Este projeto tem como objetivo avaliar e aplicar técnicas do estado da arte para Web Crawler e extração de conteúdos em páginas Web no contexto da automatização na avaliação de portais de transparência municipais do estado da Paraíba.
Em cada portal de transparência é verificado a presença ou ausência de critérios fiscais como Despesas, Receitas, Licitações e Folha de Pagamento, utilizando com diretriz para a avaliação o Índice de transparência Municipal.
A grande diversidade na forma de navegar e visualizar as informações fiscais nesses sites torna o processo de avaliação automatizada da transparência uma tarefa não trivial, exigindo técnicas robustas a mudanças de layout, as diferentes estruturas Web e ao custo de tempo e processamento.
O mecanismo de fiscalização proposto neste trabalho objetiva estimular as entidades municipais a divulgarem em seus portais de transparência suas informações fiscais de forma acessível a qualquer público.
- Critério: Conjunto de itens fiscais que representam um conceito fiscal como, por exemplo, Despesa Orçamentária, Despesa Extra-Orçamentá, Receita Orçamentária e etc;
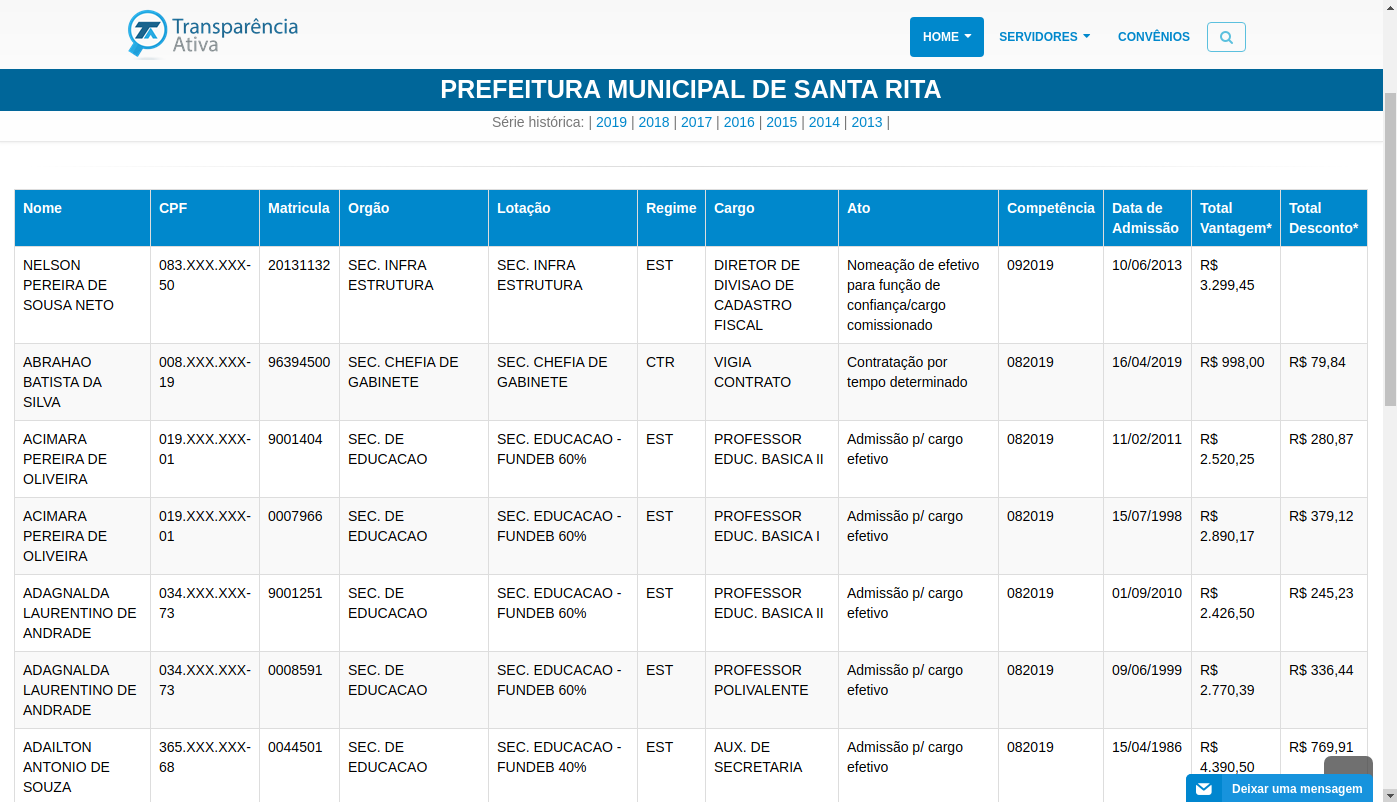
- Item: São atributos que formam o critério, por exemplo os itens nome, salário, cpf e tipo do cargo fazem parte do critério Quadro Pessoa. Abaixo é apresentado um exemplo de itens de quadro pessoal do município de Santa Rita PB:
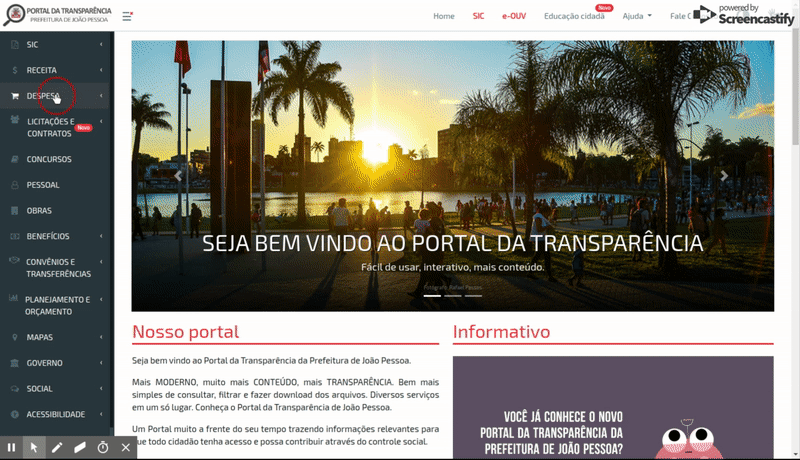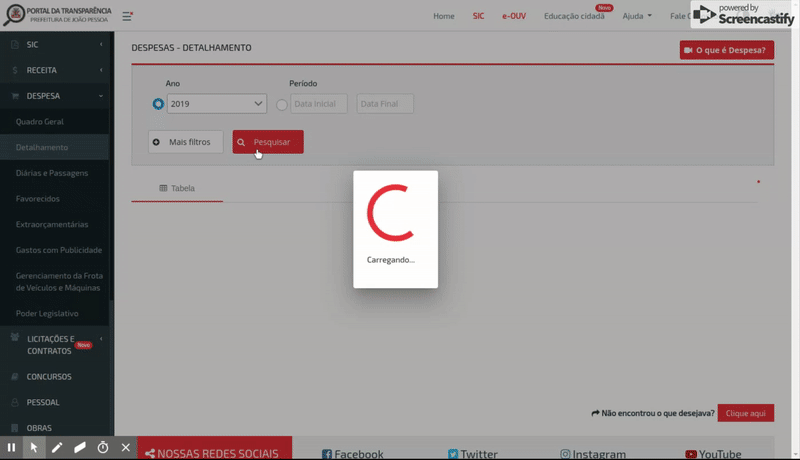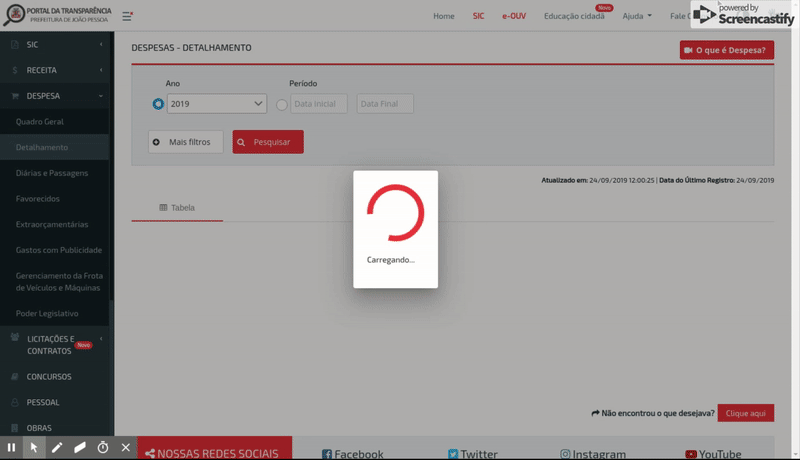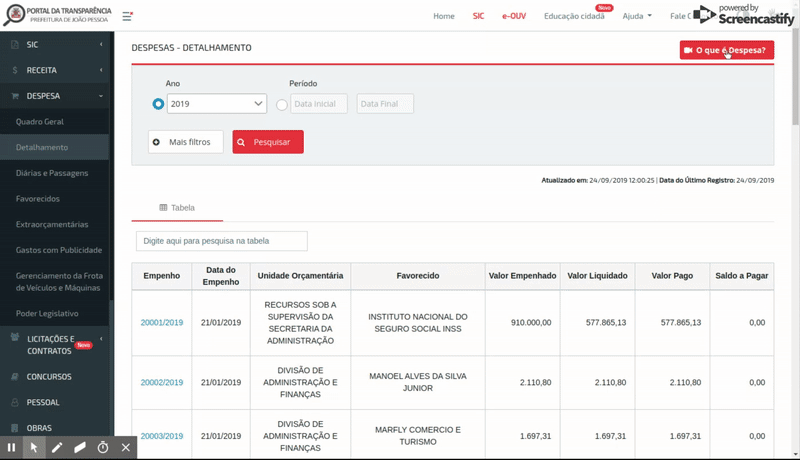
- Componentes dinâmicos: São elementos HTML que não possuem a propriedade Href com uma url válida, mas que são interagíveis nas páginas Web como buttons, div, span e etc. Abaixo é apresentado um fluxo de acesso ao critério Despesa Orçamentária com interações em componentes dinâmicos clicáveis:
- Nó ou Node: São representações unificadas de URLs ou componentes dinâmicos clicáveis que consideram o mapeamento de sites em forma de árvores.
- Lidar com a grande diversidade e a falta de padronização na forma criar URLs, no modo de navegação e na maneira de disponibilizar e visualizar as informações fiscais nos sites de transparência W3C;
- Gerenciar o processamento e acesso componentes dinâmicos;
- Gerenciar sessões temporárias em portais de empresas que atendem mais de um município no mesmo domínio;
- Lidar com a grande variação entre termos de acesso e identificação dos critérios nos portais
Para o melhor entendimento das técnicas utilizadas neste estudo, é necessário compreender alguns passos que precedem a varredura dos portais de transparência. Desta forma, a Figura abaixo apresenta com detalhes cada fase do fluxo de pré-processamento.
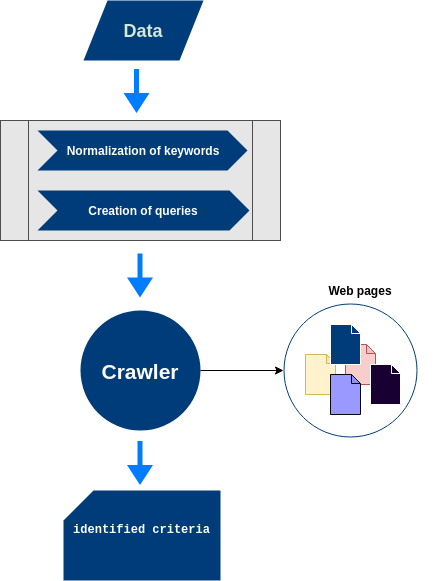
São Coleções contendo metadados dos municípios da Paraíba, por exemplo Url do portal de transparência, prefeitura e palavras chaves de busca e identificação dos critérios.
- Palavras chaves de busca : Refere-se a termos utilizados para identificar urls e elementos dinâmicos clicáveis (button, input, a e etc.) que darão acesso à novas páginas/áreas relevantes considerando o critério de transparência buscado. Um exemplo de palavras de busca é a coleção apresentada abaixo, que expõe os termos para buscar Despesa Orçamentária nas páginas:
['despesas extras-orcamentarias', 'Consultar Despesas Extras-Orçamentárias','Consultar Despesas Extras','despesaextraorcamentaria.aspx','despesasextras', 'despesas', 'despesa com diarias', 'detalhamentos das despesas', 'consultar', 'pesquisar'];
- Palavras chaves de identificação : Refere-se a termos utilizados para identificar os itens pertecentes ao critério buscado. Em cada nova página/área é verificada a existência dos termos chaves para cada uns dos itens. Abaixo e mostrado um exemplo de termos utilizados na identificação do critério Despesa Extra Orçamentária.
{
"valor": ['valor', 'empenhado(r$)'],
"codigo": ['codigo', 'cod. despesa'],
"nomenclatura": ['descricao', 'nome da despesa'],
};
- Metadados dos municípios da Paraíba: Refere-se a informações básicas dos municípios como, por exemplo, a URL da prefeitura, a URL do portal da transparência e a empresa(s) fonecedora(s) do portal transparência. Um exemplo dos metadados dos municípios é apresentado abaixo (complete file):
{
name: 'Campina Grande',
codSepro: '1981',
empresas: [PUBLICSOFT, ALFA_CONSULTORIA],
cityHallUrl: 'http://campinagrande.pb.gov.br',
transparencyPortalUrl: 'http://transparencia.campinagrande.pb.gov.br',
population: 0
}
Para inserção dessas informações em uma base de dados foram criados scripts de dados. Estes podem ser encontrados no diretório data do projeto.
Na seção de Running deste documento é mostrado como atualizar e remover os termos chaves de busca e identificação.
Na etapa de normalização das palavras chaves todos os termos de busca e identificação são normalizados, sendo removidos acentos, espaços em branco e convertendo todas as palavras em letras minúsculas (lowercase). Este processo tem como propósito expandir a cobertura dos termos durante as buscas nos sites. Por exemplo o termo Depesa extra-Orçamentária é transformado em despesa extra orcamentaria.
Nesta etapa com base nos termos chaves de busca e identificação são criadas consultas utilizando a linguagem XPath (XML Path Language), objetivando buscar URLs, componentes dinâmicos e identificar os critérios fiscais nos portais de transparência.
Um dos desafios desse processo é fornecer consultas que possam ser reutilizadas em buscas por critérios fiscais em todas as páginas. Para isso, por meio de um estudo empírico foi optado pela construção de consultas com o foco principal nos termos de buscas sem o uso de atributos específicos de cada site como classes css e ids de elementos html.
Além disso, foram analisadas novas formas de expandir a cobertura dos termos nas páginas web através dos xpaths, neste cenário a sintaxe deve conseguir intepretar as palavras normalizadas (etapa mostrada anteriormente) para identificar termos que contenham o mesmo sentido e possuam diferentes grafias, por exemplo palavras case sensitive ou acentuadas. Neste contexto, novas versões do Xpath (2 á 3) trazem algumas funções úteis para normalização que permitem por exemplo a transformação dos textos das páginas em lowercase e uppercase de forma nativa, porém a maioria das linguagens e ferramentas como o próprio Puppeteer ainda adotam como principal especificação na implementação o Xpath 1.0, ao qual não oferece suporte a qualquer tipo de normalização nativa dos xpaths
Como forma de reduzir o impacto da falta de suporte aos termos normalizados pelas consultas, foram criadas manualmente sequências de caracteres que traduzem um caracter para outro às quais são posteriormente aplicadas à função translate do Xpath. Abaixo é mostrado como os caracteres foram traduzidos, por exempo ã foi traduzido para a, ou seja, se na página existir um termo com o caractere ã com um xpath contendo a é possível identificá-lo.
"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ" = "abcdefghijklmnopqrstuvwxyzc"
"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç" = "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"
":-º°" = ""
Dessa forma, utilizando a palavra de busca ou identificação despesa orcamentaria (previamente normalizada pelo processo descrito anteriormente) a função permite mapear o termo para identificar termos na página web como DESPESA-ORÇAMENTÁRIA, DESPESA ORÇAMENTÁRIA, despesa orçamentária e etc.
Durante a elaboração dos xpaths 3 tipos de consultas são criadas as para buscar URLs, para buscar componentes dinâmicos clicáveis e para identificar os itens do critério buscado.
No que refere a busca por urls, os xpaths são criados para cada termo individuamente, onde são consideradas todas tags HTML (representado por //* na consulta) que contenham o atributo href nas buscas. Um exemplo deste tipo de xpath é apresentado abaixo:
//*[contains(translate(translate(translate(normalize-space(@href),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extra orcamentaria")]/@href
Da mesma forma os xpaths de busca por componentes dinâmicos clicáveis são criados para cada termo individualmente, aplicando-o em diversas tags e atributos considerados relevantes na descoberta deste tipo de componente durante um conjunto de observações nas estruturas HTML dos sites. Abaixo é exposto uma exemplificação deste tipo de xpath:
//div[contains(translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")]/following::a[1] | //button[contains(translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //input[contains(translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //input[contains(translate(translate(translate(normalize-space(@value),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //a[contains(translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //input[contains(translate(translate(translate(normalize-space(@onclick),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //input[contains(translate(translate(translate(normalize-space(@id),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //a[contains(translate(translate(translate(normalize-space(@title),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //a[contains(translate(translate(translate(normalize-space(@onclick),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //a[contains(translate(translate(translate(normalize-space(@href),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")] | //*[contains(translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")]/parent::a | //a[contains(translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")]/following::span | //span[contains(translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", ""),"extraorcamentaria")]/parent::*
Com outro objetivo, os xpaths para identificar itens são criados para identificar e retornar textos das página web que representam os itens do critério buscado. Cada item pode ter 1 ou n variações de termos para representá-lo durante a busca. Um exemplo deste tipo de xpath é mostrado abaixo:
//*[translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "valor arrecadado(r$)" or translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "receita arrecadada" or translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "realizada ate o mes" or translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "arrecadada" or translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "arrecadado ate o momento" or translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "arrecadacao de receitas" or translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "valor arrecadado" or translate(translate(translate(normalize-space(text()),"ABCDEFGHIJKLMNOPQRSTUVWXYZÇ", "abcdefghijklmnopqrstuvwxyzc"),"ãáâàÃÁÀÂẽéêèẼÉÈÊõóôòÒÓÔÕĩìíîÌĨÎÍúùûũÚÙŨÛç", "aaaaaaaaeeeeeeeeooooooooiiiiiiiiuuuuuuuuc"),":-º°", "") = "arrecadacao"]
Todos os tipos de xpaths são criados por funções presentes na classe xpathUtil.js existente dentro do módulo util do projeto
Por representar de forma similar as estruturas de links contidas nos Web sites, o Breadth First Search é um dos algoritmos mais utilizados para Web Crawler, onde a partir de um nó inicial os demais nós são acessados numa busca em largura, partindo dos nós mais próximos ao nó inicial para os mais distantes, até que todos os nós sejam pecorridos. Assim, quanto menor o nível do nó mais próximo ele estará do nó inicial (Raiz) e mais rápido ele será acessado. A Figura abaixo mostra um exemplo desse tipo de estrutura, os números representam a ordem que nós deverão ser acessados.
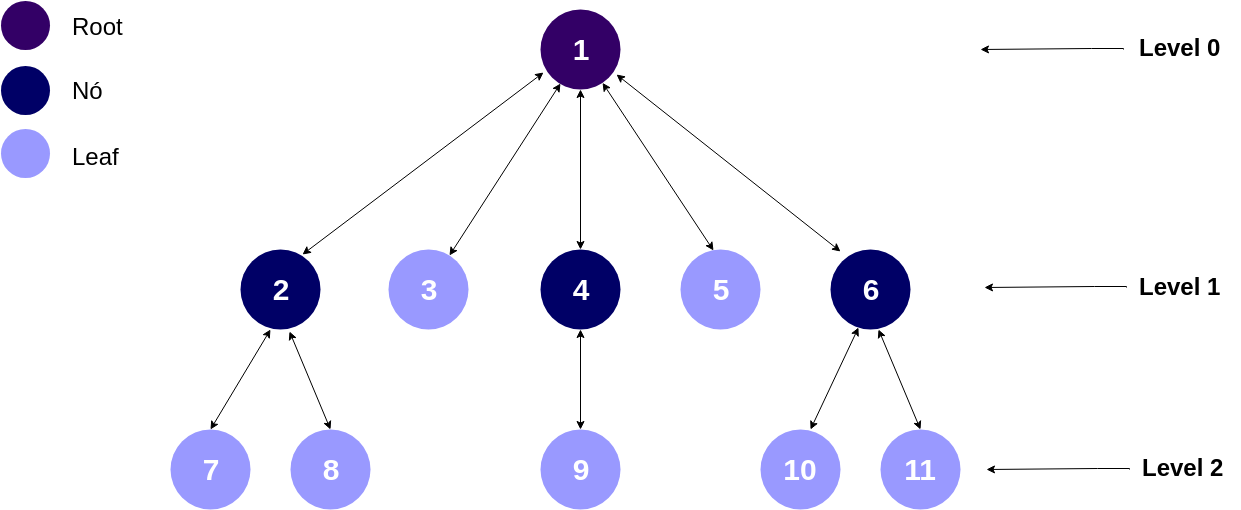
Nesse contexto, para o estudo o BFS será o algoritmo base para percorrer as páginas/áreas em busca dos critérios fiscais nos portais de transparência. Este algoritmo fazerá parte de um Crawler que servirá como modelo base durante os experimentos.
TODO
TODO
Durante a execução do Crawler, a separação do processo de busca e identificação dos critérios nos portais fiscais garante melhores níveis de eficácia, devido a maior distinção das páginas/áreas acessadas por meio dos termos utilizados em cada critério, evitando problemas como a identificação de itens semelhantets em locais pertecentes a outros critérios. Além disso, a idenpendência entre os processos de avaliação dos critérios permite uma parelização entre eles, resultando num melhor aproveitamento dos recursos disponíveis, tornando mais eficiente a execução.
De modo a exemplificar o fluxo de execução do Crawler na avaliação de cada critério a Figura abaixo é prosposta
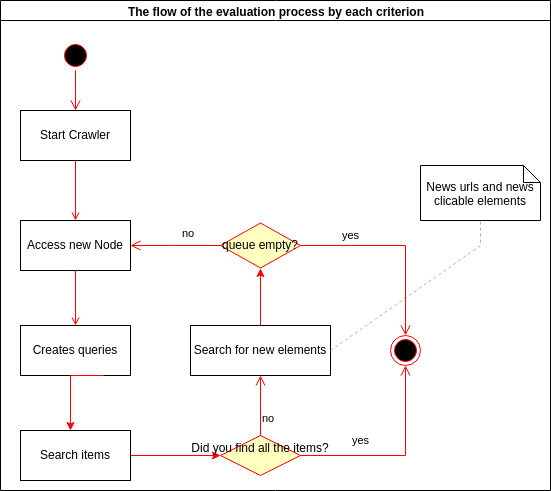
O detalhamento das atividades do diagrama é apresentada abaixo:
-
Start Crawler: Diz respeito ao processo de inicialização do Crawler mostrado na seção Running deste documento. Nesta etapa, a varredura de cada critério é iniciada de forma paralela;
-
Access Node (Access Web page): Esta atividade refere-se ao acesso de um novo nó. Um nó pode ser representado por uma nova URL a ser acessada ou um novo elemento a ser clicado;
-
Create queries: Após a realização da atividade anterior, são criadas consultas para buscar e identificar os itens do critério e encontrar nós filhos (urls e elementos clicáveis);
-
Search items: Com as consultas criadas, os itens do critério avaliado são buscados. Neste processo alguns validações são aplicadas, como por exemplo verificar se o item encontrado está contido está em uma tabela ou uma lista. Caso todos itens buscados forem encontrados o processo de avaliação do critério é finalizado;
-
Search new Nodes: Caso todos os itens não sejam identificados, o crawler prossegue com a atividade de procurar novos nós para serem acessados (nós filhos do nó atual) podendo ser uma URL ou um elemento HTMl clicável. No processo são aplicadas validações aos novos elementos encontrados, verificando a duplicidade de elementos e se eles são relevantes para o critério buscado, evitando possíveis ruídos nas buscas como elementos que dão acesso a páginas de critérios semelhantes como entre Receita Orçamentária e Receita Extra-Orçamentária. Por fim, caso novos nós filhos não sejam encontrados e todos os nós já tenham sido percorridos o processo de avaliação do critério é finalizado.
Nesta seção é apresentado os procedimentos e métricas adotadas para avaliar e validar a solução proposta nesta pesquisa.
Atualmente o Índice de transparência criado pelo TCE-PB possui 123 itens dividos entre os critérios Despesa Orçamentária, Despesa Extra-Orçamentária, Licitação, Receita Orçamentária, Receita Extra-Orçamentária, Quadro Pessoal, Contratos, Convênios, Usabilidade, Série Histórica e Frequência de atualização, Extração de Dados e Outros. No entanto, pela numerosa quantidade de itens, foi optado pela redução de critérios e consequentemente a redução do número de itens. Para seleção que seriam utilizados durante as avaliações do Auditor Crawler, foram escolhidos critérios com itens mais bem definidos e claros, critérios com maior presença nos sites e considerados fundamentais para transparência pública. Neste sentido, foram selecionados os critérios (61 itens avaliados):
- Despesa Orçamentário;
- Despesa Extra-Orçamentária;
- Receita Orçamentária
- Receita Extra-Orçamentária;
- Licitação
- Quadro Pessoal
Para a análise da eficácia e eficiência do crawler durante as avaliações fiscais é fundamental estabelecer a população/amostra que servirá de base representativa do contexto avaliado. Nesta perspectiva, foi utilizado um recorte de 30 portais de transparência de diferentes municípios da Paraíba, representando 13.4% dos 223 portais existentes no estado.
Como forma de garantir a construção de uma amostra de portais representativa para avaliação da ferramenta os critérios fornecedor do portal, número de portais, as combinações entre fornecedores e a frequência de aparição da combinação foram considerados. Neste sentido, para cada combinação contendo mais de 2 portais foram selecionados de forma aleatória o número de portais que representassem um número superior 10% da combinação na população. A proporção de portais selecionados para amostra por combinação é apresentado na Tabela abaixo.
| Combinação | Total de portais na amostra | % utilizado da população |
|---|---|---|
| Publicsoft | 6 | 12,2 |
| Elmar Tecnologia | 3 | 25,0 |
| e-TICons | 3 | 27,3 |
| Info Public | 2 | 12,5 |
| Alfa Consultoria / Elmar Tecnologia | 2 | 15,4 |
| Portal Próprio / Publicsoft | 2 | 20,0 |
| Alfa Consultoria / Publicsoft | 2 | 22,2 |
| EasyWeb / Publicsoft | 2 | 22,2 |
| Portal Próprio / Elmar Tecnologia | 2 | 12,5 |
| LHSystem / Elmar Tecnologia | 1 | 25,0 |
| DC Soluções | 1 | 33,3 |
| Portal Próprio / e-TICons | 1 | 25,0 |
| Portal Próprio / Info Public | 1 | 33,3 |
| Alfa Consultoria / Info Public | 1 | 50,0 |
| EasyWeb / Publicsoft / e-TICons | 1 | 50,0 |
| Portal Próprio / Publicsoft / Elmar Tecnologia | 1 | 50,0 |
| Franinformática / Publicsoft / Aspec Informática | 1 | 100,0 |
| TI de João Pessoal | 1 | 100,0 |
| EasyWeb / e-TICons | 1 | 16,7 |
obs: O grupo de Portal Próprio são portais de transparência aos quais não foi possível relacioná-lo a nenhuma empresa e que possuem algumas semelhanças entre seus layouts.
Nesse cenário, com o objetivo medir o desempenho do crawler na avaliação da transparência na amostra selecionada, foi proposto a criação de gabaritos que registram a presença ou ausência dos itens de cada critério nas páginas Web de cada portal. A Tabela abaixo apresenta um exemplo do registro do gabarito para os itens do critério Receita Extra Orçamentária no portal do município de Santa Rita:
| municipio | criterio | item | encontrado | local_encontrado | local_encontrado_2 |
|---|---|---|---|---|---|
| Santa Rita | Receita Extra Orçamentária | valor | TRUE | http://siteseticons.com.br/portal/faces/pages/receita/extra/inicio.xhtml | |
| Santa Rita | Receita Extra Orçamentária | codigo | TRUE | http://siteseticons.com.br/portal/faces/pages/receita/extra/inicio.xhtml | |
| Santa Rita | Receita Extra Orçamentária | nomenclatura | TRUE | http://siteseticons.com.br/portal/faces/pages/receita/extra/inicio.xhtml |
Durante a elaboração dos gabaritos cada item registrado foi classificado manualmente, sendo atribuído a coluna encontrado o valor TRUE caso a presença no portal fosse confirmada e FALSE caso contrário. Além disso, foi registrado o local de identificação de cada item, assegurando a corretude da informação durante a comparação entre o gabarito e os resultados do crawler.
De acordo com os resultados obtidos nos gabaritos e avaliações do crawler foram aplicadas as seguintes métricas para avaliar a eficácia da solução proposta nesta pesquisa:
Recall tem o proposito de medir a capacidade do crawler em identificar todos os itens presentes nos portais de transparência. Abaixo é apresentada sua fórmula:
-
TP são os verdadeiros positivos (true positive) que representam o número de itens (nome, CPF, salário de quadro pessoal por exemplo) identificados corretamente como presentes e localizados em locais válidos pelo gabarito;
-
FN são os falsos negativos (false negative) que representam o número de itens identificados incorretamente como ausentes na avaliação do crawler.
Precision tem o objetivo de medir o nível de acerto nos itens identificados com presente durante os experimentos;
-
TP são os verdadeiros positivos (true positive) que representam o número de itens (nome, CPF, salário de quadro pessoal por exemplo) identificados corretamente como presentes e localizados em locais válidos pelo gabarito;
-
FP são os falsos positivos (false positive) que representam o número de itens identificados incorretamente como presente durante avaliação do crawler.
F1-score é proposto com o objetivo de medir a harmonia entre os valores de Precision e Recall;
- Precision é o valor resultante do cálculo apresentado na função de Precision;
- Recall é o valor resultante do cálculo apresentado na função de Recall.
No que diz respeito a eficiência do crawler foram utilizados a medição do número de Nós acessados (URLs, Componentes clicáveis) em cada avaliação, a duração de cada avaliação, o consumo de CPU, Memória RAM e Internet.
Obs: toda a análise dos resultados foi realizada pelo projeto https://github.com/joserafael97/analyze-auditor-crawlers
TODO
TODO
TODO
TODO Falar sobre os prints salvos para validação
Este projeto foi desenvolvido sobre a linguagem Javascript com a ferramenta Puppeteer para criação de Crawlers.
A estrutura de diretórios do projeto está descrita abaixo
.
├── config # Arquivos de configurações do projeto, por exemplo configurações do banco de dados
├── core # Arquivos de configurações do ambiente
├── data # Arquivos contendo dados pré-definidos para gerar collections como palavras chaves
├── db # Arquivos de gerenciamento de conexões com o banco de dados
├── log # Arquivos de logs
├── models # Models de dados e classes auxiliares
├── proof # Diretório contendo printscreen com provas dos itens encontrados (criada automáticamente)
├── utils # Classes utilitárias com functions para auxiliar durante a execução do crawler
├── bfs.js # Arquivo contendo lógica para execução de um BFS para varrer portais de transparência
├── api.js # Arquivo contendo end-points para acesso das avaliações
└── app.js # Aquivo principal para execução do CrawlerPara a execução do projeto é necessário a instalação das seguintes ferramentas
Para instalação das bibliotecas execute o comando abaixo dentro do diretório principal do repositório.
npm install
npm start county="Santa Rita" aproach="bandit" allitens="true"
Os parâmetros apresentados são descritos com mais detalhes abaixo:
- County: Deve ser informar o nome do município ao qual deseja avaliar;
- Aproach: Deve ser informar a abordagem a ser utilizada durante a execução, podendo ser bfs, dfs ou bandit. Caso a abordagem não seja informada a opção bfs é utilizada.
- allitens: Deve ser informar se execução deve considerar todos os itens ou não, caso opção seja false os itens bfs, licitado, edital, pregao, termo_ratificacao, especie, rubrica, alinea, sub_alinea, lic_obj_servico, nome_perdedores, nome_vencedores e aviso não serão pesquisados.
node_modules/.bin/babel-node api/server.js
- José Remígio - Initial work - José Remígio