This is an experimental stream processing system to test different big data technologies. The current version is built using Scala and Akka.
Wikipedia recent changes IRC channels for different countries - https://meta.wikimedia.org/wiki/IRC/Channels#Raw_feeds
Java 1.8 is the target JVM version.
You need to have SBT and Scala installed on your system.
Krampus requires SBT 0.13.13 or higher.
Currently Akka based pipeline is the only implementation of this system (see below).
- Apache Kafka is used as a data ingestion bus.
- Avro is used as the data binary protocol.
- Akka is used as the toolkit of choice for all event processing components.
- Spark is used for building machine learning models for anomaly detection.
- Grafana is used for visualization.
- Cassandra is used to store the Spark ML models.
- Docker is used to contanerize all these components in order to start all processing elements on one host machine.
- Play! Framework is the technology the web app is built with.
./build-all.sh
docker-compose up
Krampus works as follows:
- krampus-source component reads all the Wikipedia recent changes channel and writes the data to the shared channel.
- krampus-producer simply makes 'tail -f' on this shared channel, reads the data, converts Wikipedia data to Avro binary messages and pushes these messages to the Apache Kafka topic 'wikidata'.
- krampus-metrics-aggregator reads all the data from the 'wikidata' Kafka topic, makes aggregations (counters) and writes the stats to the graphite.
- krampus-processor reads all entries from the 'wikidata' Kafka topic and stores every message to Cassandra (this data will be consumed later by the ML module).
- krampus-web-app is a web interface to the pipeline - you can easily look into all wikipedia channels in real time.
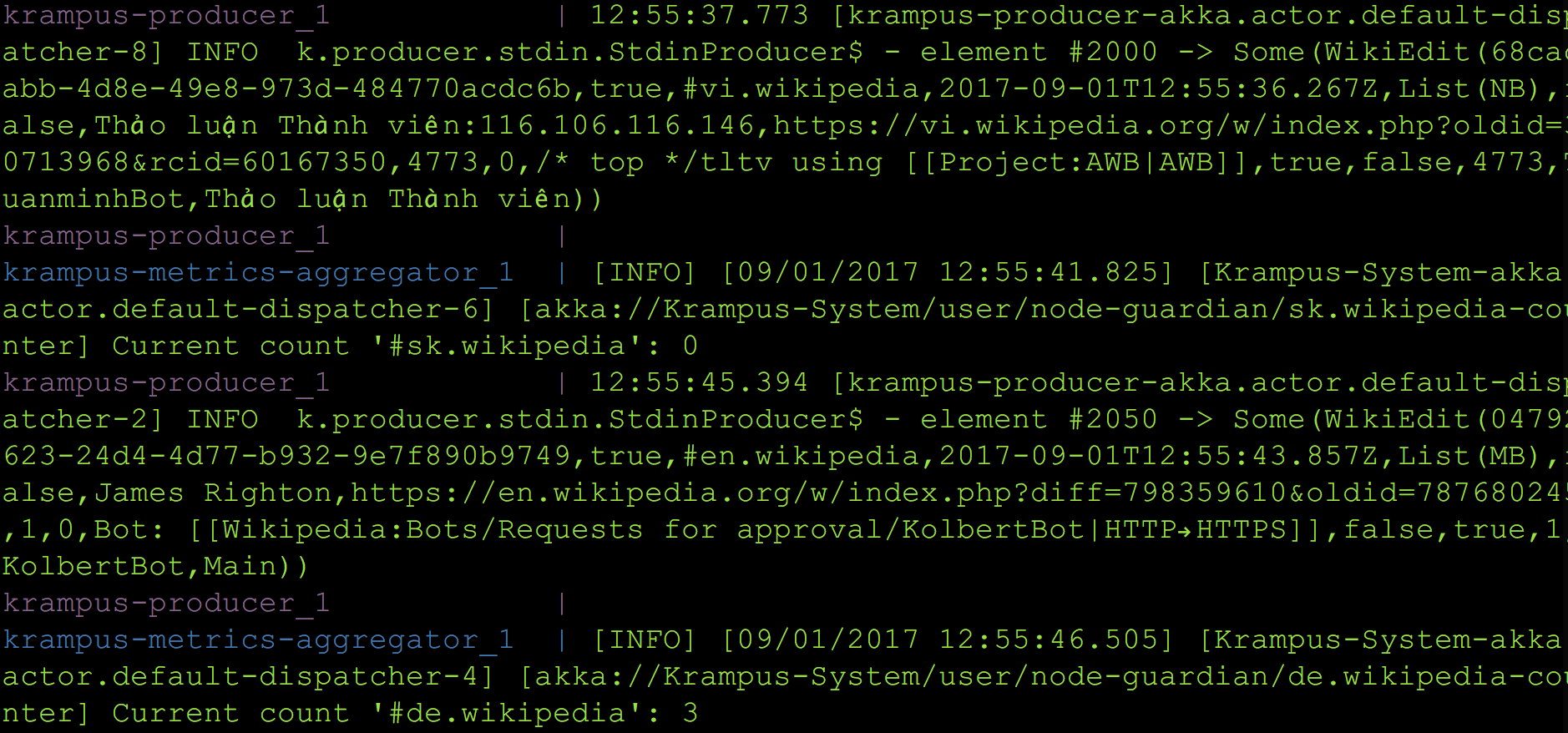
After start you should see log lines like this in your terminal:
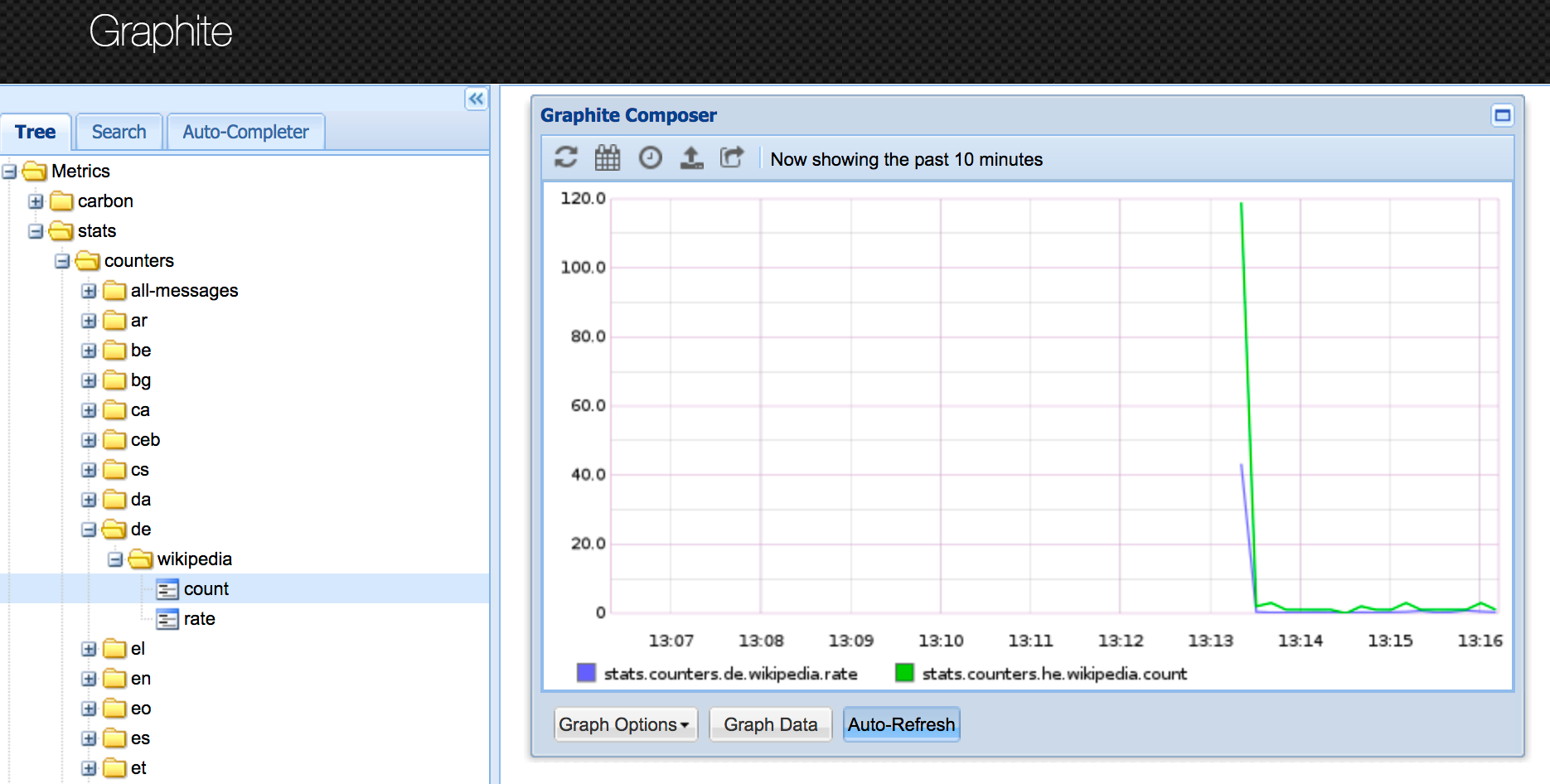
- localhost:81 - this is your Graphite instance
-
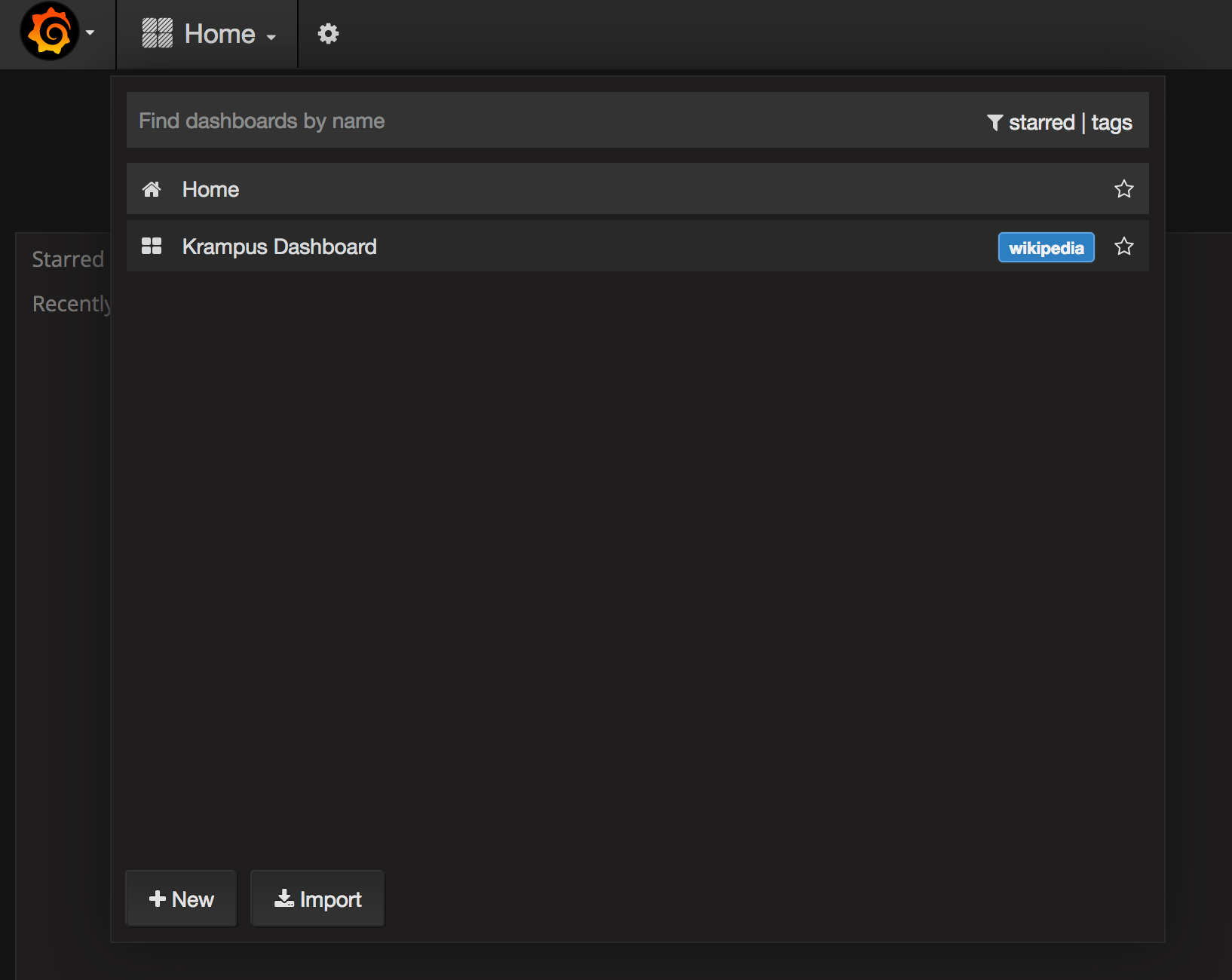
localhost:80 - this is your Grafana instance.
-
Login/password: admin/admin
-
Select Krampus Dashboard
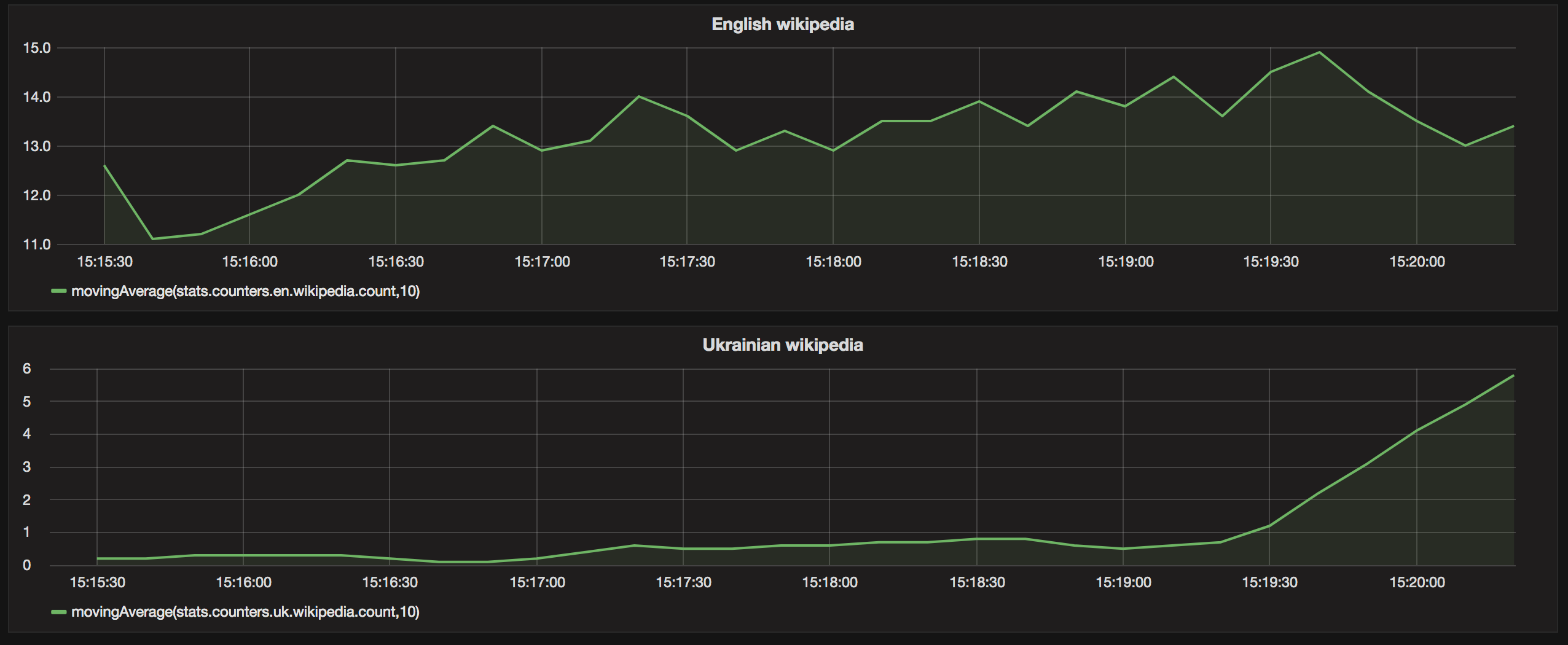
-
You should see something like this:
-
-
localhost:9000 - if you point your web browser at this URL you should see something like this:
This is the krampus web app! You can switch the channel name on the UI or in URL and see all the channel changes in real time!