{kind=link}
Code from ``Early MFCC And HPCP Fusion for Robust Cover Song Identification'' by Chris Tralie. This code demonstrates how it is possible to combine complementary features using Similarity Network Fusion (a graph cross-diffusion algorithm) before alignment to improve accuracy.
First, you will need to install the dependencies
- numpy/scipy/matplotlib
- librosa: Used for audio reading, dynamic programming beat tracking, MFCCs
- Essentia with Python bindings. Used for HPCP features
- Madmom (optional): State of the art beat tracking, best if only one beat level is used
Once you have the dependencies installed, you can checkout the code
git clone https://github.com/ctralie/GeometricCoverSongs.git
cd GeometricCoverSongsYou will also need to compile the C files used for Smith Waterman sequence alignment
cd SequenceAlignment
python setup.py build_ext --inplaceThe file SongComparator.py is a quickstart for running the pipeline on a pair of songs. The code will run and output cross-similarity matrices and Smith Waterman matrices for HPCPs, MFCCs, MFCC SSMs, and similarity fusion on all of the above. Right now, it is set to compare an example from the Covers80 dataset (see below), but you can modify the main function to load in any two songs of your choosing. One of the example plots for a song in the Covers80 dataset is shown below
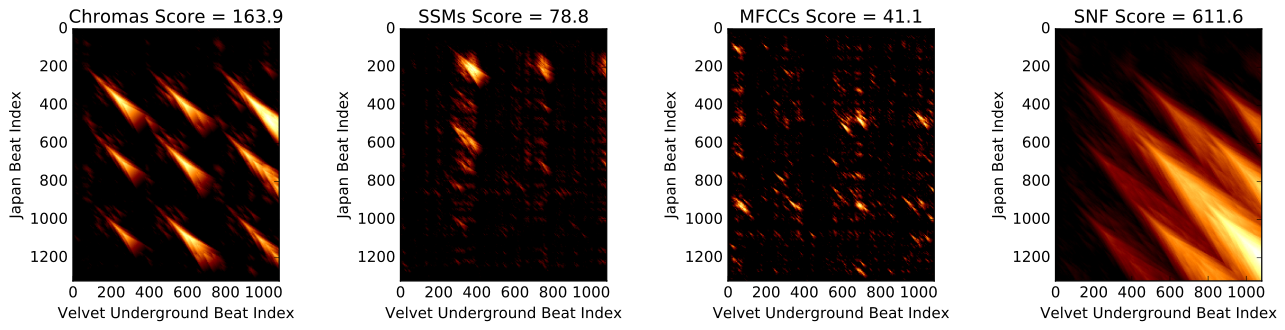
The file CSMViewer/CrossSimilarityExtractor.py can be used to compare two songs and view their alignment using different feature sets in a GUI. For example, the following run will compare a song called "MJBad.mp3" to a file called "AAFBad.mp3" and save the result in "SmoothCriminal.json," using the artist names "Michael Jackson" and "Alien Ant Farm"
python CrossSimilarityExtractor.py --filename1 MJBad.mp3 --filename2 AAFBad.mp3 --jsonfilename SmoothCriminal.json --artist1 "Michael Jackson" --artist2 "Alien Ant Farm"For a full list of options, please type
python CrossSimilarityExtractor.py --helpOnce you have run this script, you can open the generated JSON file in CSMViewer/CrossSimilarityGUI.html (or at http://www.covers1000.net/demo.html). When you hit "play" in this GUI, you can jump back and forth between two songs by left clicking and right clicking on different pixels on the cross-similarity matrix. You can try this with different feature sets to see which features pick up on which types of musical expressions more effectively (e.g. Chroma will work well for songs that are melodic, but not for hip hop songs, and similarity network fusion (SNF) will usually work better than all of them individually).
Covers80 Dataset
click here to download the Covers80 dataset (164MB). Extract the covers32k directory at the root of this repository. Then you can run the file Covers80.py to replicate the experiments reported in the paper. The file will output an HTML table with mean rank, mean reciprocal rank, median rank, and covers80 score (see paper for more details).
NOTE: By default in Covers80.py, the TempoLevels variable is set as
TempoLevels = [60, 120, 180]which are the three tempo biases used in the dynamic programming beat tracker from librosa. If instead, you change it to
TempoLevels = [0]It will use just one level from Madmom (which requires the library to be installed). The latter is state of the art if only one beat level is being used, but the overall performance is inferior to trying all three levels with the dynamic programming beat tracker (though the code is much faster).
Covers1000 Dataset
It is also possible to run the new Covers1000 dataset that comes along with this paper using the Cover1000.py file. Since computation takes so long, this file is designed to be run on a compute cluster. First, you need to download all of the .zip files from http://www.covers1000.net/dataset.html and extract them all to a folder named Covers1000 at the root of this repository. Then, you need to run Covers1000.py many different times; first to extract block features, then to do pairwise comparisons. To extract the features, run the file as follows
python covers1000.py 1 0 <songIdx> <Kappa> <BeatsPerBlock> <doMadmom>"where is the song number for which to compute the features (0-999), Kappa is the fraction of nearest neighbors when making binary cross-similarity matrices (usually 0.1), BeatsPerBlock is the number of beats per block for all of the blocked features (usually 20), and doMadmom is 1 if doing Madmom beats only and 0 if doing 3 levels in dynamic programming beat tracker.
Once you have computed blocked features for all 999 songs, it's time to compare them all in batches. Run the file as follows
python covers1000.py 0 <NPerBatch> <BatchNum> <Kappa> <BeatsPerBlock> <doMadmom>Where NPerBatch gives the size of a patch in the all pairs similarity score matrix, and BatcNum gives the batch to compute. For instance, if NPerBatch = 20, then compare 20 songs with 20 other songs, and since there are 1000 songs total, there are (1000/20)x(1000/20) = 2500 total of these batches to compare. Once all batches have been completed, you can run the file MIREX.py (see below) with the collection and query list "covers1000collection.txt" and the scratch directory "Covers1000Scratch" to fuse all of them together in one matrix of all pairs of similarities (NOTE: This will take no time once covers1000.py has been run; it just saves code to use MIREX.py to fuse all of the blocks into one batch since that file also runs all pairs of comparisons in batch blocks).
There is a file MIREX.py for making batch tests convenient on all pairs of songs. The command calling format is the same as specified in the cover song identification wiki. Namely, run the following command at the root of the directory:
python MIREX.py <collection_list_file> <query_list_file> <working_directory> <output_file> <num threads>For example
python MIREX.py collections.list queries.list ScratchDir Results.txt 8will run all pairs comparisons using songs in collections.list and queries.list and using "ScratchDir" as the scratch directory, using 8 threads for parallel computation. After it's finished, 'Results.txt' will contain the table of scores between songs, formatted to specification.