Repositório contendo conjunto de dados utilizados para treino e teste dos algoritmos de machine learning: Naive Bayes, SVM, Logistic Regression, Decision Tree e BERT. Esse projeto faz parte do estudo realizado para o meu trabalho de conclusâo de curso no departamento de computação na Universidade Federal de Sergipe.

Neste estudo foi realizado a coleta de mensagens do Twitter no período de 1 de fevereido de 2020 até 31 de Janeiro de 2021. Esses conjunto de dados foi utilizado para gerar um subset de treino e teste a partir da identificação de emojis, o restante foi utilizado para análise geral dos sentimentos ao longo do ano. O resultado da análise de emoções pode ser lida no meu texto a ser disponibilizado.
O objetivo geral deste trabalho é realizar uma análise de sentimentos em textos oriundos do Twitter escritos em português do Brasil, e identificar os efeitos emocionais manifestados na população durante o período da pandemia de Covid 19 vivido durante o ano de 2020.
Para alcançar o objetivo geral, delineiam-se os seguintes objetivos específicos compreendidos nesse projeto:
• Identificar métodos e técnicas utilizados na análise de sentimentos e comparar o resultado de suas métricas; • Criar uma base de dados em português brasileiro, obtidos através do Twitter, que fazem referência ao tema da pandemia de Covid-19 no ano de 2020; • Comparar modelos de aprendizado de máquina para classificar sentimentos e emoções em texto; • Extrair as variações emocionais detectadas em tweets durante esse período.
|- extract_tweets.py
|- data
|- dataset_label_pos_neg.csv
|- dataset_neg_emotions.csv
|- raw_with_emojis.csv
|
|- notebooks
|- utils
|- data_labeling.ipynb
|- models
|- BERT.ipynb
|- SVM.ipynb
|- Naive_Bayes.ipynb
|- DecisionTree.ipynb
|- Logistic_Regression.ipynb
O arquivo extract_tweets.py contém o código utilizado para extrair os tweets utilizando a biblioteca Snscrape.
Contém os arquivos csv utilizados para treinamento dos modelos. O modelos foram treinados para sentimentos positivos e negativos, e também para reconhecer 4 emoções negativas: raiva, tristeza, medo e desprezo. O dataset para treinamento de sentimentos positivos e negativos foi gerado a partir da identificação de emojis, o dataset original contendo os tweets que contém emojis também se encontra no diretório.
Nesse diretório se encontram os notebooks utilizados para o treinamento dos modelos e tarefas necessárias para treiná-los.
Contém o notebook com o código utilizado para realizar a pré-classificação de tweets em sentimentos positivos e negativos através de textos contendo emojis.
Contém as implementações dos modelos Naive Bayes, SVM, Logistic Regression, Decision Tree e BERT, analisados no estudo.
O conjunto de dados utilizado para treino e teste foi oriundo da seguinte distribuição:

O modelos treinados com esses conjuntos de dados foram analisados com as seguintes métricas: Acurácia, Medida F, Precisão e Revocação. Dos resultados observados obteve-se:


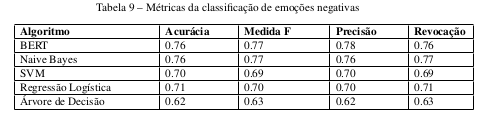
Observando em detalhes os valores do modelo BERT das métricas para cada emoção negativa têm-se que a tristeza foi a emoção com o menor desempenho e, portanto, possui espaço para melhorias.

Este projeto está sob a licença MIT. Veja LICENSE para ler o texto completo.