Reduce number of Map lookups in Graph-Specifics #1021
Conversation
Use Map's computeIfAbsent or computeIfPresent methods where applicable to reduce Map look-ups, which improves performance. To further reduce the number of Map look-ups, avoid unnecessary method calls and take advantage of short-circuit logical operators (like in "UndirectedSpecifics.isEqualsStraightOrInverted()").
|
Assigning this one to @d-michail to review. Also, @HannesWell could you take a look at #958 regarding the need for private fields to avoid the cost of reconstructing Function objects? |
|
Yes, sure I will have a look at it. |
|
After John's comment and looking into #958 I did some benchmarks to further improve the runtime of graph-population. Additionally I sampled the benchmarks using JVisualVM (which is bundled with OpenJDK based JDKs) to find and improve the hotspots. In the following I will present you the benchmark and the results and add some more commits to further reduce the runtime. The benchmark repeatedly populates graphs in a loop using the The code of the benchmark is the following: |
|
First I run the benchmark against the (then) current master (i.e. commit 64e8f1f from the 23th of dec 2020). The benchmark is executed in "Run" mode of my Eclipse 2020-12 (Java-DSL-Tools), using the Java11 GraalVM CE 20.2.0 on my Windows 10 computer, which has a Intel Core i5-3750K@3,4Ghz (base) and 16GB RAM. All following benchmarks use the same setting. Benchmark-results - master The following runtimes are printed: The JVisualVM sampler showed the following results:
(I will attach the snapshots of all sampling sessions in the end as a zip-file because github does not support arbitrary files.) The runtimes measured from within the code are a little bit higher with the sampler attached: First of all the displayed sampler-results show that runtimes measured by the sampler and by the code itself are consistent. The total time the sampler recognised the code being in the Analysis |
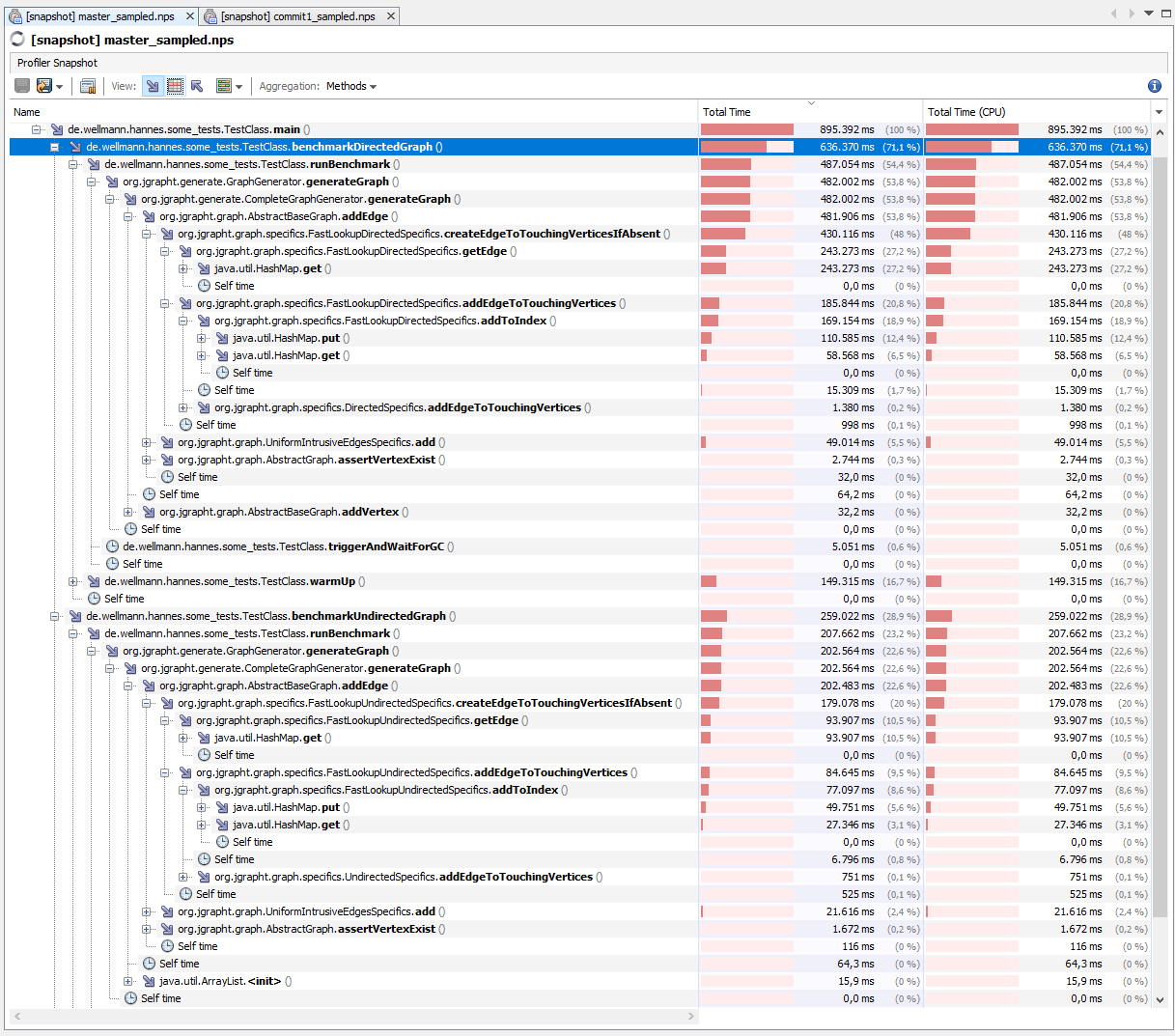
|
Second I did the same benchmark and sampling against the first commit of this PR. Benchmark-results - commit 1 The JVisualVM sampler showed the following results: With attached sampler the printed runtimes are the following: Analysis As a lookahead: summed up a lot of time is spend in the equals method of the Pair-implementation used by the FastLookup-Specifics. And using other vertex-types with |
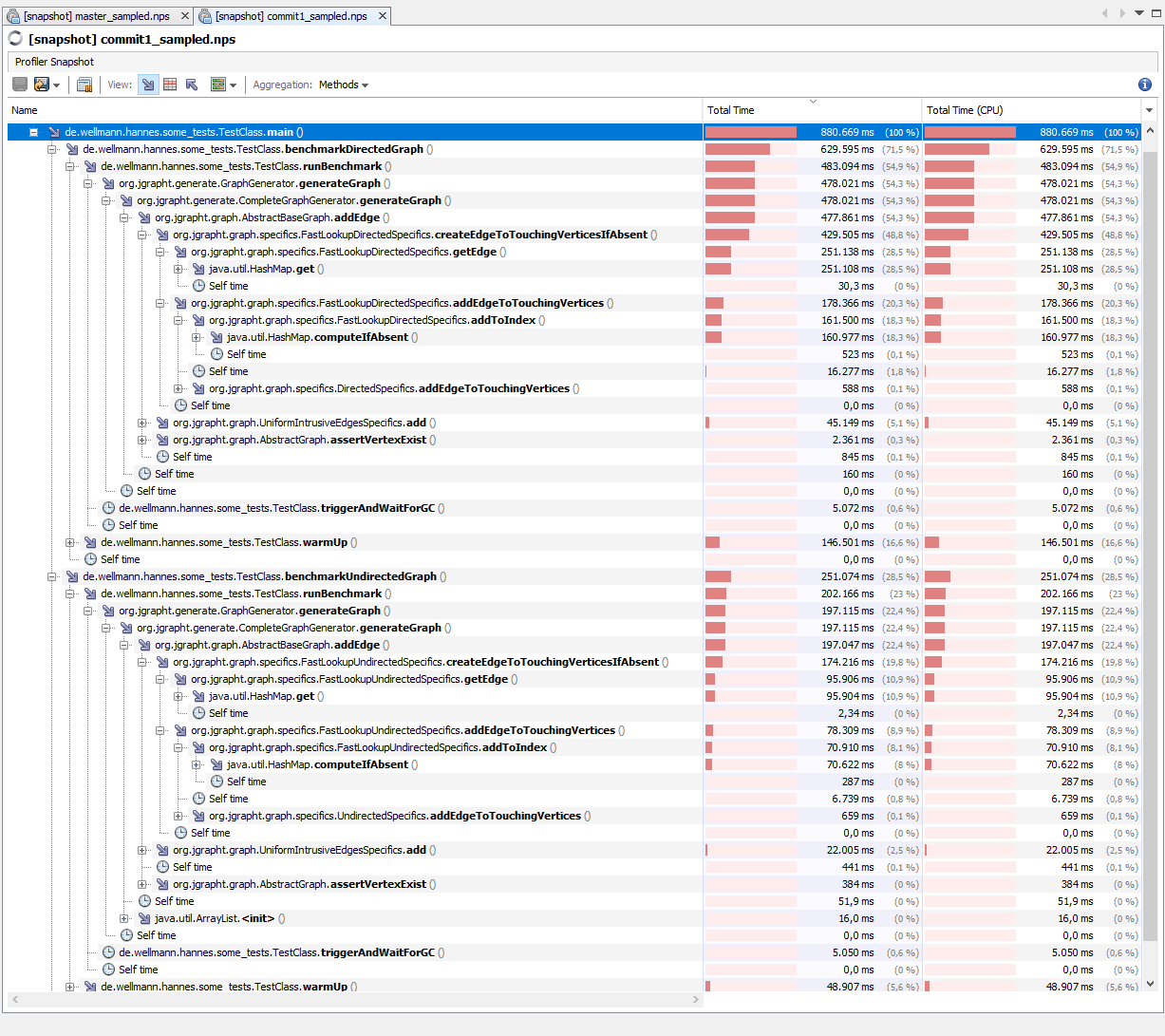
The problem was that the 'source' and 'target' field of IntrusiveEdge, which are used in hashCode() and equals() of IntrusiveEdge, are changed after an Edge is put into the map. Changing the fields considered in hashCode() and equals() after the instance is put into a HastMap/-Set is a bug in general. The optimization of IntrusiveEdgesSpecifics has to be done more specifically. But the IntrusiveEdgesSpecifics can be improved independently of the other classes changed in this PR, so I will do it in another PR (if the other approach works).
|
For the second commit I did the same benchmark and sampling again. I did it before reverting the buggy improvements of Benchmark-results - commit 2
With attached sampler the printed runtimes are the: Analysis First of all we can see from the printed runtimes, that the overall runtime has decreased for about ~17% (undirected) respectively ~12% (directed). That's something but not very much. But, and I think this is important, now we can see the definite and absolute hotspot of populating the graph and it is the From this I conclude, first that the suggested lambda-caching from #958 does not really help in this case and second, since the HashMap spends a lot of time in searching or putting TreeNode-Entries, which I see as a sign of overfull HashMap-buckets, I conclude that another cause for the long runtime could be that the hash-codes of the (Unordered-)Pairs are badly distributed. Another cause could be that the equals() methods of the Pair-implementation are too slow or that it could be worth to consider to allocate the Another thing I find interesting is that the time spend in the What also puzzles me, is that Maybe someone of you has another idea (or can say if I'm completely wrong anywhere). |

|
Could you merge from master? We had a problem with Travis CI, so pull requests weren't getting CI build runs. |
While looking into the implementations of the graph-specifics I noticed some Map lookups that can be avoided. Reducing Map lookups improves the performance, which is why I would like to contribute these changes with this PR.
Map lookups are reduced by using Map's
computeIfAbsent()orcomputeIfPresent()methods where applicable.Furthermore I restructured some methods to avoid unnecessary method calls and take advantage of short-circuit logical operators (like in "UndirectedSpecifics.isEqualsStraightOrInverted()"), which in the end again avoids lookups.
HISTORY.mdorCONTRIBUTORS.md