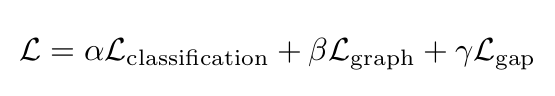This is my implementation of the HUSE paper in PyTorch.
https://arxiv.org/pdf/1911.05978.pdf
author: arpytanshu@gmail.com
50k products accompanied along with its image, text and class name.
To apply transforms as we feed data into the model, we make a PyTorch DataSet.
- A tfidf-vectorizer fitted on all text sample. { self.tokenizer }
- Mapping from class_names to class_index
The Dataset reads in the image, text and labels for each sample and applies the following transformations to them:
- Transformations on Image
- Resize [ to 224x224, (as expected by pre-trained torchvision models) ]
- Random Contrast, Brightness, Hue, Saturation
- Random Horizontal Flip
- Normalizes each channel (as expected by pre-trained torchvision models)
- Cleans text { !TODO }
- Tokenizes the text and makes input_ids for getting BERT embeddings for text
- Gets the tfidf vector for text
- image : torch tensor of shape 3 x 224 x 224
- bert_input_ids : torch tensor ( input ids corresponding to text tokens, created by BertTokenizer)
- tfidf_vector : torch tensor (tfidf feature vectors of shape self.tokenizer.num_words)
- labels : torch tensor ( index corresponding to the class name )
To create a Semantic Graph, we take in the class_name to class_index mapping.
This mapping should be obtained from the Dataset object.
tr_dataset = utils.NAPDataset(tr_df.copy(),
image_path = IMAGE_PATH,
train_mode = True,
bert_model_name = BERT_MODEL_NAME,
transforms = utils.image_transforms['train'],
tokenizer = None)
classes_map = tr_dataset.classes_map
classes_map
{ 'accessories<belts<wide': 0,
'accessories<books<books': 1,
...
'shoes<pumps<high heel': 41,
'shoes<pumps<mid heel': 42
...
}
A = SemanticGraph(classes_map)
To get the Embeddings for each class name, we use Bert Embeddings for the 3 level of hierarchy in class names, and concatenate them together.
If a hierarchy has multiple words, its embeddings are mean pooled across the tokens.
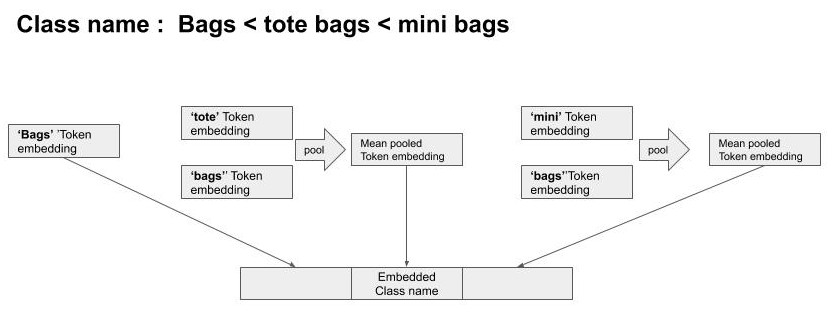
Once we get the Embeddings for the class_names, we fill in the Semantic Graph at position A[i][j] with cosine distance between embeddings of class_name[i] & class_name[j].
For getting Image & Text embeddings for the data, we use pre-trained models from torchvision and huggingface's transformers.
A list of model names are added in pretrained_imagenet_models and pretrained_bert_models.
We furthur define 2 methods named ImageEmbeddingModel & BertEmbeddingModel.
These methods
- Return a pretrained image model and pertrained bert model respectively.
- All parameters for both of these models are frozen.
- They return an integer
out_dimension, which is the size of the embedding that the model is expected to return.
These methods can be easily modified to support different models as well, without changing the rest of the code.
NOTE:
The HUSE paper described the text description for each sample (text modal)
to be much greater than 512 tokens (which is the limit for BERT) for the dataset it used { UPMC Food-101 } and thus required to extract 512 most important tokens from the text description.
However the textual description of the samples in the dataset shared with us is much smaller than 512, thus eliminating the need for such token clipping.
A configuration class to hold configuration attributes for the HUSE model.
By default:
- Some parameters are left to None, and are populated later.
- Some parameters have values from the HUSE paper.
- Some parameters have a dummy value.
The ImageTower module is modelled exactly as described in the HUSE paper.
The TextTower module is modelled exactly as described in the HUSE paper.
Uses instances of TextTower, ImageTower & a SharedLayer to completely model the HUSE model as described in the HUSE paper.
This model holds all the learnable parameters.
The HUSE paper describes 3 loss functions that are to be used so that the Embedding space has the required properties.
This is the softmax cross entropy loss. Implementing this in PyTorch is a 1-liner.
This loss tries to minimize the universal embedding gap when an embedding for the same sample is created using either it's text representation, or it's image representation.
For CrossModalLoss, we get the universal embeddings from the HUSE_model using only either image or text at once.
- For obtaining universal embedding for text, we usa a Zero matrix { of appropriate shape } for representing the image embedding.
- For obtaining universal embedding for image, we usa a Zero matrix { of appropriate shape } for representing the text embedding.
To get the loss, we take the cosine distance between them. Since these embeddings are coming from the same sample ( and only different modal ), minimizing the distance between them bring the embeddings from the 2 modals closer in universal embedding space.
For demonstrating how I implemented this loss, here is a simple example:
batch_size = 2
We have 2 universal embedding and 2 labels in this batch.
UE = [UE_1 UE_2] # universal embeddings for batch samples
L = [C_1 C_2] # index corresponding to the class names of samples
To calculate pairwise_embedding_distance, we create pairs of
samples in batch and calc their cosine distances.
UE_m = UE.repeat_interleave(2, -1) # [ UE_1 UE_1 UE_2 UE_2 ]
UE_n = UE.repeat(2,1) # [ UE_1 UE_2 UE_1 UE_2 ]
pairwise_embedding_distance = distance( UE_m, UE_n )
Similarly pairwise label index are used to index into the Semantic Graph A
L_m = labels.repeat_interleave(2, -1) # [ C_1 C_1 C_2 C_2 ]
L_n = labels.repeat(2,1) # [ C_1 C_2 C_1 C_2 ]
pairwise_class_distance = A[[L_m, L_n]]
'''
-
Once we get
pairwise_embedding_distance&pairwise_class_distance(from the semantic graph), we calculate sigma using the equation:
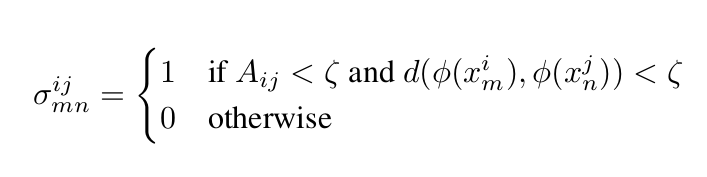
-
For getting the final loss, we again use the equation as describer in the HUSE paper.
loss = Σ ( σ * ( d (U_m,U_n) - Aij )² ) / N²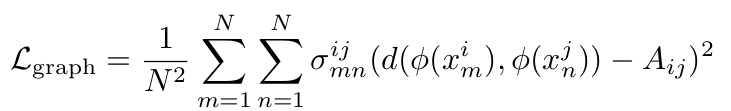
We wrap the 3 Loss modules into another module that also weights the 3 Losses using parameters from the HUSE_config:
- HUSE_config.alpha
- HUSE_config.beta
- HUSE_config.gamma