Prosodically annotated parallel speech corpus generation using dubbed movies.
Dubbed media content is a valuable resource for generating prosodically rich parallel audio corpora. movie2parallelDB automates this process taking in audio tracks and subtitles of a movie and outputting aligned voice segments with text and prosody annotation.
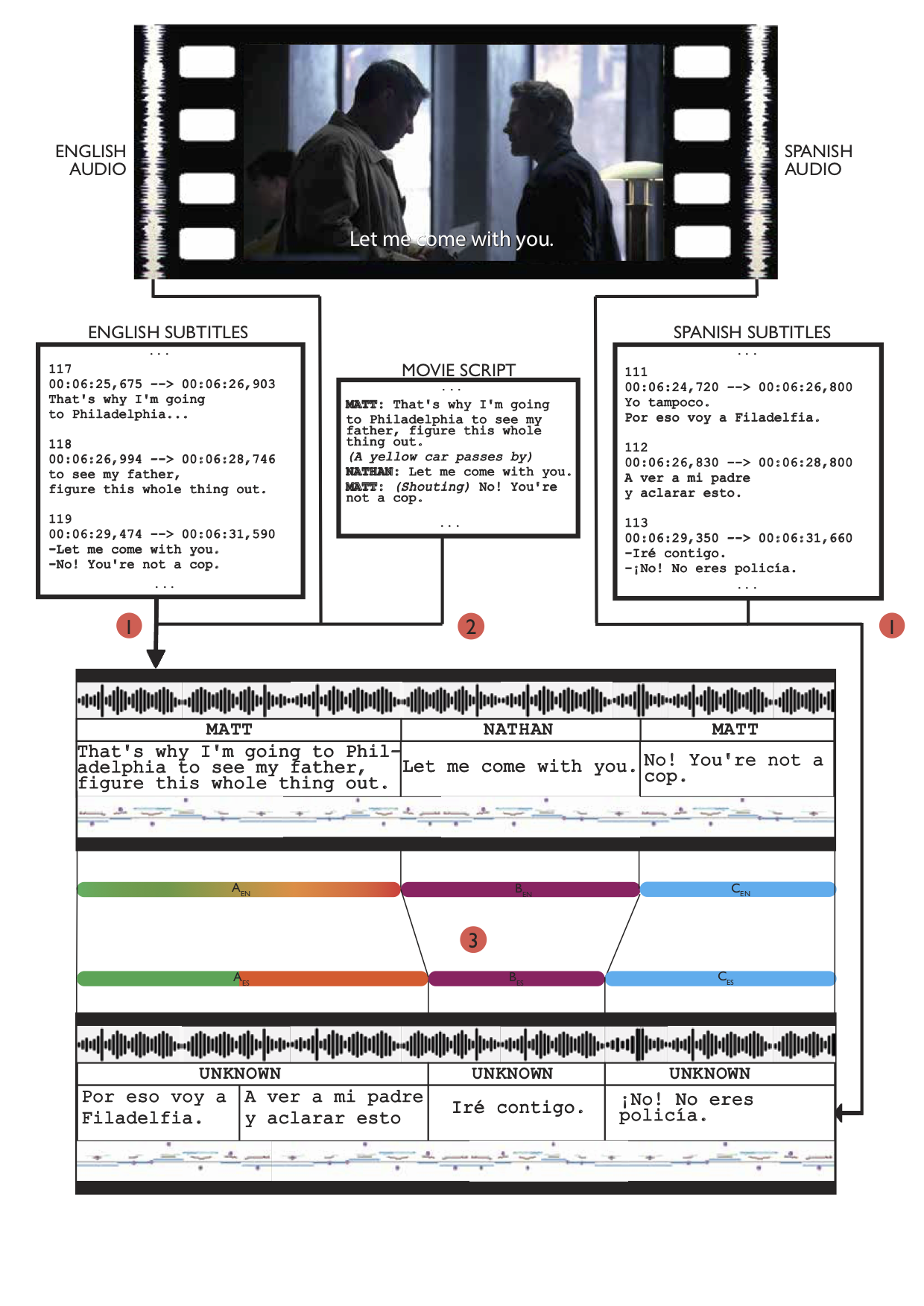
A parallel audio corpus is obtained in three stages: (1) a monolingual step, where audio+text pairs are extracted from the movie in both languages using transcripts and cues in subtitles, (2) paralinguistic feature annotation (speaker information and prosody) and (3) alignment of monolingual material to extract the bilingual segments. Figure below illustrates the whole process on an example portion of a movie.
movie2parallelDB was developed by Alp Öktem during his PhD to create a parallel Spanish-English dubbed movie corpus. It is not maintained or provided with a guarantee.
At the moment, the library is set to work only for this language pair. Contributions are welcome to make it language independent. Mind that the availability of word-alignment models is the main bottleneck in making it work with other languages. A Spanish pronunciation dictionary was created in order to make it work for Spanish.
- Required installations:
- Python 3.x
- Montreal forced aligner
- Praat
- (mkvtoolnix)
Binary and model paths of MFA and Praat should be set in src/paths.py.
- Required Python packages:
- proscript, pydub, pysrt, nltk
To install required packages:
pip install -r requirements.txt
movie2parallelDB works with wav format audio files and srt format subtitles in both languages (original and dubbed) of the media file. MKV type video files often contain multiple audio tracks and subtitle information. mkvinfo can be used to get track information on the video file. Once track id's are known, audio tracks can be extracted using mkvextract tool of mkvtoolnix:
mkvextract <movie-mkv-file> tracks 1:audio_spa 2:audio_eng 3:sub_spa.srt 4:sub_eng.srt
Make sure that subtitles and audio match in both timing and transcription. Dubbing scripts might differ from subtitle transcripts.
Speaker labelling is made possible with the use of script files. Script files contain a speaker turn at each line with the speaker name followed by a colon and then the line. Example of a script can be seen in the figure above.
Monolingual segment extraction can be performed with the script subsegment_movie.py:
python src/subsegment_movie.py -a <audio_eng> -s <sub_eng> -o <output_directory> -l eng -f wav -c <script_eng>
Alternatively, a batch of files specified in a text file can be given to process. Each line in the file should contain the tab separated columns: movie_id, audio_path, srt_path, script_path (optional: put NA if not available), language_id. See data/heroes/episode_list_eng.txt for a sample.
python src/subsegment_movie.py -i <process-list_eng> -o <output_directory> -l eng -f wav -c <script_eng>
Parallel corpus generation is performed using parallel text files that contain path information in the two languages:
python src/movie2parallelDB.py -e <process-list_eng> -s <process-list_spa> -o <output_directory> -f wav
This process executes the monolingual process for both languages and then aligns the extracted segments.
Sample data is placed under data/heroes directory. Example running scripts that process these are provided in sample_run.sh.
Heroes corpus is generated using this library.
Sample data contains an excerpt from the TV series Heroes produced by Tailwind Productions, NBC Universal Television Studio (2006-2007) and Universal Media Studios (2007-2010) and from the film "The Man Who Knew Too Much" (1956) from Universal Pictures.
Please keep in mind that processing of copyrighted material must comply with Fair use principals. Corpora created with this software must be used within research and educational purposes.
Final version of this library is explained in Iberspeech 2018: Paper link
@inproceedings{Öktem2018,
author={Alp Öktem and Mireia Farrús and Antonio Bonafonte},
title={{Bilingual Prosodic Dataset Compilation for Spoken Language Translation}},
year=2018,
booktitle={Proc. IberSPEECH 2018},
pages={20--24},
doi={10.21437/IberSPEECH.2018-5},
url={http://dx.doi.org/10.21437/IberSPEECH.2018-5}
}
This work is originally introduced in BUCC workshop under ACL 2017: Paper link
@inproceedings{movie2parallelDB,
author = {Alp Oktem and Mireia Farrus and Leo Wanner},
title = {Automatic extraction of parallel speech corpora from dubbed movies},
booktitle = {Proceedings of the 10th Workshop on Building and Using Comparable Corpora (BUCC)},
year = {2017},
address = {Vancouver, Canada}
}
(See README_beta.md for instructions of the earlier version)