[news | 22 Aug 2021] SapBERT is integrated into NVIDIA's deep learning toolkit NeMo as its entity linking module (thank you NVIDIA!). You can play with it in this google colab.
This repo holds code, data, and pretrained weights for (1) the SapBERT model presented in our NAACL 2021 paper: Self-Alignment Pretraining for Biomedical Entity Representations; (2) the cross-lingual SapBERT and a cross-lingual biomedical entity linking benchmark (XL-BEL) proposed in our ACL 2021 paper: Learning Domain-Specialised Representations for Cross-Lingual Biomedical Entity Linking.
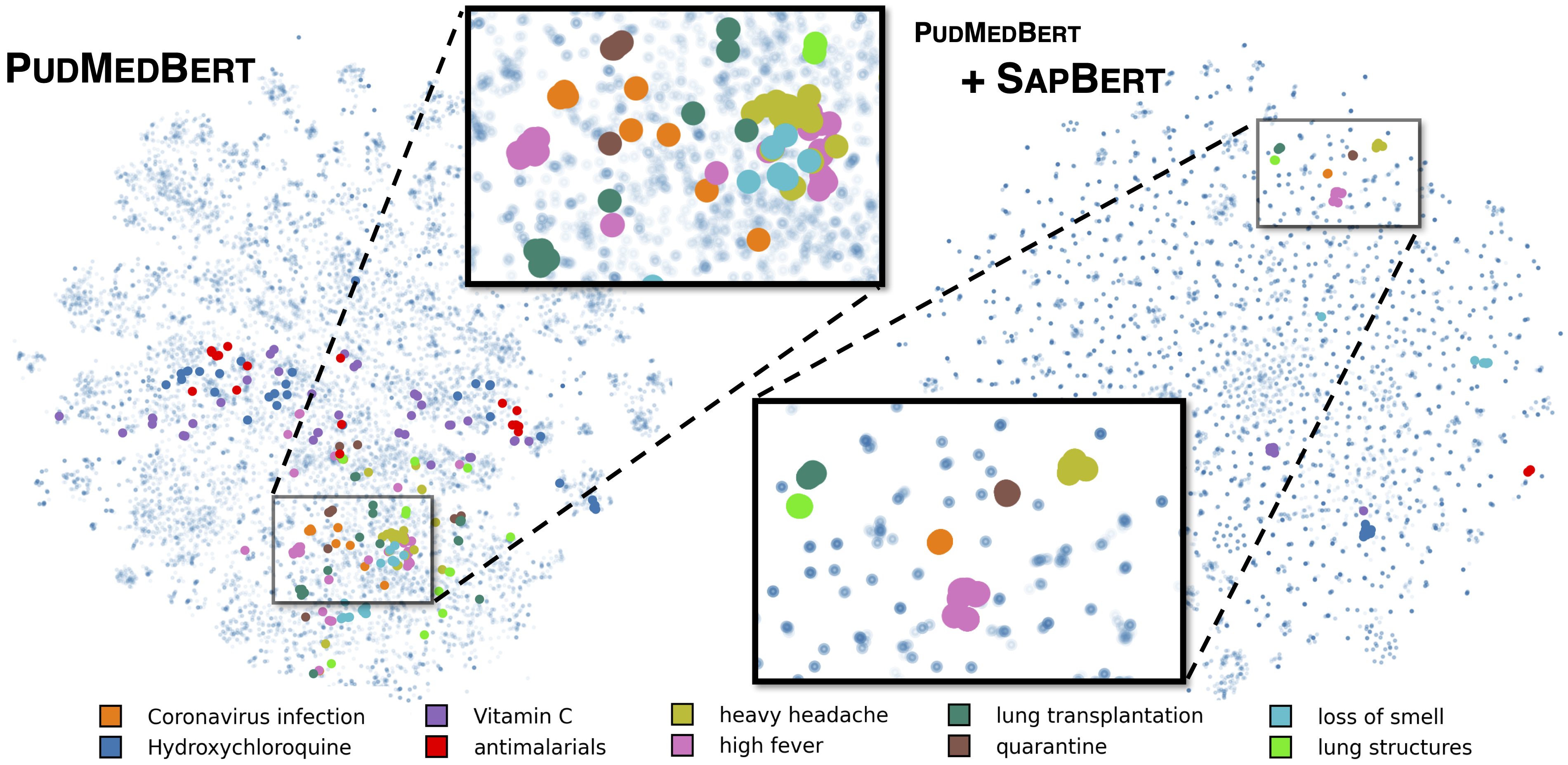
English Models: [SapBERT] and [SapBERT-mean-token]
Standard SapBERT as described in [Liu et al., NAACL 2021]. Trained with UMLS 2020AA (English only), using microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext as the base model. For [SapBERT], use [CLS] (before pooler) as the representation of the input; for [SapBERT-mean-token], use mean-pooling across all tokens.
Cross-Lingual Models: [SapBERT-XLMR] and [SapBERT-XLMR-large]
Cross-lingual SapBERT as described in [Liu et al., ACL 2021]. Trained with UMLS 2020AB (all languages), using xlm-roberta-base/xlm-roberta-large as the base model. Use [CLS] (before pooler) as the representation of the input.
The code is tested with python 3.8, torch 1.7.0 and huggingface transformers 4.4.2. Please view requirements.txt for more details.
The following script converts a list of strings (entity names) into embeddings.
import numpy as np
import torch
from tqdm.auto import tqdm
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("cambridgeltl/SapBERT-from-PubMedBERT-fulltext")
model = AutoModel.from_pretrained("cambridgeltl/SapBERT-from-PubMedBERT-fulltext").cuda()
# replace with your own list of entity names
all_names = ["covid-19", "Coronavirus infection", "high fever", "Tumor of posterior wall of oropharynx"]
bs = 128 # batch size during inference
all_embs = []
for i in tqdm(np.arange(0, len(all_names), bs)):
toks = tokenizer.batch_encode_plus(all_names[i:i+bs],
padding="max_length",
max_length=25,
truncation=True,
return_tensors="pt")
toks_cuda = {}
for k,v in toks.items():
toks_cuda[k] = v.cuda()
cls_rep = model(**toks_cuda)[0][:,0,:] # use CLS representation as the embedding
all_embs.append(cls_rep.cpu().detach().numpy())
all_embs = np.concatenate(all_embs, axis=0)Please see inference/inference_on_snomed.ipynb for a more extensive inference example.
Extract training data from UMLS as insrtructed in training_data/generate_pretraining_data.ipynb (we cannot directly release the training file due to licensing issues).
Run:
>> cd train/
>> ./pretrain.sh 0,1 where 0,1 specifies the GPU devices.
For finetuning on your customised dataset, generate data in the format of
concept_id || entity_name_1 || entity_name_2
...
where entity_name_1 and entity_name_2 are synonym pairs (belonging to the same concept concept_id) sampled from a given labelled dataset. If one concept is associated with multiple entity names in the dataset, you could traverse all the pairwise combinations.
For cross-lingual SAP-tuning with general domain parallel data (muse, wiki titles, or both), the data can be found in training_data/general_domain_parallel_data/. An example script: train/xling_train.sh.
For evaluation (both monlingual and cross-lingual), please view evaluation/README.md for details. evaluation/xl_bel/ contains the XL-BEL benchmark proposed in [Liu et al., ACL 2021].
SapBERT:
@inproceedings{liu2021self,
title={Self-Alignment Pretraining for Biomedical Entity Representations},
author={Liu, Fangyu and Shareghi, Ehsan and Meng, Zaiqiao and Basaldella, Marco and Collier, Nigel},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
pages={4228--4238},
month = jun,
year={2021}
}Cross-lingual SapBERT and XL-BEL:
@inproceedings{liu2021learning,
title={Learning Domain-Specialised Representations for Cross-Lingual Biomedical Entity Linking},
author={Liu, Fangyu and Vuli{\'c}, Ivan and Korhonen, Anna and Collier, Nigel},
booktitle={Proceedings of ACL-IJCNLP 2021},
pages = {565--574},
month = aug,
year={2021}
}Parts of the code are modified from BioSyn. We appreciate the authors for making BioSyn open-sourced.
SapBERT is MIT licensed. See the LICENSE file for details.