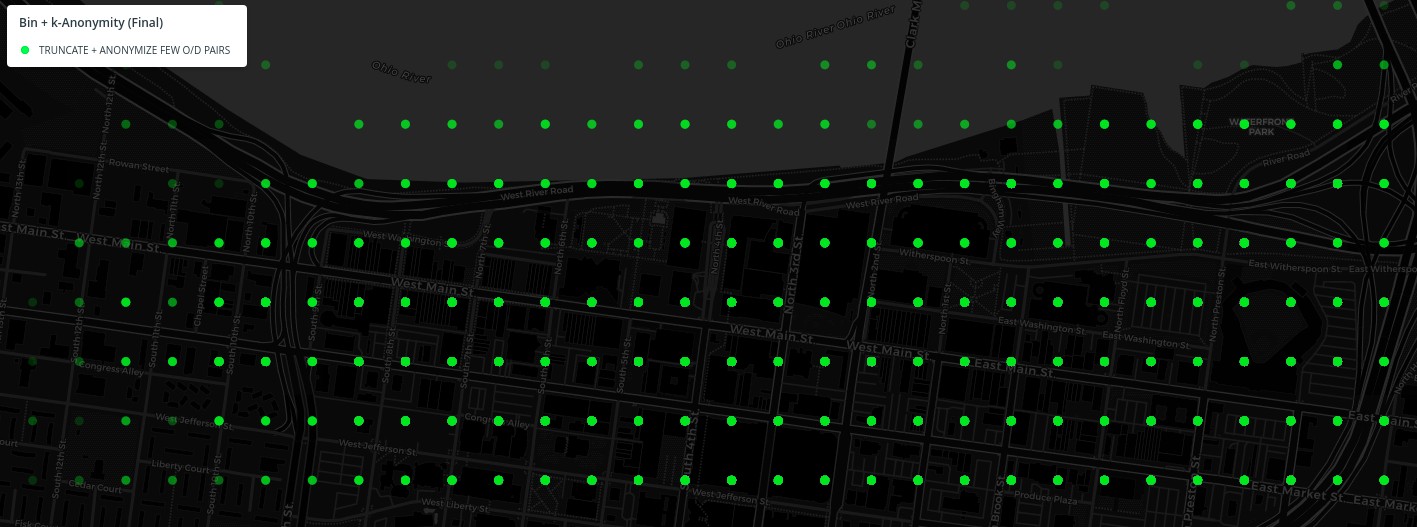
Note how the points here are more spread out than with the step 2 binning alone. See this online code sample and article about Disk Point Picking for more details.
In the end we have a grid of points, and the person looking at the data cannot trace a location back to its original location. Also, there is no way to tell if a point has been both fuzzed and binned, or only binned.
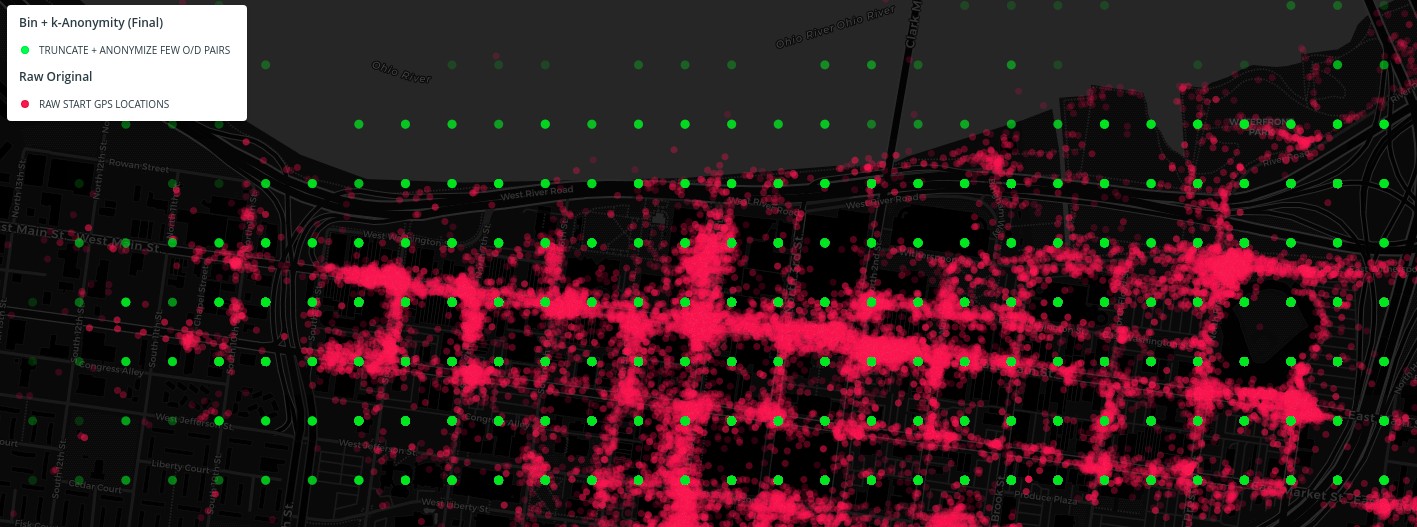
Effectively, this means each point could be up to 1,600+ meters away from its actual location, while the integrity of the data is still reasonably maintained for analysis. See the "Anonymization Deep Dive" section below for more details.
Note image colors have been checked to be accessible to color blind individuals. Please let us know if you experience any difficulties.
Take a look at this 100,000 point data sample and 4 different layers on an interactive map.
Note this only includes the location samples needed to make the example visuals in this document, not the final open data. The raw data layer is not downloadable (only visible on the map) and only includes start location, not the end location, or any time/date information, or any trip information (trip line, end point, distance, duration).
This methodology will bin origin and destination data in both space and time. These are the technical steps to processing from MDS to open data using MySQL. Note you can adapt this to MS SQL or PostGis with changes to some of the function names.
Using your city's Dockless Vehicle Policy data sharing and enforcement requirements, obtain authentication with each operator's MDS feed for your city.
Ingestion method from MDS is left as an exercise for the reader. Securely store a subset (we do not store trip line data within the city network and only access that from the MDS source APIs when needed) of the raw MDS data and provide only authorized, audited, secure access to the location. Open source code, tools, or third party options may be added here at a later date.
This is the table structure for the DocklessOpenData open data table that you will be converting your data to:
CREATE TABLE `DocklessOpenData` (
`TripID` varchar(50) NOT NULL,
`StartDate` varchar(20) DEFAULT NULL,
`StartTime` varchar(20) DEFAULT NULL,
`EndDate` varchar(20) DEFAULT NULL,
`EndTime` varchar(20) DEFAULT NULL,
`TripDuration` float DEFAULT NULL,
`TripDistance` float DEFAULT NULL,
`StartLatitude` float DEFAULT NULL,
`StartLongitude` float DEFAULT NULL,
`EndLatitude` float DEFAULT NULL,
`EndLongitude` float DEFAULT NULL,
`DayOfWeek` varchar(45) DEFAULT NULL,
`HourNum` varchar(45) DEFAULT NULL,
`Fuzzed` tinyint(4) DEFAULT '0',
`StartLat` float DEFAULT NULL,
`StartLon` float DEFAULT NULL,
`EndLat` float DEFAULT NULL,
`EndLon` float DEFAULT NULL,
PRIMARY KEY (`TripID`),
KEY `idx_DocklessOpenData_StartLat` (`StartLat`),
KEY `idx_DocklessOpenData_StartLon` (`StartLon`),
KEY `idx_DocklessOpenData_EndLat` (`EndLat`),
KEY `idx_DocklessOpenData_EndLon` (`EndLon`),
KEY `idx_DocklessOpenData_Fuzzed` (`Fuzzed`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
Note the use of varchars, because not all company MDS feeds have reliable/complete data in the right format.
The last 5 columns are used just for anonymizing the data later, in step 4 below.
Note no trip line/polyline data is being stored, and no provider information.
When inserting from MDS into DocklessOpenData, use the following SQL for formatting values:
TripID = insert(insert(insert(insert(md5(sha2(source.OriginalTripID, '256')),9,1,'-'),14,1,'-'),19,1,'-'),24,1,'-')
-- creates a new uniform trip UUID from the original. This is a one-way function based on the source Trip UUID.
-- There may be a better way to do this, but we wanted to not generate a new UUID each time
-- and instead wanted it to be reproducible based on source data.
-- round start and end locations to 3 decimal places
StartLatitude = ROUND(source.OriginalStartLatitude, 3)
StartLongitude = ROUND(source.OriginalStartLongitude, 3)
EndLatitude = ROUND(source.OriginalEndLatitude, 3)
EndLongitude = ROUND(source.OriginalEndLongitude, 3)
StartDate = STR_TO_DATE(source.OriginalStartDateTime, '%Y-%m-%d')
EndDate = STR_TO_DATE(source.OriginalEndDateTime, '%Y-%m-%d')
StartTime = LEFT(SEC_TO_TIME(FLOOR((TIME_TO_SEC(source.OriginalStartDateTime) + 450) / 900) * 900), 5)
-- bins to 15 minute increments
EndTime = LEFT(SEC_TO_TIME(FLOOR((TIME_TO_SEC(source.OriginalEndDateTime) + 450) / 900) * 900), 5)
-- bins to 15 minute increments
TripDuration = Round( ( UNIX_TIMESTAMP(source.OriginalEndDateTime) - UNIX_TIMESTAMP(source.OriginalStartDateTime) ) /60 )
-- rounded to nearest minute
This removes distance outliers and populates day of week and hour of day fields.
Update
DocklessOpenData o
Set
o.DayOfWeek = dayofweek(o.StartDate),
o.HourNum = left(o.StartTime, 2),
o.TripDistance = -1 where o.TripDistance < 0,
o.TripDistance = 100 where o.TripDistance > 100;
If there are not many trips between a starting location even after binning to 3 decimal places in step 2, then we anonymize further to protect privacy of individual riders. This common practice is called "k-anonymity".
In our case, we look for O/D pairs of less than 5. That is, where there are less than 5 trips made between any combination of 2 aggregated start and end trip areas across the city. If there are, then we randomly move those points in a larger radius from the original location. The radius here is about 400 meters in a random direction, which is a k-anonymity generalization method.
In the final data there is no way to know which trips have been anonymized in this way, and which trips are only aggreggated to the block level without further anonymization.
To do this with only SQL, we use the column called 'Fuzzed' which tracks what O/D pairs need to be fuzzed, and which ones have then been fuzzed with a stored procedure. There are also 4 columns for lat/lon start/end coordinates, that are the original values before fuzzing.
Technical Details
The formula in the procedure below moves the location to an evenly distributed location (not clustered around the center) within a defined circle. See this online code sample and article about Disk Point Picking formulas for more details.
-- 1 clear fuzz list
update mobility.DocklessOpenData set Fuzzed = 0;
-- 2 reset initial/fill new lat/lons into fuzzed latitude/longitude columns
Update DocklessOpenData o
Set
o.StartLatitude = o.StartLat, o.StartLongitude = o.StartLon, o.EndLatitude = o.EndLat, o.EndLongitude = o.EndLon;
-- 3 update Fuzzed for OD pairs of 4 or less.
update mobility.DocklessOpenData d set d.Fuzzed = 1 where d.TripID in
(SELECT * FROM (
SELECT o.TripID as TripID
FROM mobility.DocklessOpenData o
group by o.StartLat, o.StartLon, o.EndLat, o.EndLon
having count(o.TripID) <= 4
order by count(o.TripID) desc
) tblTmp)
;
For the final step, we need to run a stored procedure. You can create that procedure running this code one time:
DELIMITER $$
CREATE DEFINER=`root`@`localhost` PROCEDURE `FuzzOpenData`()
BEGIN
DECLARE randA FLOAT DEFAULT 0;
DECLARE randB FLOAT DEFAULT 0;
DECLARE n INT DEFAULT 0;
DECLARE i INT DEFAULT 0;
SELECT COUNT(*) FROM DocklessOpenData where Fuzzed = 1 INTO n;
SET i=0;
WHILE i<n DO
SET @randA = rand();
SET @randB = rand();
update DocklessOpenData
set
StartLatitude = truncate(@randB * .004 * cos( 2*pi() * @randA / @randB ) + StartLat, 3),
StartLongitude = truncate(@randB * .005 * sin( 2*pi() * @randA / @randB ) + StartLon, 3),
EndLatitude = truncate(@randB * .004 * cos( 2*pi() * @randA / @randB ) + EndLat, 3),
EndLongitude = truncate(@randB * .005 * sin( 2*pi() * @randA / @randB ) + EndLon, 3),
Fuzzed = 2
where Fuzzed = 1
limit 1;
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
Once this procedure is created, you can just run the procedure with this SQL upon each data update.
-- 4 update to be fuzzed values by moving randomly within a radius
call `FuzzOpenData`();
We used a k value of 4 for Louisville. You can increase this for your city if you'd like, which will increase the number of anonymized trips, which may be required to increase rider privacy based on your city's geographic size and trip counts.
Note the .004 and .005 multipliers are to adjust the radius for the height and width difference at the latitude and longitude at the Louisville, KY latitude. You may want to adjust these for your location.
Export and post in CSV format just the following fields from the open data table. Note we are not including the last five fields that were used in the k-anonymity step 4 above.
- TripID - a unique ID created by city
- StartDate - in YYYY-MM-DD format (ISO 8601)
- StartTime - rounded to the nearest 15 minutes in HH:MM format (ISO 8601)
- EndDate - in YYYY-MM-DD format (ISO 8601)
- EndTime - rounded to the nearest 15 minutes in HH:MM format (ISO 8601)
- TripDuration - duration of the trip minutes
- TripDistance - distance of trip in miles - company provides this data, it is not calculated from trip lines
- StartLatitude - rounded to nearest 3 decimal places (between 1-100 meters)
- StartLongitude - rounded to nearest 3 decimal places (between 1-80 meters)
- EndLatitude - rounded to nearest 3 decimal places
- EndLongitude - rounded to nearest 3 decimal places
- DayOfWeek - 1-7 based on date, 1 = Sunday through 7 = Saturday, useful for analysis
- HourNum - the hour part of the time from 0-24 of the StartTime, useful for analysis
See a sample CSV file of this data in this repo: DocklessOpenData-Sample-Aug2019-Louisville.csv
Because each origin and destination location point in the data has a chance (about 35% in Louisville) to be randomized using a k-anonymity generalization method, and you don't know which points have been moved using this method, this means each point could be up to 1,600+ meters away from its actual location, while the integrity of the data is still reasonably maintained for analysis.
Let's take a look at how this k-anonymity works with a specific example.
Here is an example of the original start and end points of a single trip taken across the city, after truncating to 3 latitude/longitude decimal places (which is anywhere from 1 to 100 meters away from the initial raw location data points).
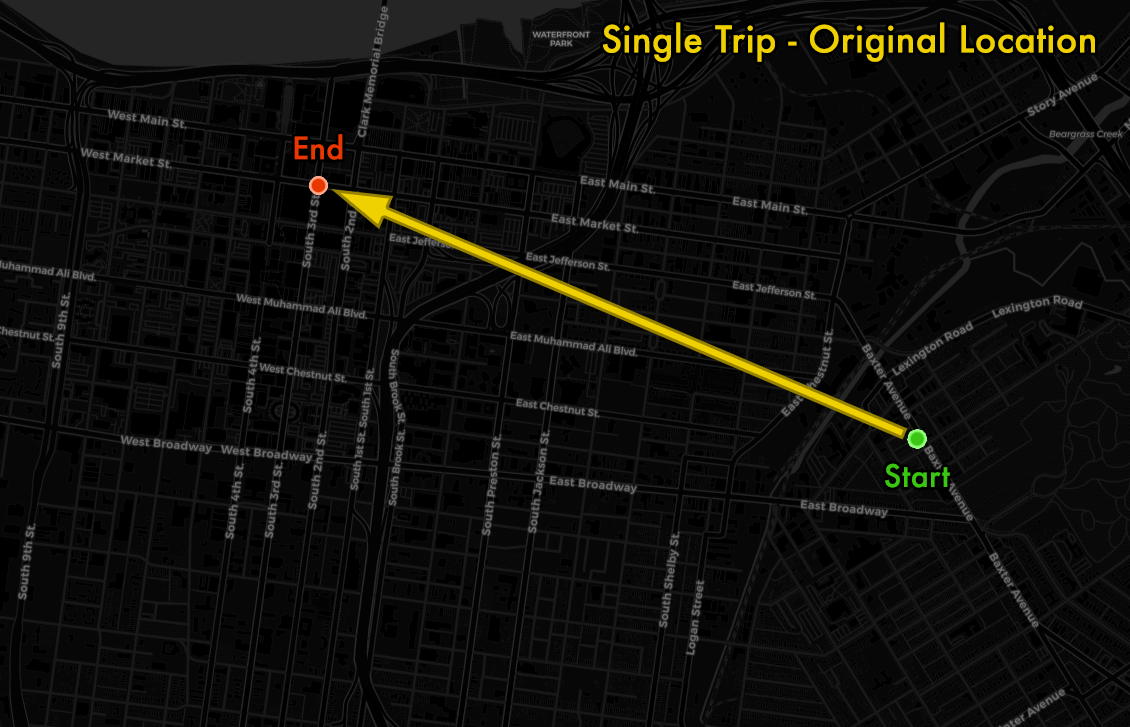
The binned origin destination trip pair has 4 or less trips between them, so we need to use k-anonymity and move the points in a random direction within a radius. The new points can fall anywhere within an 800 meter circle.
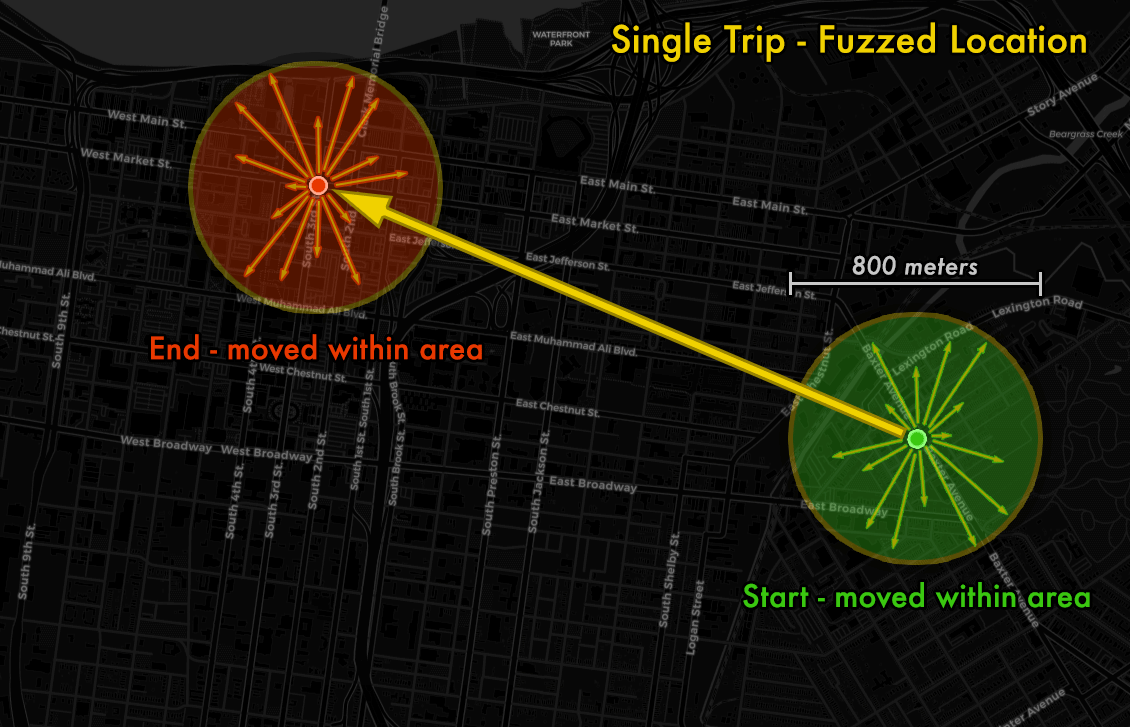
Here's an example showing the 2 points moving into a random area of each circle.
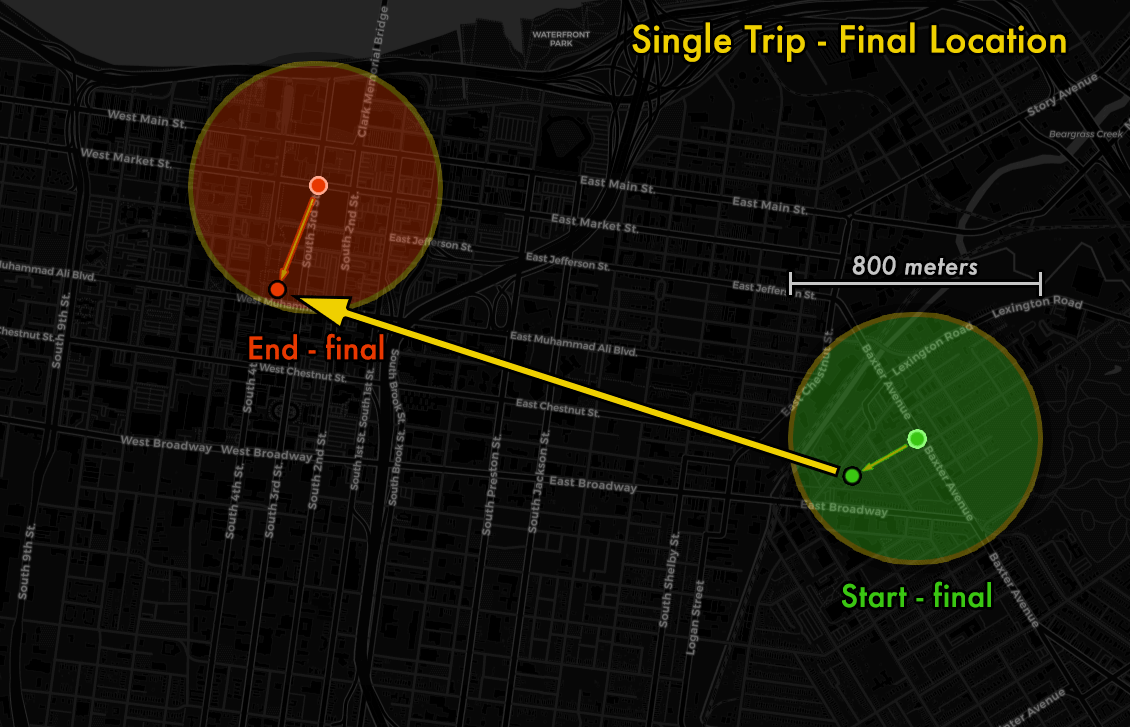
In the final published data, this is the start and end point location provided.
Since someone looking at the open data does not know which points have been moved from which nearby area, the final points could have come from a radius of up to 400 meters in any direction. This means each data point could have actually originated from anywhere within a 800 meter diameter circle, i.e. half a mile.
- Louisville, KY (3 decimal places lat/lon, 15 min time increments, outliers cleaned, k-anonymity of <5 O/D pairs fuzzed more)
- Kansas City, MO Uses this method except for k-anonymity step (3 decimal places lat/lon, 15 min time increments, outliers cleaned)
- Austin, TX (aligned to census tracts, outliers cleaned)
- Minneapolis, MN (aligned to line segments, outliers cleaned)
- Chicago, IL (grouped by community area, 1 hour time increments)
- Calgary, Alberta, Canada (1 hour time and hexagonal spacial binning)
These publications were used when developing these open data publishing methodology, specifically the 3 decimal place latitude and longitude truncation. Additionally, we added time binning, outlier cleaning, and k-anonymity generalizations.
We welcome any thoughts and feedback you have with this data anonymization method. Please open an issue to discuss publicly, or contact us through our open data website contact form. And let us know if you are using this, some variation of this, or a different method for publishing your city's dockless data as open data or for open records requests.
Methodology developed, implemented, and documented by Michael Schnuerle, Louisville's Chief Data Officer.