lstm_crf
albert_embedding_lstm
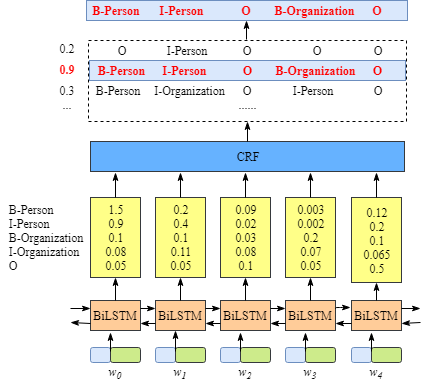
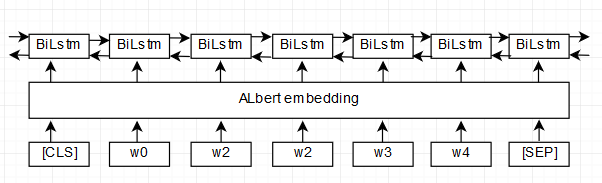
1.这里将每个句子split成一个个字token,将每个token映射成一个数字,再加入masks,然后输入给albert产生句子矩阵表示,比如一个batch=10,句子最大长度为126,加上首尾标志[CLS]和[SEP],max_length=128,albert_base_zh模型输出的数据shape为(batch,max_length,hidden_states)=(10,128,768)。
2.利用albert产生的表示作为lstm的embedding层。
3.没有对albert进行fine-tune。
setp 1: 利用albert/tfmodel_2_pymodel.py
1.将tensorflow预训练模型转化为pytorch可用模型。
2.本程序使用albert_base_zh(小模型体验版), 参数量12M, 层数12,大小为40M。
3.转为pytorch模型后放在albert/pretrain/pytorch目录下。
4.模型的参数见albert/configs/目录。
setp 2: 部分参数设置 models/config.yml
embedding_size: 768
hidden_size: 128
model_path: models/
batch_size: 64
max_length: 128
dropout: 0.5
tags:
- ORG
- PER
- LOC
- T
step 3: train
python main.py train
训练数据来自人民日报的标注数据
> epoch [0] |██ | 395/4473
loss 0.07
epoch [0] |██ | 396/4473
loss 0.06
epoch [0] |██ | 397/4473
loss 0.06
epoch [0] |██ | 398/4473
loss 0.06
epoch [0] |██ | 399/4473
loss 0.06
epoch [0] |██ | 400/4473
loss 0.05
eval
ORG recall 1.00 precision 1.00 f1 1.00
PER recall 0.97 precision 0.96 f1 0.96
LOC recall 1.00 precision 1.00 f1 1.00
T recall 0.84 precision 0.80 f1 0.82
python main.py predict
input text:“刘老根大舞台”被文化部、国家旅游局联合评为首批“国家文化旅游重点项目”
在src/lstm_crf的model.py中
a.albert的预训练模型作为embedding层
> bert_config =BertConfig.from_pretrained(str(config['albert_config_path']), share_type='all')
self.word_embeddings = BertModel.from_pretrained(config['bert_dir'], config=bert_config)
self.word_embeddings.to(DEVICE)
self.word_embeddings.eval()
b.embedding的输出是(batch_size, seq_len, embedding_dim)
> with torch.no_grad():
embeddings = self.word_embeddings(input_ids=sentence, attention_mask=mask)
#因为在albert中的config中设置了"output_hidden_states":"True","output_attentions":"True",所以返回所有层
#也可以只返回最后一层
all_hidden_states, all_attentions = embeddings[-2:] # 这里获取所有层的hidden_satates以及attentions
embeddings = all_hidden_states[-2] # 倒数第二层hidden_states
- https://github.com/huggingface/transformers
- https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html
- https://github.com/lonePatient/albert_pytorch
- https://github.com/brightmart/albert_zh
- https://createmomo.github.io/
如有搜索、推荐、nlp以及大数据挖掘等问题或合作,可联系我:
1、我的github项目介绍:https://github.com/jiangnanboy
2、我的博客园技术博客:https://www.cnblogs.com/little-horse/
3、我的QQ号:2229029156