Deploy automated machine learning (AutoML) as a service using Flask, for both pipeline training and pipeline serving.
The framework implements a fully automated time series classification pipeline, automating both feature engineering and model selection and optimization using Python libraries, TPOT and tsfresh.
Check out the blog post for more info.

Resources:
- TPOT– Automated feature preprocessing and model optimization tool
- tsfresh– Automated time series feature engineering and selection
- Flask– A web development microframework for Python
The application exposes both model training and model predictions with a RESTful API. For model training, input data and labels are sent via POST request, a pipeline is trained, and model predictions are accessible via a prediction route.
Pipelines are stored to a unique key, and thus, live predictions can be made on the same data using different feature construction and modeling pipelines.
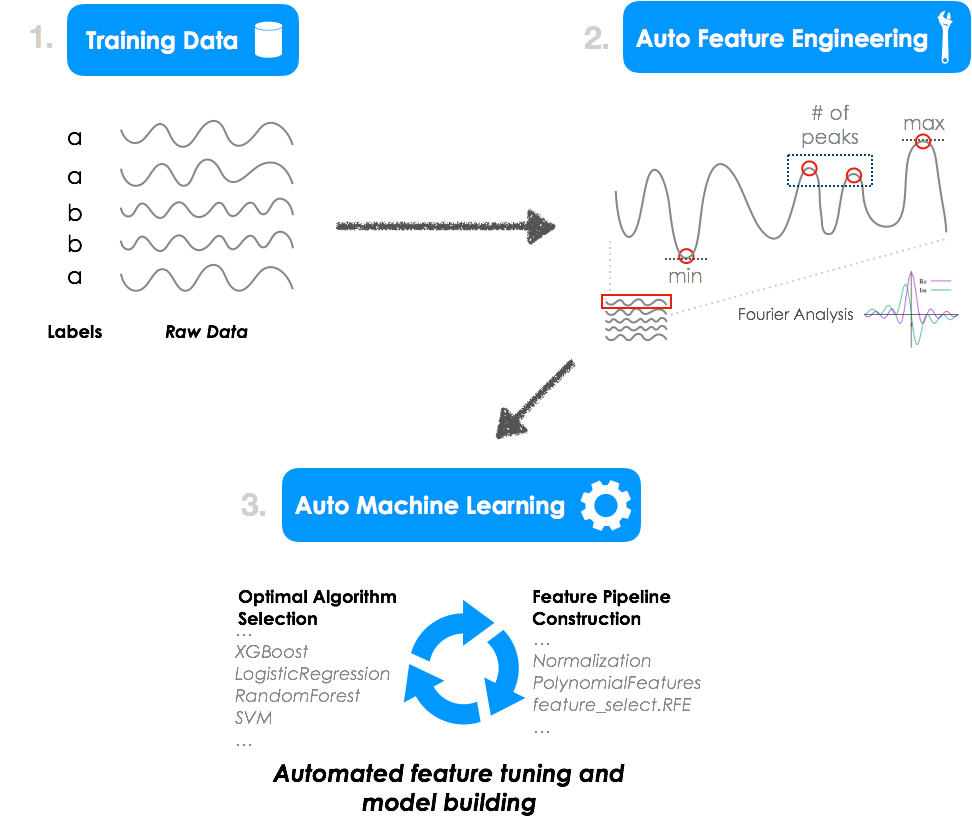
An automated pipeline for time-series classification.
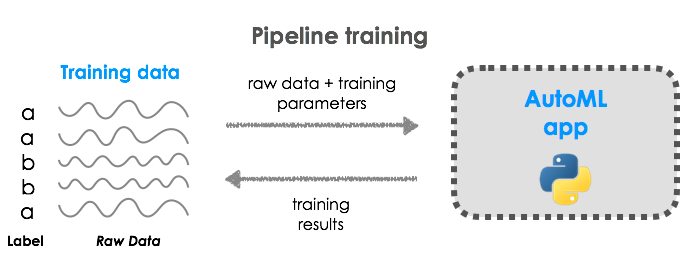

View the Jupyter Notebook for an example.
# deploy locally
python automl_service.py# deploy on cloud foundry
cf pushTrain a pipeline:
train_url = 'http://0.0.0.0:8080/train_pipeline'
train_files = {'raw_data': open('data/data_train.json', 'rb'),
'labels' : open('data/label_train.json', 'rb'),
'params' : open('parameters/train_parameters_model2.yml', 'rb')}
# post request to train pipeline
r_train = requests.post(train_url, files=train_files)
result_df = json.loads(r_train.json())returns:
{'featureEngParams': {'default_fc_parameters': "['median', 'minimum', 'standard_deviation',
'sum_values', 'variance', 'maximum',
'length', 'mean']",
'impute_function': 'impute',
...},
'mean_cv_accuracy': 0.865,
'mean_cv_roc_auc': 0.932,
'modelId': 1,
'modelType': "Pipeline(steps=[('stackingestimator', StackingEstimator(estimator=LinearSVC(...))),
('logisticregression', LogisticRegressionClassifier(solver='liblinear',...))])"
'trainShape': [1647, 8],
'trainTime': 1.953}Serve pipeline predictions:
serve_url = 'http://0.0.0.0:8080/serve_prediction'
test_files = {'raw_data': open('data/data_test.json', 'rb'),
'params' : open('parameters/test_parameters_model2.yml', 'rb')}
# post request to serve predictions from trained pipeline
r_test = requests.post(serve_url, files=test_files)
result = pd.read_json(r_test.json()).set_index('id')| example_id | prediction |
|---|---|
| 1 | 0.853 |
| 2 | 0.991 |
| 3 | 0.060 |
| 4 | 0.995 |
| 5 | 0.003 |
| ... | ... |
View all trained models:
r = requests.get('http://0.0.0.0:8080/models')
pipelines = json.loads(r.json()){'1':
{'mean_cv_accuracy': 0.873,
'modelType': "RandomForestClassifier(...),
...},
'2':
{'mean_cv_accuracy': 0.895,
'modelType': "GradientBoostingClassifier(...),
...},
'3':
{'mean_cv_accuracy': 0.859,
'modelType': "LogisticRegressionClassifier(...),
...},
...}Supply a user argument for the host.
# use local app
py.test --host http://0.0.0.0:8080# use cloud-deployed app
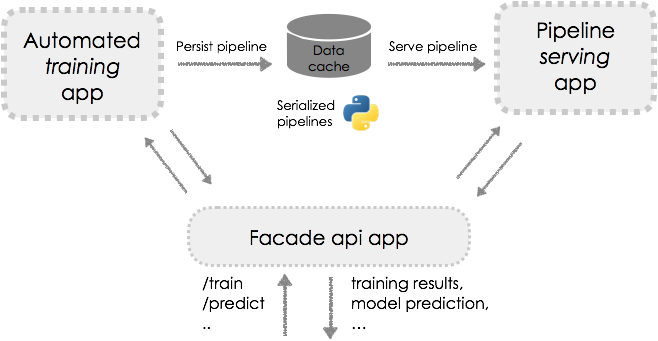
py.test --host http://ROUTE-HEREFor production, I would suggest splitting training and serving into seperate applications, and incorporating a fascade API. Also it would be best to use a shared cache such as Redis or Pivotal Cloud Cache to allow other applications and multiple instances of the pipeline to access the trained model. Here is a potential architecture.
Chris Rawles