Home
Ahmia is a free search engine software for Tor hidden service websites. You can test the running search engine at ahmia.fi.
Building a search engine for anonymous web sites running inside the Tor network is an interesting problem to solve. Tor enables web servers to hide their location and Tor users can connect to these authenticated hidden services while the server and the user both stay anonymous. However, finding web content is laborious without a good search engine and therefore a search engine is needed for the Tor network.
Servers configured to receive inbound connections through Tor are called hidden services (HSs): rather than revealing the real IP address of the server, a hidden service (HS) is accessed through the Tor network by mean of a virtual top level domain .onion.
As a result, the published content is diverse. Undoubtedly, some HSs are sharing pictures of child abuse, or operate as marketplaces for illegal drugs, including the widely known black market Silk Road. These few services are obviously controversial and often pointed out by critics of Tor and anonymity. On the other hand, vast number of HSs are devoted to human rights, freedom of speech, and information prohibited by oppressive governments.
However, finding content published using hidden service websites is laborious without a search engine. Tor technology is designed to offer a way to register .onion domains and to get anonymous TCP connections while it lacks a method to search the actual content. Obviously this is a problem of the applications layer and Tor is operating on the transport layer. Furthermore, even though the WWW is designed for information sharing it lacks a built-in mechanism to search the published information.
Web search engines are needed to make the web content findable. Because there were no search engines to search web content published using Tor we decided to build our own search engine specially for Tor. The author registered ahmia.fi and started development of a Tor search engine as a side project in 2010. This development included programming own crawlers, testing open source crawlers, solving how to find HSs because Tor technology does not offer a list of them, learning about the Tor community, and implementing a filtering policy. Moreover, the author has implemented an API that empowers other Tor services that publish content to integrate with Ahmia.
As a result, ahmia is a working search engine for indexing, searching and cataloging content published inside the Tor network. Furthermore, it is an environment to share meaningful statistics, insights and news about the Tor network itself.
In this chapter we are giving an overview of the technical design of ahmia.fi. We will explain our .onion domain gathering methods, crawling solutions, back-end system, API and security solutions. Moreover, we are showing how our child abuse filtering policy works and how our filtering solutions are published, shared and used by other services such as TorSearch.es and Tor2web servers.
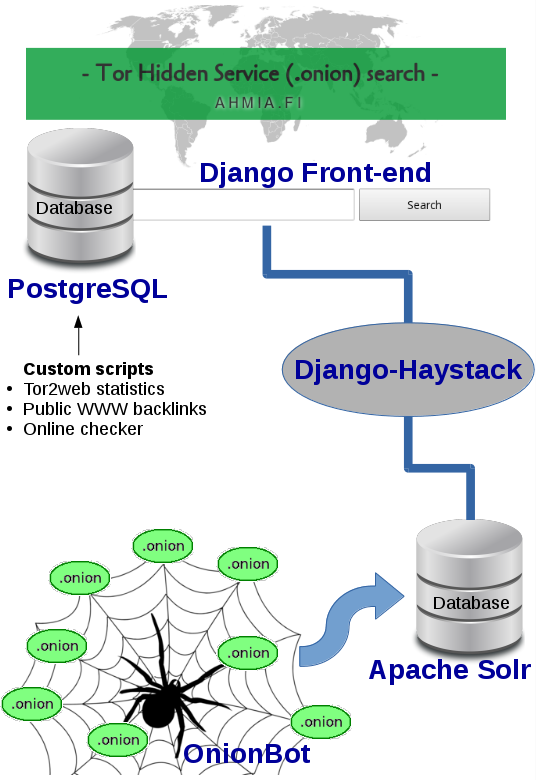
Ahmia web service is written using Django web framework. As a result, the server-side language is Python. In the client-side, most of the pages are plain HTML pages. There are some pages that require JavaScript, but the search itself works without client-side JavaScript.
- Django front-end
- PostgreSQL database
- Custom scripts to download data about hidden services
- Django-Haystack connection to Solr
- Apache Solr
- Onionbot crawler that gathers data to Solr database
See installation and developing tutorial
The full-text search is implemented using Django-Haystack. The data is saved to Apache Solr.
OnionDir is a link list of the known hidden service websites that are online. Separate script gathers this list and fetches information fields from the HTML (title, keywords, description etc.). Furthermore, users can freely edit these fields.
Moreover, the website admins can share their official information to this index using description.json proposal.
As a result, this information is shown in the OnionDir page.
We are gathering statistics from the hidden services. As a result, we can represent and share meaningful data about hidden services and visualize it.
We are gathering three type of popularity data:
- Tor2web nodes share their visiting statistics to Ahmia
- Number of clicks in the search results
- Number of public WWW backlinks to hidden services
We have decided to filter child abuse from our search results. Ahmia is removing everything related to these websites. These websites may not be actual child porn sites. They are rather sites where users can post content (forums, file and image uploads etc.) and as the result there have been, momentarily at least, some suspicious content that has not been moderated in a reasonable period of time. Ahmia.fi does not have the time to monitor these sites carefully and we are banning sites from our public index if we see any evidence of child abuse. Of course, the ban is removed if the site itself contacts us and we review the website to be OK.
In practice, we are calculating the MD5 sum from the banned domains and use it as a filtering policy. Moreover, we are sharing this list and Tor2web nodes can use the list to filter out pages.
OnionBot is a crawler for .onion websites. It is crawling the Tor network and passing data to search database. It is based on Scrapy framework. OnionBot requires Tor software (using Tor2web mode), Polipo, and the data is saved to Apache Solr.
Also, you can download only front pages
scrapy crawl OnionSpider -s DEPTH_LIMIT=1 -s MAX_PER_DOMAIN=9999999 -s FRESH_INTERVAL=-1
Or download everything
scrapy crawl OnionSpider -s MAX_PER_DOMAIN=9999999 -s FRESH_INTERVAL=-1
Apache Solr is a popular, open source enterprise search platform. Its major features include powerful full-text search, hit highlighting, faceted search, and near real-time indexing.
The schema.xml file contains all of the details about which fields your documents can contain, and how those fields should be dealt with when adding documents to the index, or when querying those fields.
You should delete old crawling results
curl "http://localhost:33433/solr/update?commit=true" -H "Content-Type: text/xml" --data-binary "date_inserted:[* TO NOW-14DAYS]"
Or delete some domain
curl "http://localhost:33433/solr/update?commit=true" -H "Content-Type: text/xml" --data-binary "domain:SOMEDOMAIN"
In the software
- We do not log any IP addresses, see Apache configuration
- We are gathering real-time clicks, however, this data is not shown accurately
In the host ahmia.fi
- Back-end servers are run separately and they do not have any knowledge about the end-users
- All the servers are in the countries with strong privacy laws, for example, Finland and the Netherlands
- Communication between servers is encrypted
- Only few trustworthy people know the locations of the back-end servers and are able to access them