
This repo contains a work-in-progress code for the implementations of commmon contextual bandit algorithms. Check out the blogpost for the details.
Note this project is fresh and totally work in progress.
Built for python 3.5+.
numpy==1.16.4
pandas==0.25.0
scikit-learn==0.21.2
scipy==1.3.0
seaborn==0.9.0
sklearn==0.0
torch==1.1.0
To install prerequisites, preferably in a virtualenv or similiar.
make init
Change the experiment parameters in Makefile.
make run
or tune the hyperparameters yourself (check the args in main.py).
python main.py "synthetic" --n_trials $(N_TRIALS) --n_rounds $(N_ROUNDS)
python main.py "mushroom" --n_trials $(N_TRIALS) --n_rounds $(N_ROUNDS)
python main.py "news" --n_trials $(N_TRIALS) --n_rounds $(N_ROUNDS) --is_acp --grad_clip
The experiment outputs are written to results/.
To plot the results, run make plot.
- LinUCB: Linear UCB algorithm (modified 1).
- Thompson Sampling: Linear Gaussian with a conjugate prior 2.
- Neural Network Policy: A fully-connected neural network with gradient noise.
- Epsilon Greedy
- UCB policy
- Sample Mean Policy
- Random Policy
Check out the blogpost for the details about the datasets
A public UCI machine learnign dataset.
To fetch data, run make fetch-data.
# set up a contextual bandit problem
X, y = load_data(name="mushroom")
context_dim = 117
n_actions = 2
samples = sample_mushroom(X,
y,
n_rounds,
r_eat_good=10.0,
r_eat_bad_lucky=10.0,
r_eat_bad_unlucky=-50.0,
r_eat_bad_lucky_prob=0.7,
r_no_eat=0.0
)
# instantiate policies
egp = EpsilonGreedyPolicy(n_actions, lr=0.001,
epsilon=0.5, eps_anneal_factor=0.001)
ucbp = UCBPolicy(n_actions=n_actions, lr=0.001)
linucbp = LinUCBPolicy(
n_actions=n_actions,
context_dim=context_dim,
delta=0.001,
train_starts_at=100,
train_freq=5
)
lgtsp = LinearGaussianThompsonSamplingPolicy(
n_actions=n_actions,
context_dim=context_dim,
eta_prior=6.0,
lambda_prior=0.25,
train_starts_at=100,
posterior_update_freq=5,
lr = 0.05)
policies = [egp, ucbp, linucbp, lgtsp]
policy_names = ["egp", "ucbp", "linucbp", "lgtsp"]
# simulate a bandit over n_rounds steps
results = simulate_cb(samples, n_rounds, policies)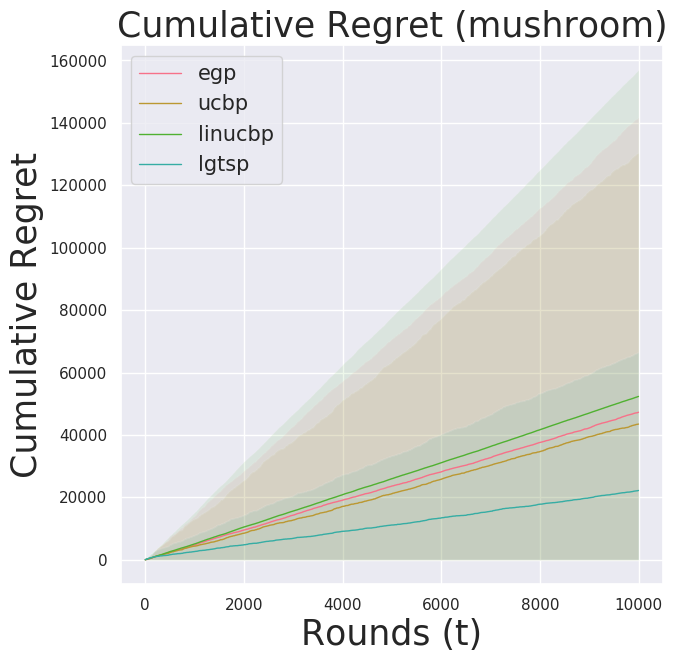
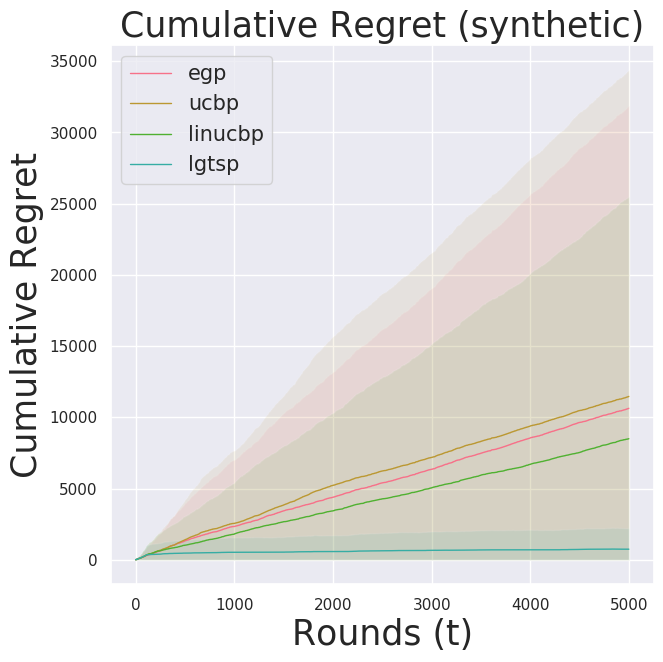
Available built-in.
You need to make a request to gain access. For necessary data preprocessing, check out datautils.news.db_tools.
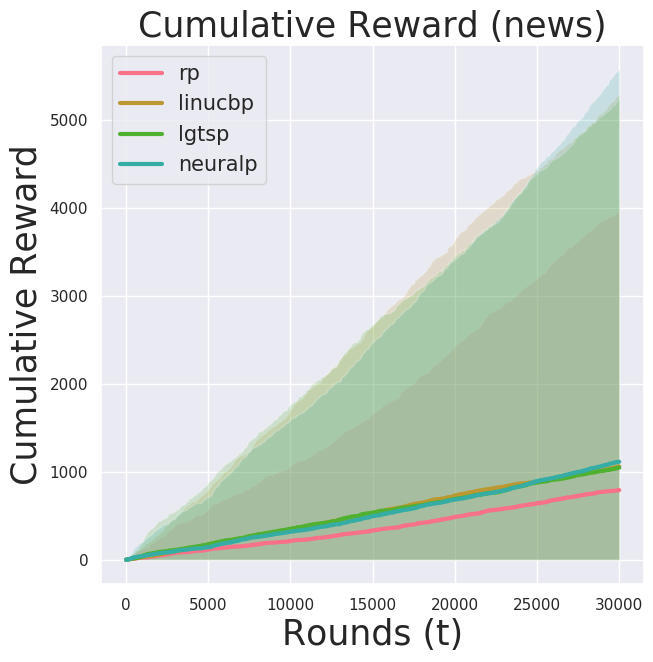
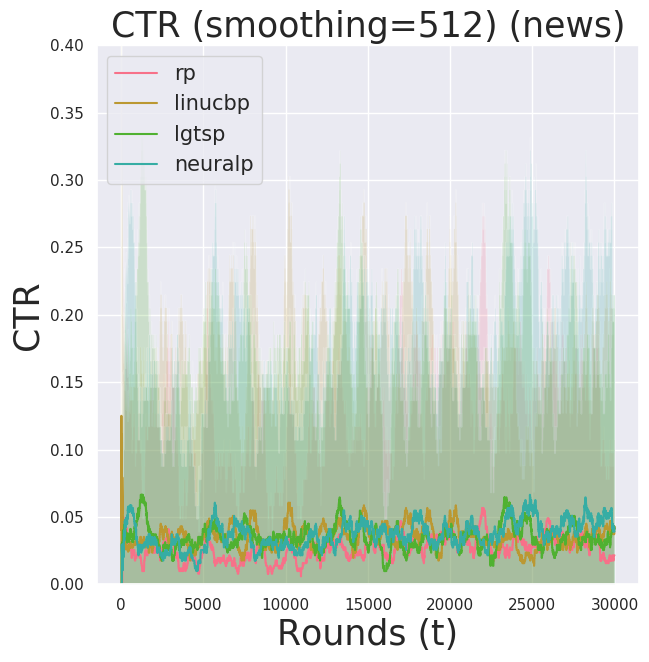
make test