This codebase covers the MULE (Musicset Unsupervised Large Embedding) model and supporting materials for the ISMIR 2022 publication:
Supervised and Unsupervised Learning of Audio Representations for Music Understanding, M. C. McCallum, F. Korzeniowski, S. Oramas, F. Gouyon, A. F. Ehmann.
It is intended for research purposes to better understand the results in the paper, and enable further research into audio embeddings, or downstream models that rely on audio or multimodal understanding of music content.
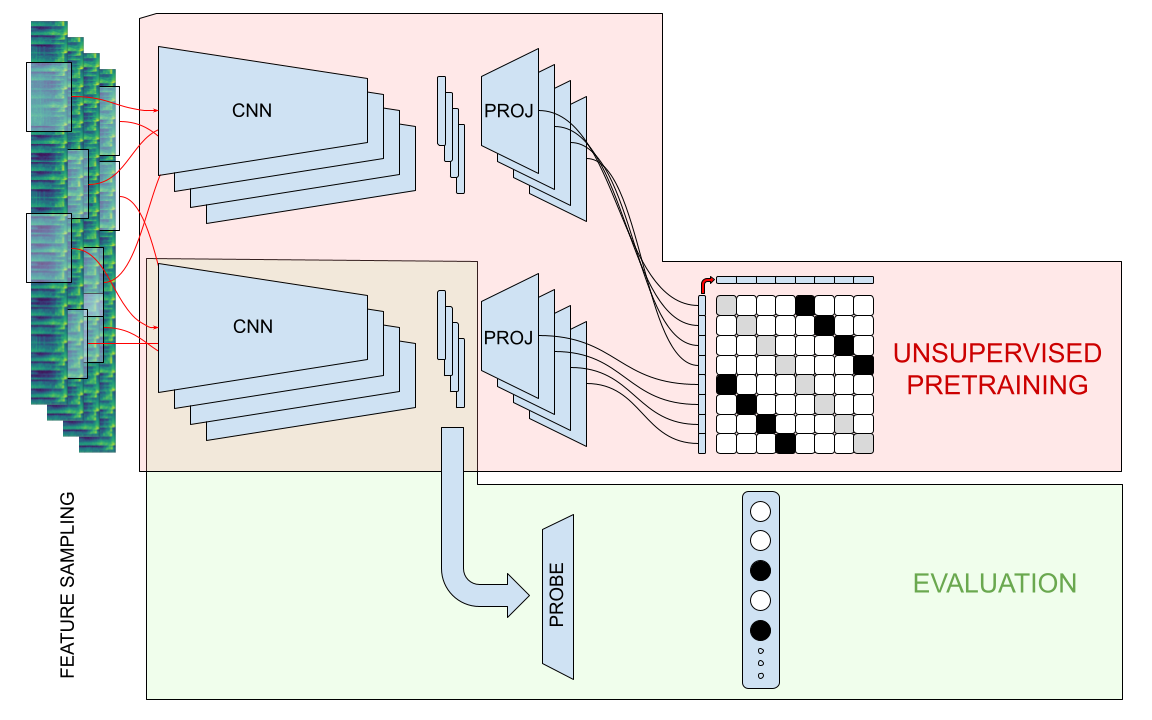
An overview of the training process for the MULE model is depicted below.
The mule python module is licensed under the GNU GPL 3.0 license.
The supporting data, including:
- MULE model weights
- Additional results
- Model and probe hyperparameter configurations
are licensed under the CC BY-NC 4.0 license.
MULE is hosted on pypi and may be installed with pip:
pip install sxmp-mule
NOTE: This module requires FFMpeg to read audio files, which may be downloaded here.
NOTE: MULE model weights are stored in this repository using git lfs. In order to use the pretrained MULE model, first ensure that git lfs is installed as described here. For example, on MacOS:
brew install git-lfs
git lfs install
MULE uses SCOOCH as a configuration interface, which relies on yaml configuration files. To see an example configuration for running mule, please check out the provided configuration here.
In order to run the pretrained MULE model on a local audio file, you will need to clone this git repository which contains both the model weights and a SCOOCH configuration with which to run it:
git clone https://github.com/PandoraMedia/music-audio-representations.git
cd ./music-audio-representations
git lfs pull
mule analyze --config ./supporting_data/configs/mule_embedding_timeline.yml -i /path/to/input/test_audio.wav -o /path/to/output/embedding.npy
NOTE: At this point you can ensure that the large model file was successfully downloaded from Git LFS by looking at the size of the files in the ./supporting_data/model/ directory. The model is approximately 250MB.
The SCOOCH configuration ./supporting_data/configs/mule_embedding_timeline.yml specifies all analysis parameters including where to find the model weights.
The output of the commands above is a timeline of MULE embeddings for the provided audio file test.wav sampled every 2 seconds, e.g., for a 6 second audio file:
In [1]: import numpy as np
In [2]: data = np.load('embedding.npy')
In [3]: data.shape
Out[3]: (1728, 3)
In [4]: data
Out[4]:
array([[ 0.02401832, 0.07947006, 0.0514956 ],
[-0.07212289, -0.02800103, -0.0738833 ],
[-0.12109657, -0.06731056, 0.07671715],
...,
[ 0.02302092, -0.0231873 , -0.0185051 ],
[-0.0355757 , -0.00670745, -0.02728019],
[-0.10647963, -0.09881161, -0.07594919]], dtype=float32)
In addition to the python mule module, this repository provides more detailed results and hyperparameter configurations for the probes trained in the aforementioned publication.
Results tables can be found in ./supporting_data/results.
SCOOCH hyperparameter configurations for the experiments in the publication can be found in ./supporting_data/configs/probes.