This is my "swiss army knife" for data. I find myself encountering lots of chunks of data in my daily activities, and I end up using lots of little one-liners and custom scripts. Some awk, some ruby, etc. -- but some of these tasks are so repetitive, I really want to simplify their use. So, without further ado, this is my "data knife".
Just clone the repository as follows:
$ git clone https://github.com/jephthai/dataknife
Then make sure that the "dataknife.rb" file is executable and link it somewhere appropriate so it will be in your path. I name it "dk" to keep things simple.
$ chmod +x dataknife/dataknife.rb
$ ln -s `pwd`/dataknife/dataknife.rb ~/bin/dk
$ dk
------------------------------------------------------------------------
Data Knife - by Josh Stone (yakovdk@gmail.com) - (C) 2014
------------------------------------------------------------------------
usage: /Users/jstone/bin/dk <cmd>
Most plugins read from standard input and print the result
on the standard output stream.
base64 [(e|d)] Base64 decodes input (encode if 'e' parameter provided)
bytes Counts bytes in data blob
chex Colorized hex-dump of input
col C1 [C2] ... Print indicated column(s) from input lines
colsep S C1 [C2] ... Print indicated column(s) from input lines w/ separator
decrypt algo key Decrypt input with indicated cipher ('list' to enum) and key
desym Remove any non-alphabetic symbols from the input
detag Remove XML/HTML tags from the input
encrypt algo key Encrypt input with indicated cipher ('list' to enum) and key
hex (e|d) HEX encoded input ('e'=encode, 'd'=decode)
intersect f1 [f2]... Print intersection of provided files / input
ips Print all IP addresses detected in the input
lines Counts lines in data blob
maskips Anonymize IP addresses from the input
mean Tokenizes the input and calculates the numeric mean
shannon Calculates the Shannon entropy of the input
tokens [u] Returns all whitespace-delimited tokens in input
unbin [.] Remove non-printable characters from the input
urlencode (e|d) URL-decodes input ('e'=encode, 'd'=decode)
All of the examples provided here assume that you have dataknife accessible in your $PATH as the command "dk".
There are lots of plugins here, and they're growing every time I find another repetitive task. I'll give you a breakdown of the various options in here, and this will probably grow over time. If you have any ideas on how to improve this, let me know:
The a85 plugin either encodes or decodes ASCII85, which is a slightly more efficient encoding than Base64. Its primary use historically has been in PostScript and PDF documents. It can be handy at times when you want an ASCII representation of binary data, but want to avoid obvious Base64 use (or need to save a few more bytes).
$ echo "The quick brown fox jumps over the lazy dog" | dk a85 e
<~4FU7CAKYu8Bk(p$@WHC2DBNP0GT^aDD/aP=Dg#]4+EV:.+DbJ4Gp$X9B*s)O~>
$ echo '<~4FU7CAKYu8Bk(p$@WHC2DBNP0GT^aDD/aP=Dg#]4+EV:.+DbJ4Gp$X9B*s)O~>' | dk a85 d
<~The quick brown fox jumps over the lazy dog
Encode the input as an array literal in the C or C# languages. It's fairly straightforward for C:
$ echo "The quick brown fox jumps over the lazy dog" | dk array c
unsigned char[] array = {
0x54, 0x68, 0x65, 0x20, 0x71, 0x75, 0x69, 0x63, 0x6b, 0x20, 0x62, 0x72, 0x6f, 0x77, 0x6e, 0x20,
0x66, 0x6f, 0x78, 0x20, 0x6a, 0x75, 0x6d, 0x70, 0x73, 0x20, 0x6f, 0x76, 0x65, 0x72, 0x20, 0x74,
0x68, 0x65, 0x20, 0x6c, 0x61, 0x7a, 0x79, 0x20, 0x64, 0x6f, 0x67, 0x0a};
But for C#, we do some extra tricks. If your data is quite large, and non-random, the hex literal representation is really wasteful. Data knife will dynamically determine a more efficient representation, choosing to encode chunks of data as hexadecimal, decimal, or combinations of bit-shifted and bit-wise combinations of literal values. E.g.:
$ dd if=`which ls` bs=256 count=1 2>/dev/null | dk array cs
256 bytes copied, 2.6249e-05 s, 9.8 MB/s
byte[] array = new byte[256];
Buffer.BlockCopy(new ulong[] {0x10102464c457f,0,0x1003e0003,22608,64,132000,57345ul<<38,
0x1b001c00400009,5ul<<32|6,64,64,64,504,504,8,1ul<<34|3,568,568,568,28,28,1,5ul<<32|1,0,
0,0,124648,124648,1<<21,3ul<<33|1,126960,2224112}, 0, array, 0, 256);
The base64 plugin does Base64 encoding and decoding. By default it will decode (this seems to be what I run into most often). However, adding the 'e' flag will encode text. Here is an example:
$ echo "The quick brown fox jumps over the lazy dog" | dk base64 e
VGhlIHF1aWNrIGJyb3duIGZveCBqdW1wcyBvdmVyIHRoZSBsYXp5IGRvZwo=
$ echo VGhlIHF1aWNrIGJyb3duIGZveCBqdW1wcyBvdmVyIHRoZSBsYXp5IGRvZwo= | dk base64
The quick brown fox jumps over the lazy dog
$
This is a Ruby port of a color hex-dump utility that I wrote some time ago. It turns out that colorizing the output of a hexdump is very handy, as there are very distinctive patterns in many types of files. For example, symbol tables in libraries look very different from executable code, which is also very different from plain text. The chex plugin will show you a color hexdump similar to the following for the provided input:
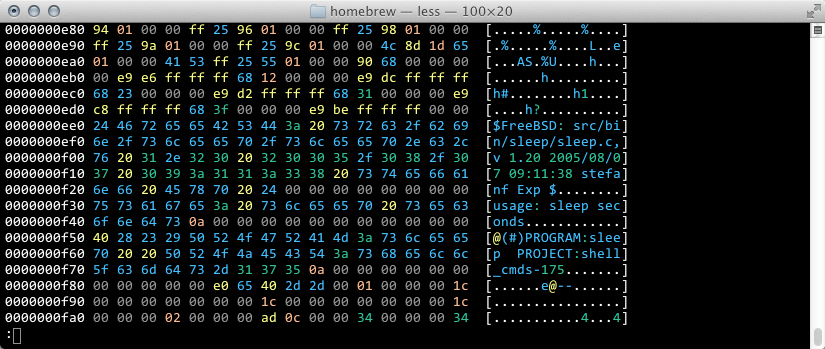
Column mode (the col) plugin will print out the numbered columns indicated in the arguments. This is my replacement for doing something like awk '{print $2 " " $5}' all the time. So much SHIFTing! I do this so often, this really speeds things up:
$ ls -l /bin | head -n 10 | dk col 5 9
18576 [
1228240 bash
19648 cat
26080 chmod
24848 cp
357984 csh
24496 date
23872 dd
19536 df
This is similar to the above col mode, but this plugin is called colsep. The first parameter is the separator that should divide the fields in the input. Note that this is not the same as awk or cut -- the separator is a regular expression (so something like '[: ]' will interpret both colons (:) and spaces ( ) as field separators. Very handy:
$ grep root /etc/passwd | dk colsep : 1 6
root /var/root
daemon /var/root
_cvmsroot /var/empty
Output as a hex-escaped C-language string (also applies to any other language that uses similar escape codes). All bytes will be escaped, so there is no recognition of byte values that are valid ASCII characters (possible enhancement for the future!):
$ echo "The quick brown fox jumps over the lazy dog" | dk cstring
\x54\x68\x65\x20\x71\x75\x69\x63\x6b\x20\x62\x72\x6f\x77\x6e\x20\x66\x6f\x78\x0a
Makes an attempt to remove ANSI control sequences from the input (such as color codes). This might not be completely perfect, as some ANSI control sequences can be sort of complicated :-/.
$ ls -a --color . | dk chex
0000000000 1b 5b 30 6d 1b 5b 30 31 3b 33 34 6d 2e 1b 5b 30 [.[0m.[01;34m..[0]
0000000010 6d 2f 0a 1b 5b 30 31 3b 33 34 6d 2e 2e 1b 5b 30 [m/..[01;34m...[0]
0000000020 6d 2f 0a [m/.]
$ ls -a --color . | dk decolor | dk chex
0000000000 2e 2f 0a 2e 2e 2f 0a [./.../.]
This filter removes non-alphabetic characters from the input. I've used it numerous times to generate word lists for dictionary files from various input (e.g., scrape a web site, cat through the desym filter, and deduplicate...):
$ curl -s joshstone.us | dk desym | head -n 10
DOCTYPE html PUBLIC W3C DTD XHTML 1 0 Strict EN http www w3 org TR xhtml1 DTD xhtml1 strict dtd
html
head
title Josh Stone s Web Site title
meta http equiv content type content text html charset utf 8
style
body
background color black
color ffffdd
font family monospace sans serif
Remove tags from HTML / XML input -- handy for extracting the content from such documents:
$ curl -s joshstone.us | dk detag | head -n 10
Josh Stone's Web Site
body {
background-color: black;
color: #ffffdd;
font-family: monospace, sans-serif;
If you're working with stuff from an IBM Mainframe, you will want to decode EBCDIC. I have added this module -- note that it works with the specific EBCDIC from the z/OS mainframe I was using. There are different varieties of EBCDIC, so you may have to tweak the character map in this code if you have some other variant. Here's an example of how it works:
atlantis-2:zos jstone$ head -n 4 /etc/passwd | dk ebcdic e | dk chex
0000000000 7b 7b 15 7b 40 e4 a2 85 99 40 c4 81 a3 81 82 81 [{{.{@....@......]
0000000010 a2 85 15 7b 40 15 7b 40 d5 96 a3 85 40 a3 88 81 [...{@.{@....@...]
0000000020 a3 40 a3 88 89 a2 40 86 89 93 85 40 89 a2 40 83 [.@....@....@..@.]
0000000030 96 95 a2 a4 93 a3 85 84 40 84 89 99 85 83 a3 93 [........@.......]
0000000040 a8 40 96 95 93 a8 40 a6 88 85 95 40 a3 88 85 40 [.@....@....@...@]
0000000050 a2 a8 a2 a3 85 94 40 89 a2 40 99 a4 95 95 89 95 [......@..@......]
0000000060 87 15 [..]
atlantis-2:zos jstone$ head -n 4 /etc/passwd | dk ebcdic e | dk ebcdic d | dk chex
0000000000 23 23 0a 23 20 55 73 65 72 20 44 61 74 61 62 61 [##.# User Databa]
0000000010 73 65 0a 23 20 0a 23 20 4e 6f 74 65 20 74 68 61 [se.# .# Note tha]
0000000020 74 20 74 68 69 73 20 66 69 6c 65 20 69 73 20 63 [t this file is c]
0000000030 6f 6e 73 75 6c 74 65 64 20 64 69 72 65 63 74 6c [onsulted directl]
0000000040 79 20 6f 6e 6c 79 20 77 68 65 6e 20 74 68 65 20 [y only when the ]
0000000050 73 79 73 74 65 6d 20 69 73 20 72 75 6e 6e 69 6e [system is runnin]
0000000060 67 0a [g.]
This filter encodes the input using Microsoft's Half-ASCII Biased Encoding (used for NetBIOS names in network protocols, and a few other weird places). It's no more efficient than hex encoding, using two bytes of output for each byte of input. But sometimes it needs to be used :-/.
$ echo "The quick brown fox" | dk habe
FEGIGFCAHBHFGJGDGLCAGCHCGPHHGOCAGGGPHI
$ echo "FEGIGFCAHBHFGJGDGLCAGCHCGPHHGOCAGGGPHI" | dk habe d
The quick brown fox
Hex converts the input to and from a hexadecimal representation. Binary data works well this way, for example, if you need to transfer it to someone else:
$ echo "The quick brown fox" | dk hex e
54686520717569636b2062726f776e20666f780a
Decoding works as well, with the 'd' parameter:
$ echo 54686520717569636b2062726f776e20666f780a | dk hex d
The quick brown fox
Serves the current directory with a local web server.
I find myself needing to find the intersection of two files very often, where the elements in the file are found one per line. I usually end up catting both files together, then sorting, then uniqing, and awking where the count is equal to two. whew. That's a lot of work. Now I can do this:
$ for i in a b c; do echo $i >> a; done
$ for i in b c d; do echo $i >> b; done
$ dk intersect a b
b
c
$
The ips plugin is very helpful in my penetration testing racket. How often do you have some tool output or data file with lots of mixed content, but including some IP addresses? It's no fun to parse through sometimes, because the data may not be very structured. This plugin extracts everything that looks like an IP and prints it out ('u' is optional - it prints only the unique ones):
$ dig @8.8.8.8 google.com ANY | dk ips u
8.8.8.8
74.125.227.225
74.125.227.227
74.125.227.228
74.125.227.233
74.125.227.230
74.125.227.226
74.125.227.238
74.125.227.232
74.125.227.231
74.125.227.229
74.125.227.224
216.73.93.70
216.73.93.72
8.8.8.8
8.8.8.8
Pretty prints input JSON (handy because you run into minified JSON all the time, and it's not really human readable...):
$ echo '{"menu": {"id": "file","value": "File","popup": {"menuitem": [{"value": "New", "onclick": "CreateNewDoc()"},{"value": "Open", "onclick": "OpenDoc()"},{"value": "Close", "onclick": "CloseDoc()"}]}}}' | dk json
{
"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{
"value": "New",
"onclick": "CreateNewDoc()"
},
{
"value": "Open",
"onclick": "OpenDoc()"
},
{
"value": "Close",
"onclick": "CloseDoc()"
}
]
}
}
}
This mode will replace all identified IP addresses with "randomized" replacements. The IPs are stored in a hierarchy of hashes so that once one particular IP is mapped to another, subsequent occurrences of that IP will be mapped to the same "randomized" value. This is useful for sending someone redacted command output so you don't have to replace IP addresses yourself.
As an interesting quirk of the method I used to do this, the resulting "randomized" addresses will generally be in each other's subnets. This will not necessarily be "correct" when applying netmasks, but it will mean that all 192.168.. addresses will share a common first and second (and third where applicable) octet. This may help you keep at least a little context in mind when you're reading the output. Note that subnets larger than a /24 will probably get broken, and subnets smaller than /24 will possibly not make as much sense as IPs may move closer/farther from each other (or change order).
So this:
$ ifconfig vmnet2
vmnet2: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:50:56:c0:00:02
inet 192.168.159.1 netmask 0xffffff00 broadcast 192.168.159.255
Becomes this (note the wonky broadcast -- I didn't say the output would make sense!):
$ ifconfig vmnet2 | dk maskips
vmnet2: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 00:50:56:c0:00:02
inet 217.210.145.109 netmask 0xffffff00 broadcast 217.210.145.190
This takes a list of numbers (you can mix non-numeric content in -- this will tokenize the input and select out just the numeric elements) and prints out the mean (average). Here's the average size of files in my /bin directory:
$ ls -l /bin | dk col 5 | dk mean
157711.13513513515
Implement a very simple rolling XOR encoder. Takes a key from 0 to 255, and XORs each incoming byte with the key. After each operation, the key is incremented, eventually overflowing back to 0 and continuing until EOF:
$ echo "The quick brown fox jumps over the lazy dog" | dk rollxor 42 | dk chex
0000000000 7e 43 49 0d 5f 5a 59 52 59 13 56 47 59 40 56 19 [~CI._ZYRY.VGY@V.]
0000000010 5c 54 44 1d 54 4a 2d 31 31 63 2b 33 23 35 68 3d [\TD.TJ-11c+3#5h=]
0000000020 22 2e 6c 21 2f 35 29 71 36 3c 33 5f [".l!/5)q6<3_]
Simply repeat the operation twice to get the original data back:
$ echo "The quick brown fox jumps over the lazy dog" | dk rollxor 42 | dk rollxor 42
The quick brown fox jumps over the lazy dog
Ever wonder how random something is? Sometimes when you're looking at some unknown block of data, it can be helpful to check its entropy. This plugin calculates the Shannon entropy of the input (assuming it's read in as bytes). Here's the entropy of a few interesting files:
$ dk shannon < /usr/share/dict/words
4.327008938128565
$ dk shannon < /etc/passwd
5.003381667727524
$ dk shannon < /Users/jstone/src/samba-4.1.8.tar.gz
7.999217974852452
When developing shellcode, it's kind of handy to be able to quickly generate a program that can execute it. This filter does just this, converting the input to a C-language representation, and emitting a main function that casts it to a function pointer and executes it. Note that in most modern OSs, this will require some adjustment due to NX permissions bits on memory pages:
$ echo "The quick brown fox jumps over the lazy dog" | dk rollxor 42 | dk shellexec
unsigned char array[] __attribute__ ((section(".text"))) = {
0x7e, 0x43, 0x49, 0x0d, 0x5f, 0x5a, 0x59, 0x52, 0x59, 0x13, 0x56, 0x47, 0x59, 0x40, 0x56, 0x19,
0x5c, 0x54, 0x44, 0x1d, 0x54, 0x4a, 0x2d, 0x31, 0x31, 0x63, 0x2b, 0x33, 0x23, 0x35, 0x68, 0x3d,
0x22, 0x2e, 0x6c, 0x21, 0x2f, 0x35, 0x29, 0x71, 0x36, 0x3c, 0x33, 0x5f};
int main() {
((void(*)())array)();
}
If you want to break a file up into its constituent, space-delimited words, you can do a few things. For example, you can set your IFS to a space (but what about tabs and newlines?). You can do some reasonable perl or sed one-liners, but there are quirks. Here's a nice way to do it pretty cleanly:
$ echo "The quick brown fox" | dk tokens
The
quick
brown
fox
This removes non-printable characters from the input. This is kind of like looking at the ASCII representation of a hexdump (the "right side"). It's kind of like a lower-level "strings" command. The '.' argument causes non-printable characters to be printed as a period character. Something like this (note, I added newlines to make this look a bit cleaner):
$ dd if=/bin/ls bs=512 count=1 | dk unbin .
1+0 records in
1+0 records out
512 bytes transferred in 0.000016 secs (32051995 bytes/sec)
.......................... .........H...__PAGEZERO..........
................................................(...__TEXT..
.................P...............P......................__te
xt..........__TEXT...................3......................
................__stubs.........__TEXT...........D..........
.....D..............................__stub_helper...__TEXT..
.........F...............F..............................__co
nst.........__TEXT...........I...............I..............
................__cstring.......
The urlencode plugin either URL-encodes or URL-decodes the input. This gets handy when you're working on web-related stuff and you don't necessarily want (or can't) get out Burp Suite.
$ echo '!@#%^&*(' | dk urlencode
!@%23%25%5E&*(
These modes encrypt or decrypt content. It's not the most useful ever, because it's restricted to the ciphers supported by the 'crypt' gem. Also, I believe the only option is CBC, so if you need to decrypt some random thing you found, you'll still have to write it up yourself. But, for a handy little one-liner:
$ echo "The quick brown fox" | dk encrypt blowfish s3cr3t | dk hex e
681db9e3550e2689eaae50de3e223d398aac40d571720a363d85c21676669f31
$ echo 681db9e3550e2689eaae50de3e223d398aac40d571720a363d85c21676669f31 \
| dk hex d | dk decrypt blowfish s3cr3t
The quick brown fox
Note that we can make sure that this is really working with something like this:
$ dk shannon < /usr/share/dict/words
4.327008938128565
$ dk encrypt blowfish s3cr3t < /usr/share/dict/words | dk shannon
7.999929192672373
And no... it's not the fastest thing ever. But it's somewhat handy.