Developer documentation
This page describes the overall structure of the Duplicati backup system.
It is intended to serve as an overview document for users and developers looking to find out where a certain feature is implemented or could be implemented.
This document is work-in-progress, and will likely be split into multiple documents later.
At the heart of Duplicati is a core algorithm which keeps track of all backup data. The core algorithm is implemented in the Duplicati.Library.Main.dll, and contains various methods to perform backup, restore and queries on the backup. The core library uses a non-blocking reporting system, which allows the core library to inform the outer elements of the current progress inside the core library.
The core library relies on dynamically loaded libraries that implement plugable components. The plugable components currently includes: backends, compression, encryption, and generic modules.
The backends encapsulate the actual communication with a remote host with a simple abstraction, namely that the backend can perform 4 operations: GET, PUT, LIST, DELETE. All operations performed by Duplicati relies on only these operations, enabling almost any storage to be implemented as a destination. If no verification is required, Duplicati can perform backups with only the PUT method.
The compression libraries implements a simple interface, such that any compressed volume can be treated as a directory without requiring a full decompression or operating system mounts.
The encryption libraries work on a single file level, and simply encrypts or decrypts the input file. This allows Duplicati to perform all encryption on the local machine in a trust-no-one manner.
The generic modules can hook into the process and run before and after an operation has been performed. They are used to implement various functionality, such as additional SSL features, emails and script support.
The commandline interface to Duplicati is basically a wrapper, which allows the user to invoke the various methods inside the core library. The commandline interface in Duplicati.CommandLine.exe contains a small amount of logic to parse the commandline and assist the user. The reporting is picked up from the core library and periodically written to the console, so a user can follow the progress.
The Duplicati.Server.exe module comprises a scheduler, a backup task repository, a web-server and an execution system. All backup configurations are stored in a database, and the scheduler makes it possible to run backups at scheduled times. The web-server provides the UI by hosting html, css and javascript files, and also exposes a REST API for interfacing with the scheduler, database and execution system. The execution system is responsible for calling the core library, in the same way the commandline interface does.
Duplicati.GUI.TrayIcon.exe implements a small tray-icon with one of the three UI toolkits: Windows.Forms, Gtk or Cocoa. This means that the tray-icon will look native regardless of the operating system. The tray-icon process will, by default, also start Duplicati.Server.exe and connect to it, so it can display the state of the server (optionally, it can connect to a running server instance). It should also be possible to later host a webbrowser in a window that looks native to the platform, and possibly extend the permissions normally granted to the UI when running as a webpage.
Duplicati.Service.exe can also start Duplicati.Server.exe, but does so by starting it as a separate process. It will periodically check the process to see if it is running, and restart it if it crashes or fails to respond.
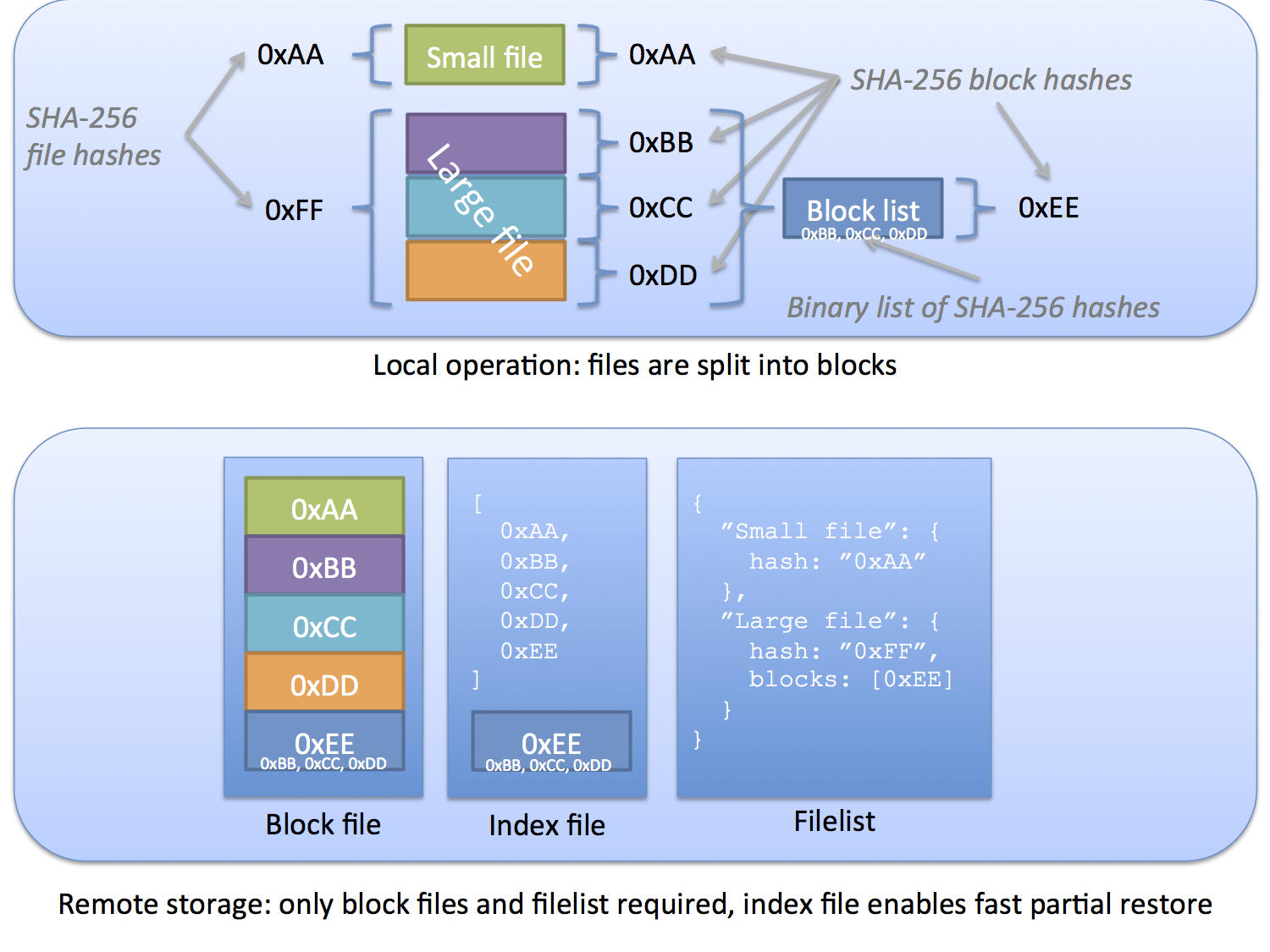
At the core of Duplicati is a very simple algorithm: split a file into even sized chunks; associate each path with a list of block hashes.
The contents of the even sized chunks are called "blocks" and are stored inside compressed archives with a ".dblocks" extension. Each block is stored as a file inside the compressed file, where the hash of the block is the filename.
For each file (or folder) the full path is stored, along with an ordered list of hashes for the blocks needed to recreate the file. Each path may also have a metadata block associated, which contains file permissions, modification timestamps, etc. A list of all paths and hashes associated with a backup are stored as a single json formatted file inside a ".dlist" compressed volume.
For large files, the list of hashes may take up a substantial amount of space. For this reason, Duplicati stores the list of hashes inside a data block. For files that are smaller than a single block, the file entry in the dindex file will only contain the final file hash, as that is the same as the block that keeps it. For files larger than a single block, the list of hashes found for that path entry are "blockhashes", meaning that the data block contains hashes pointing to other blocks. In other words: there is one level of indirection.
This image illustrates how files are sliced and stored on the remote destination.
To reduce storage requirements, all known hashes are stored inside an SQLite database on the local machine. This database keeps track of where all blocks are located, and what the remote storage folder is supposed to look like, and is used to verify that everything is running as expected.
To restore a file, the local database can be queried to figure out which dblock files needs to be fetched in order to get all required blocks for a given restore. The database also helps performing queries, such as finding a deleted file, or pinpointing the last time a file changed. Once the dblock files are fetched, restoring a file is a matter of writing out the data in sequence.
Should the local database become missing or defective, it can be recreated from the remote data. However, the dblock files contain all the actual data, so it might require a massive download. To mitigate this issue, Duplicati also emits small compressed ".dindex" files. Inside the dindex files are a single file with the same name as the dblock file it contains information about. Inside that file is a simple list of all the hashes contained in that dblock file. The dindex files can also contain the "blockhashes", such that the indirection can be resolved directly from the dindex files. This means that the local database can be restored from only the dlist and dindex files.
Should it occur that some information is missing after restoring the database using only the dlist and dindex files, Duplicati will download dblock files at random until all information is accounted for. Optionally, it is possible to restore the database with information about only paths, or only for a specific dlist entry (i.e. only for a backup snapshot).
For the case where there is massive corruption in the remote data, or parts of the data is lost, Duplicati features a recovery tool, which allows you to salvage as much as possible of your data. It works in steps, where you can manually intervene between each step. The recovery process does not use or need the dindex files.
First step is to download the data and decrypt it as required. This step can be performed with the tool, or you can manually download and decrypt the files if that works better.
Second step is indexing, which produces a sorted text file with the hash and the filename of where it is found. This text file is used to speed up the restore process and can be edited or produced manually should it be required.
Third and final step is to actually restore the files, which reads a dlist file and opens all compressed volumes and extract the blocks. The procedure is robust, in that it continues (with warnings) even if some blocks are missing or damaged.
Duplicati produces three distinct file types: dlist, dblock, and dindex. The dlist file represents a backup snapshot and it is named with the time it was produced. To avoid problems with daylight savings time and calendar cultural differences, the name is always in UTC and stored in ISO format. The dlist filenames are useful when restoring without a local database, such that it is not required to download all dlist files.
The dblock and dindex files have random names, that convey no meaning. They always start with b and i respectively, to allow filtering based on a file prefix, which improves interoperability with storage that provides prefix rules (such as Amazon Glacier).
To prevent a verified bug in Apache WebDAV (and potentially other services), files are never overwritten. If an upload fails, a new name is generated, and the upload is retried. For the dblock and dindex files, a new random name is generated, but for the dlist filename this is not possible as it conveys information. The timestamp is increased by a second for each attempt to create a unique name, which only affects the accuracy of the timestamps when listing the remote backup sets.
There are currently two compression modules: zip and 7z. The zip module is based on SharpCompress and supports a number of compression algorithms and compression levels. The default setup is to provide maximum compression with the deflate algorithm.
The 7z module supports multicore compression, using the LZMA2 algorithm. It generally compresses slightly better than the zip module, but can create small files because the multicore feature makes it difficult to estimate the final size.
Since compression is highly CPU intensive and most large files are already compressed, Duplicati features a filter system, which bypasses compression for files with extensions that are known to be compressed. The file "default-compressed-extensions.txt" contains a list of file extensions, which are stored uncompressed in the output, regardless of what compression module and compression level is used.
There are currently two encryption modules: AESCrypt and GNU Privacy Guard. The encryption and decryption is performed in a file-to-file manner, to avoid leaking any information.
The AESCrypt module is based on the publicly available AESCrypt file format specification, using AES-256 as the encryption algorithm. Each file is encrypted with its own volume encryption key, and each volume contains a HMAC signature to ensure integrity.
The GPG module invokes the GPG binary executable on the host system. Most Linux distributions include GPG as a standard component. On OSX, gpg2 can be installed with any of the package managers. For convenience, the GPG binaries for Windows are included in the installation. It is possible to pass any combination of commandline parameters to GPG, which can be used to choose encryption algorithm and keysizes.
A critical feature of any backup system is to create a complete disk snapshot, such that the system can continue operating while the backup is being created. For most scenarios, it is sufficient to back up all the files present. But in some cases, notably when databases are involved, it is necessary to ensure that a backup does not contain partial writes.
To solve the common scenario, Duplicati happily reads a single block at a time. This makes it extremely unlikely that the data block being read is not consistent (i.e. if another process has partially updated the block being read). This allows Duplicati to read files while they are being processed by other applications. On Linux and OSX, the file locking needs to be checked, so here Duplicati can generally read all files that are open in other applications.
On Windows however, files are often locked when opened by another process. Notably this goes for the Outlook .pst files, which are locked when Outlook is running, making it hard to get read access to it. Fortunately, Windows offers the Volume Shadow-copy Service (VSS) for NTFS based disks (at least Windows Vista and newer). Duplicati supports using VSS by creating a snapshot of the system before running the backup, and then reading data from the snapshot. With VSS, Windows informs other applications that a snapshot is about to be created. VSS compliant applications can register for this event, and flush their memory contents to disk prior to the snapshot being created, and then continue working after the snapshot has been created. This is supported by Outlook and most databases that run on Windows.
When a snapshot has been made, all writes to disk are duplicated, such that the snapshot can access the previous copy of the data, but the applications can continue running and access the updated disk contents. On Linux, the Logical Volume Manager (LVM) also supports snapshots, albeit without the option to allow running applications to flush their memory. Where the VSS support is built in, the LVM support consists of a few bash scripts that can be edited to fit the system.
One unavoidable nuisance with the VSS and LVM support is that they require Administrative (root) privileges. From a security perspective, this makes perfect sense: the snapshot provides unhindered access to all files and folders on the disk. Users needing VSS or LVM support, must make sure they run Duplicati with the required privileges, or the snapshot will fail.
The backends provide an abstraction for a storage method where Duplicati can store data.
Description of how logging is implemented and where logs are stored.