{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Many organizations and individuals receive too much email spam and they only want the legitimate emails in their inbox. All incoming spam email should be filtered out. This project starts by pre-processing the text data in the raw emails. Then we train a machine learning model that classifies the email as either spam or non-spam. Then finally, we test the model’s performance. This project is implemented basically using Naïve-Bayes Classification. In order to make the algorithm understand the text in the email, there is some natural language processing involved. For doing this, the project makes use of NLTK package found online at www.nltk.org. Apart from this, this project makes use of word clouds and creates the vocabulary for spam classification.
- Getting Started
- Introduction
- Procedure
- Visualizing Results
- Metrics and Evaluation
- Conclusion
- References
There are 3 code notebooks in total as follows:
- Naive Bayes Spam Email Classifier - Pre-Preprocessing.ipynb
- Naive Bayes Spam Email Classifier - Testing, Inference, & Evaluation.ipynb
- Naive Bayes Spam Email Classifier - Training.ipynb
You will find the corpus used for this project at https://spamassassin.apache.org/old/publiccorpus/.
NOTE: Please feel free to reach out to ivedantshrivastava@gmail.com with any doubts regarding this project.
Naive Bayes spam filtering is a baseline technique for dealing with spam emails and tailoring it for the needs of a particular individual. The process involves looking for particular words that have probabilities of showing up in a spam email. For this, the filter is trained by first manually indicating some data (training dataset) as spam or legitimate (ham/non-spam) emails. When the model is trained, the probabilities of words (likelihood functions) are used to determine whether the new emails are spam or not. Each word in the email contributes to the probability of it being spam or ham and this probability is computed using Bayes’ Theorem. For this particular project, the dataset has been gathered from SpamAssassin public corpus, available online at https://spamassassin.apache.org/old/publiccorpus/.
The procedure basically involves of three stages - Pre-processing the data, training the model, and finally testing and evaluating the performance of the model. We have implemented every stage in a separate notebook each for better understanding and efficiency.
We start this stage in the Jupyter Notebook called "Naive Bayes Spam Email Classifier - Pre-Preprocessing.ipynb". After importing all the Python libraries in the Jupyter notebook and defining all the constants, there are a few procedures that are performed in order to pre-process the data before the model is trained. First, data cleaning is done. For this, we first check for missing values i.e. check if any email bodies are null and empty. Then we locate them and remove their system file entries from our dataframe. Then for making it easy to track the remaining files, we add Document IDs to the dataset. This is then saved as a JSON file using Pandas library. In order to have a better understanding of the dataset, we then visualize it using charts. In this project, we have made use of a donut chart.

Next, comes downloading the resources we need from the NLTK library. We make use of the package ‘punkt’ for tokenizers and ‘stopwords’ for stopwords. Then we define a function clean_msg_no_html for removing the HTML tags, converting all the text in the email body to lower case, splitting it into individual words and stemming them followed by removing all the stop words and punctuation. This function is applied to all the email messages in our dataframe.
We first slice the data frame into two different categories - Spam emails and Non-Spam/Ham emails. Then we subset the series with an index. In order to make the word clouds for both Spam and Non-Spam words, we are using WordCloud package from wordcloud python library.


We generate a vocabulary and dictionary by finding the unique words and then the most common words. In our dataset, we found that there are 27305 unique words. The most common word was “http” meaning that majority of the spam emails have some kind of hyperlink in them. We thus create a Vocabulary Dataframe with Word IDs for tracking them. Finally, we save this Vocabulary as a .csv file.
We first start with creating a dataframe with one word per column. Then we split the data into training and testing dataset. Here, our number of training samples is 4057 which make up to 70% of the training set. Then we create a sparse matrix for the training data. We then combine the occurrences of the words and then save this training data as a .txt file. Similarly, we create a sparse matrix for the test data and save it as a .txt file.
We start this stage in another Jupyter notebook named "Naive Bayes Spam Email Classifier - Testing, Inference, & Evaluation.ipynb". Again, we import all the required Python libraries and define our constants. Then we load our data which are the outputs of previous stage notebook from the .txt files into NumPy arrays. Then we define a function to create a full matrix from a sparse matrix which returns us a pandas dataframe.
We first calculate the probability of an email being spam among our dataset. We found that it is approximately 0.311. Then we sum the number of tokens in Spam and Ham emails and we train them. Then we calculate the following three probabilities for all the vocabulary:
- Probability that a token occurs given that the email is Spam.
- Probability that a token occurs given that the email is Non-Spam.
- Probability that a token occurs.
We save this trained model into three various .txt files - spam token probability, non-spam token probability, and all token probability.
This stage is implemented in another Jupyter Notebook called "Naive Bayes Spam Email Classifier - Testing, Inference, & Evaluation.ipynb". Again, we import all the required Python libraries and define our constants. Then we load our data which are the outputs of previous stage notebook.
A Prior is defined as a guess or belief about some quantity. In Bayesian approach to statistics, we are allowed to have a first guess about some quantity before any evidence is examined and this case can be based on prior knowledge. Since we found that the probability of spam is approximately 31% in the previous notebook, we are using the value 0.3116 as the Prior here.
We first calculate the joint probabilities in log format using the following formulae:

We then start making predictions by checking for the higher joint probability. Based on this, we get the final result of whether an email is spam or not.
We performed an accuracy check of our model and found that approximately 96.98% of the documents were classified correctly in their testing dataset. The fraction classified incorrectly is 3.02%. Thus, accuracy of the model is 96.98%.
We visualize our results and draw a decision boundary. For better understanding and representation of data, we created two subplots with one being a zoomed version.
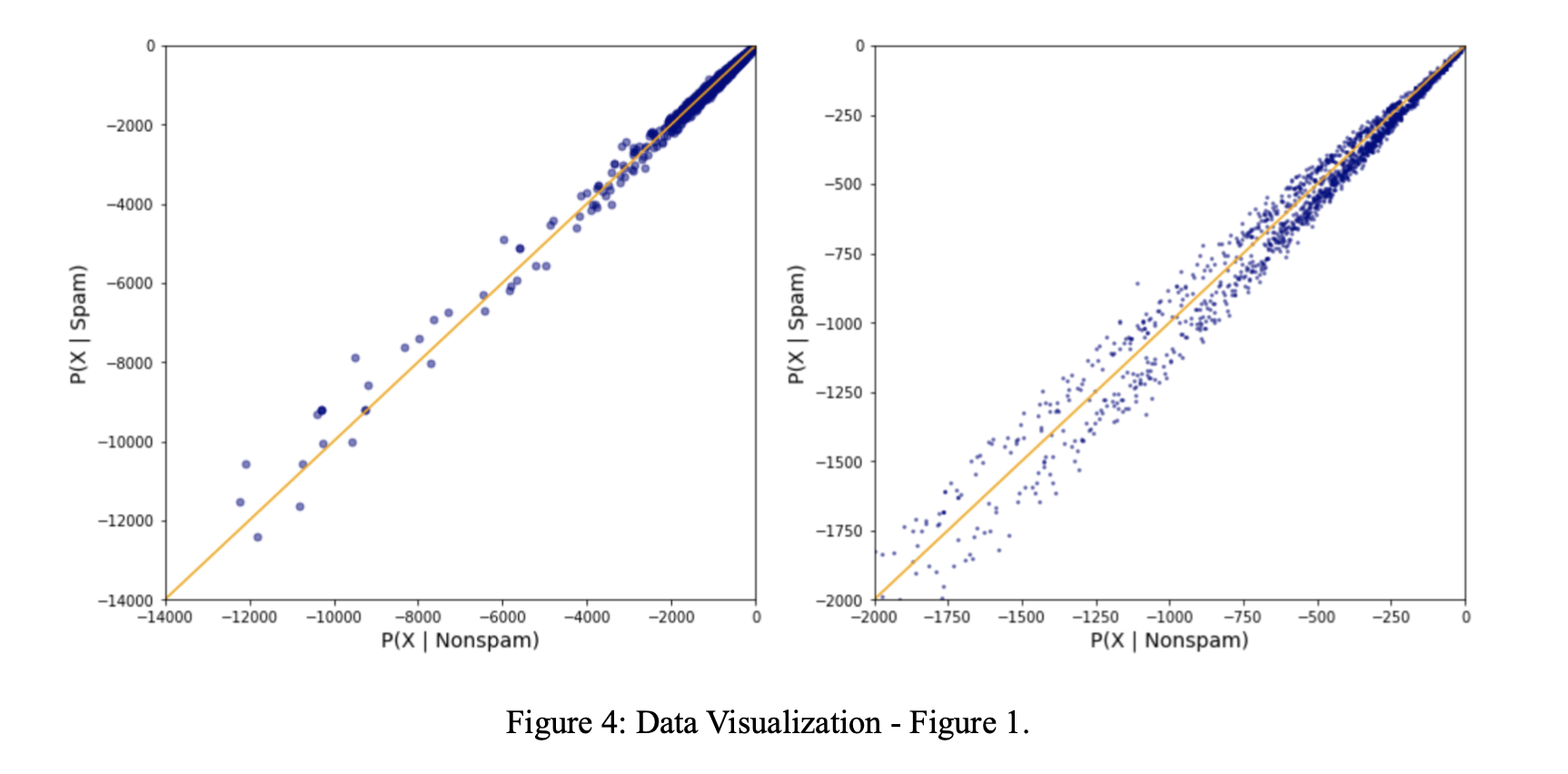
In order to make it look even better and categorize better between the data points, we used some styling and plotted this.

We found that the total number of false positives is 11 and the total number of false negatives is 41.
We found that the recall score is 93.04%, the precision score is 0.98, and the F1 Score is 0.95.
In this project, we successfully pre-processed, trained, and tested a machine learning model based on Naive Bayes Classification for classifying whether an email is spam or non-spam. We also implemented word clouds using NLP methodologies to detect word stems and build word clouds for both spam and non-spam word stems. We also visualized our results using some chart styling methods for better data representation. Alternately, ScikitLearn can be used to implement Naive Bayes in our model. Our model misclassifies 41 non-spam emails as spam emails and 11 spam emails as spam emails and achieves 96.98% accuracy.
- Conway, D. & White, J. Machine Learning for Hackers, February 2012: O’Reilly Media.
- https://towardsdatascience.com/implementing-a-naive-bayes-classifier-for-text-categorization-in-five-steps-f9192cdd54c3
- Natural Language Toolkit: https://www.nltk.org
- SpamAssasin Public Corpus: https://spamassassin.apache.org/old/publiccorpus/
Vedant Shrivastava (GitHub: https://github.com/ivedants ; Email: ivedantshrivastava@gmail.com)