Releases: MASD-Project/dogen
Dogen v1.0.32, "Natal na Baía Azul"

Baía Azul, Benguela, Angola. (C) 2022 Casal Sampaio.
DRAFT: Release notes under construction
Introduction
As expected, going back into full time employment has had a measurable impact on our open source throughput. If to this one adds the rather noticeable PhD hangover — there were far too many celebratory events to recount — it is perhaps easier to understand why it took nearly four months to nail down the present release. That said, it was a productive effort when measured against its goals. Our primary goal was to finish the CI/CD work commenced the previous sprint. This we duly achieved, though you won't be surprised to find out it was far more involved than anticipated. So much so that the, ahem, final touches, have spilled over to the next sprint. Our secondary goal was to resume tidying up the LPS (Logical-Physical Space), but here too we soon bumped into a hurdle: Dogen's PlantUML output was not fit for purpose, so the goal quickly morphed into diagram improvement. Great strides were made in this new front but, as always, progress was hardly linear; to cut a very long story short, when we were half-way through the ask, we got lost on yet another architectural rabbit hole. A veritable Christmas Tale of a sprint it was, though we are not entirely sure on the moral of the story. Anyway, grab yourself that coffee and let's dive deep into the weeds.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. Given the stories do not require that much of a demo, we discuss their implications in terms of the Domain Architecture.
Video 1: Sprint 32 Demo.
Remove Dia and JSON support
The major user facing story this sprint is the deprecation of two of our three codecs, Dia and JSON, and, somewhat more dramatically, the eradication of the entire notion of "codec" as it stood thus far. Such a drastic turn of events demands an in-depth explanation, so you'll have to bear with us. Lets start our journey with an historical overview.
It wasn't that long ago that "codecs" took the place of the better-known "injectors". Going further back in time, injectors themselves emerged from a refactor of the original "frontends", a legacy of the days when we viewed Dogen more like a traditional compiler. "Frontend" implies a unidirectional transformation and belongs to the compiler domain rather than MDE, so the move to injectors was undoubtedly a step in the right direction. Alas, as the release notes tried to explain then (section "Rename injection to codec"), we could not settle on this term because Dogen's injectors did not behave like "proper" MDE injectors, as defined in the MDE companion notes (p. 32):
In [Béz+03], Bézivin et al. outlines their motivation [for the creation of Technical Spaces (TS)]: ”The notion of TS allows us to deal more efficiently with the ever-increasing complexity of evolving technologies. There is no uniformly superior technology and each one has its strong and weak points.” The idea is then to engineer bridges between technical spaces, allowing the importing and exporting of artefacts across them. These bridges take the form of adaptors called ”projectors”, as Bézivin explains (emphasis ours):
The responsibility to build projectors lies in one space. The rationale to define them is quite simple: when one facility is available in another space and that building it in a given space is economically too costly, then the decision may be taken to build a projector in that given space. There are two kinds of projectors according to the direction: injectors and extractors. Very often we need a couple of injector/extractor [(sic.)] to solve a given problem. [Béz05a]
In other words, injectors are meant to be transforms responsible for projecting elements from one TS into another. Our "injectors" behaved like real injectors in some cases (e.g. Dia), but there were also extractors in the mix (e.g. PlantUML) and even "injector-extractors" too (e.g. JSON, org-mode). Calling this motley projector set "injectors" was a bit of a stretch, and maybe even contrary to the Domain Architecture clean up, given its responsibility for aligning Dogen source code and MDE vocabulary. After wrecking our brains for a fair bit, we decided "codec" sufficed as a stop-gap alternative:
A codec is a device or computer program that encodes or decodes a data stream or signal. Codec is a portmanteau [a blend of words in which parts of multiple words are combined into a new word] of coder/decoder. [Source: Wikipedia]
As this definition implies, the term belongs to the Audio/Video domain so its use never felt entirely satisfying; but, try as we might, we could not come up with a better of way of saying "injection and extraction" in one word, nor had anyone — to our knowledge — defined the appropriate portemanteau within MDE's canon. The alert reader won't fail to notice this is a classic case of a design smell, and so did we, though it was hard to pinpoint what hid behind the smell. Since development life is more than interminable discussions on terminology, and having more than exhausted the allocated resources for this matter, a line was drawn: "codec" was to remain in place until something better came along. So things stood at the start of the sprint, in this unresolved state.
Then, whilst dabbling on some apparently unrelated matters, the light bulb moment finally arrived; and when we fully grasped all its implications, the fallout was much bigger than just a component rename. To understand why it was so, it's important to remember that MASD theory set in stone the very notion of "injection from multiple sources" via the pervasive integration principle — the second of the methodology's six core values. I shan't bother you too much with the remaining five principles, but it is worth reading Principle 2 in full to contextualise our decision making. The PhD thesis (p. 61) states:
Principle 2: MASD adapts to users’ tools and workflows, not the converse. Adaptation is achieved via a strategy of pervasive integration.
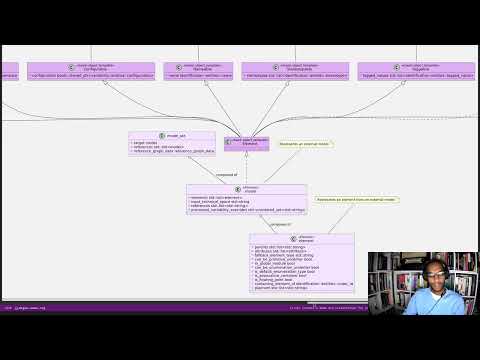
MASD promotes tooling integration: developers preferred tools and workflows must be leveraged and integrated with rather than replaced or subverted. First and foremost, MASD’s integration efforts are directly aligned with its mission statement (cf. Section 5.2.2 [Mission Statement]) because integration infrastructure is understood to be a key source of SRPPs [Schematic and Repetitive Physical Patterns]. Secondly, integration efforts must be subservient to MASD’s narrow focus [Principle 1]; that is, MASD is designed with the specific purpose of being continually extended, but only across a fixed set of dimensions. For the purposes of integration, these dimensions are the projections in and out of MASD’s TS [Technical Spaces], as Figure 5.2 illustrates.

Figure 1 [orginaly 5.2]: MASD Pervasive integration strategy.
Within these boundaries, MASD’s integration strategy is one of pervasive integration. MASD encourages mappings from any tools and to any programming languages used by developers — provided there is sufficient information publicly available to create and maintain those mappings, and sufficient interest from the developer community to make use of the functionality. Significantly, the onus of integration is placed on MASD rather than on the external tools, with the objective of imposing minimal changes to the tools themselves. To demonstrate how the approach is to be put in practice, MASD’s research includes both the integration of org-mode (cf. Chapter 7), as well as a survey on the integration strategies of special purpose code generators (Craveiro, 2021d [available here]); subsequent analysis generalised these findings so that MASD tooling can benefit from these integration strategies. Undertakings of a similar nature are expected as the tooling coverage progresses.
Whilst in theory this principle sounds great, and whilst we still agree wholeheartedly with it in spirit, there are a few practical problems with its current implementation. The first, which to be fair is already hinted at above, is that you need to have an interested community maintaining the injectors into MASD's TS. That is because, even with decent test coverage, it's very easy to break existing workflows when adding new functionality, and the continued maintenance of the tests is costly. Secondly, many of these formats evolve over time, so one needs to keep up-to-date with tooling to remain relevant. Thirdly, as we add formats we will inevitably pickup more and more external dependencies, resulting in a bulking up of Dogen's core only to satisfy some possibly peripheral use case. Finally, each injector adds a large cognitive load because, as we do changes, we now need to revisit all injectors and see how they map to each representation. Advanced mathematics is not required to see that the velocity of coding is an inverse function of the number of injectors;...
Dogen v1.0.31, "Exeunt Academia"

Graduation day for the PhD programme of Computer Science at the University of Hertfordshire, UK. (C) 2022 Shahinara Craveiro.
Introduction
After an hiatus of almost 22 months, we've finally managed to push another Dogen release out of the door. Proud of the effort as we are, it must be said it isn't exactly the most compelling of releases since the bulk of its stories are related to basic infrastructure. More specifically, the majority of resourcing had to be shifted towards getting Continuous Integration (CI) working again, in the wake of Travis CI's managerial changes. However, the true focus of the last few months lays outside the bounds of software engineering; our time was spent mainly on completing the PhD thesis, getting it past a myriad of red-tape processes and perhaps most significantly of all, on passing the final exam called the viva. And so we did. Given it has taken some eight years to complete the PhD programme, you'll forgive us for the break with the tradition in naming releases after Angolan places or events; regular service will resume with the next release, on this as well as on the engineering front <knocks on wood, nervously>. So grab a cupper, sit back, relax, and get ready for the release notes that mark the end of academic life in the Dogen project.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. The demo spends some time reflecting on the PhD programme overall.
Video 1: Sprint 31 Demo.
Deprecate support for dumping tracing to a relational database
It wasn't that long ago Dogen was extended to dump tracing information into relational databases such as PostgreSQL and their ilk. In fact, v1.0.20's release notes announced this new feature with great fanfare, and we genuinely had high hopes for its future. You are of course forgiven if you fail to recall what the fuss was all about, so it is perhaps worthwhile doing a quick recap. Tracing - or probing as it was known then - was introduced in the long forgotten days of Dogen v1.0.05, the idea being that it would be useful to inspect model state as the transform graph went through its motions. Together with log files, this treasure trove of information enabled us to quickly understand where things went wrong, more often than not without necessitating a debugger. And it was indeed incredibly useful to begin with, but we soon got bored of manually inspecting trace files. You see, the trouble with these crazy critters is that they are rather plump blobs of JSON, thus making it difficult to understand "before" and "after" diffs for the state of a given model transform - even when allowing for json-diff and the like. To address the problem we doubled-down on our usage of JQ, but the more we did so, the clearer it became that JQ queries competed in the readability space with computer science classics like regular expressions and perl. A few choice data points should give a flavour of our troubles:
# JQ query to obtain file paths:
$ jq .models[0].physical.regions_by_logical_id[0][1].data.artefacts_by_archetype[][1].data.data.file_path
# JQ query to sort models by elements:
$ jq '.elements|=sort_by(.name.qualified)'
# JQ query for element names in generated model:
$ jq ."elements"[]."data"."__parent_0__"."name"."qualified"."dot"It is of course deeply unfair to blame JQ for all our problems, since "meaningful" names such as __parent_0__ fall squarely within Dogen's sphere of influence. Moreover, as a tool JQ is extremely useful for what it is meant to do, as well as being incredibly fast at it. Nonetheless, we begun to accumulate more and more of these query fragments, glued them up with complex UNIX shell pipelines that dumped information from trace files into text files, and then dumped diffs of said information to other text files which where then... - well, you get the drift. These scripts were extremely brittle and mostly "one-off" solutions, but at least the direction of travel was obvious: what was needed was a way to build up a number of queries targeting the "before" and "after" state of any given transform, such that we could ask a series of canned questions like "has object x0 gone missing in transform t0?" or "did we update field f0 incorrectly in transform t0?", and so on. One can easily conceive that a large library of these queries would accumulate over time, allowing us to see at a glance what changed between transforms and, in so doing, make routine investigations several orders of magnitude faster. Thus far, thus logical. We then investigated PostgreSQL's JSON support and, at first blush, found it to be very comprehensive. Furthermore, given that Dogen always had basic support for ODB, it was "easy enough" to teach it to dump trace information into a relational database - which we did in the aforementioned release.
Alas, after the initial enthusiasm, we soon realised that expressing our desired questions as database queries was far more difficult than anticipated. Part of it is related to the complex graph that we have on our JSON documents, which could be helped by creating a more relational-database-friendly model; and part of it is the inexperience with PostgreSQL's JSON query extensions. Sadly, we do not have sufficient time address either question properly, given the required engineering effort. To make matters worse, even though it was not being used in anger, the maintenance of this code was become increasingly expensive due to two factors:
- its reliance on a beta version of ODB (v2.5), for which there are no DEBs readily available; instead, one is expected to build it from source using Build2, an extremely interesting but rather suis generis build tool; and
- its reliance on either a manual install of the ODB C++ libraries or a patched version of vcpkg with support for v2.5. As vcpkg undergoes constant change, this means that every time we update it, we then need to spend ages porting our code to the new world.
Now, one of the rules we've had for the longest time in Dogen is that, if something is not adding value (or worse, subtracting value) then it should be deprecated and removed until such time it can be proven to add value. As with any spare time project, time is extremely scarce, so we barely have enough of it to be confused with the real issues at hand - let alone speculative features that may provide a pay-off one day. So it was that, with great sadness, we removed all support for the relational backend on this release. Not all is lost though. We use MongoDB a fair bit at work, and got the hang of its query language. A much simpler alternative is to dump the JSON documents into MongoDB - a shell script would do, at least initially - and then write Mongo queries to process the data. This is an approach we shall explore next time we get stuck investigating an issue using trace dumps.
Add "verbatim" PlantUML extension
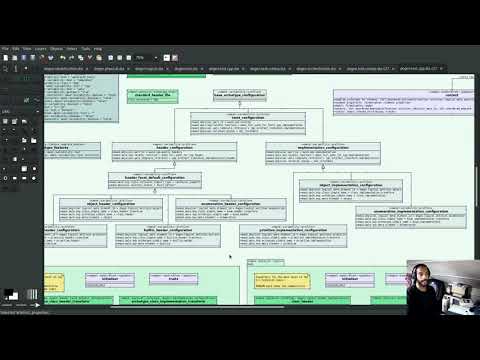
The quality of our diagrams degraded considerably since we moved away from Dia. This was to be expected; when we originally added PlantUML support in the previous release, it was as much a feasibility study as it was the implementation of a new feature. The understanding was that we'd have to spend a number of sprints slowly improving the new codec, until its diagrams where of a reasonable standard. However, this sprint made two things clear: a) just how much we rely on these diagrams to understand the system, meaning we need them back sooner rather than later; and b) just how much machinery is required to properly model relations in a rich way, as was done previously. Worse: it is not necessarily possible to merely record relations between entities in the input codec and then map those to a UML diagram. In Dia, we only modeled "significant relations" in order to better convey meaning. Lets make matters concrete by looking at a vocabulary type such as entities::name in model dogen::identification. It is used throughout the whole of Dogen, and any entity with a representation in the LPS (Logical-Physical Space) will use it. A blind approach of modeling each and every relation to a core type such as this would result in a mess of inter-crossing lines, removing any meaning from the resulting diagram.
After a great deal of pondering, we decided that the PlantUML output needs two kinds of data sources: automated, where the relationship is obvious and uncontroversial - e.g. the attributes that make up a class, inheritance, etc.; and manual, where the relationship requires hand-holding by a human. This is useful for example in the above case, where one would like to suppress relationships against a basic vocabulary type. The feature was implemented by means of adding a PlantUML verbatim att...
Dogen v1.0.30, "Estádio Joaquim Morais"

Municipal stadium in Moçamedes, Namibe, Angola. (C) 2020 Angop.
Introduction
Happy new year! The first release of the year is a bit of a bumper one: we finally managed to add support for org-mode, and transitioned all of Dogen to it. It was a mammoth effort, consuming the entirety of the holiday season, but it is refreshing to finally be able to add significant user facing features again. Alas, this is also a bit of a bitter-sweet release because we have more or less run out of coding time, and need to redirect our efforts towards writing the PhD thesis. On the plus side, the architecture is now up-to-date with the conceptual model, mostly, and the bits that aren't are fairly straightforward (famous last words). And this is nothing new; Dogen development has always oscillated between theory and practice. If you recall, a couple of years ago we had to take a nine-month coding break to learn about the theoretical underpinnings of MDE and then resumed coding on Sprint 8 for what turned out to be a 22-sprint-long marathon (pun intended), where we tried to apply all that was learned to the code base. Sprint 30 brings this long cycle to a close, and begins a new one; though, this time round, we are hoping for far swifter travels around the literature. But lets not get lost talking about the future, and focus instead on the release at hand. And what a release it was.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail.
Video 1: Sprint 30 Demo.
Org-mode support
A target that we've been chasing for the longest time is the ability to create models using org-mode. We use org-mode (and emacs) for pretty much everything in Dogen, such time keeping and task management - it's how we manage our product and sprint backlogs, for one - and we'll soon be using it to write academic papers too. It's just an amazing tool with a great tooling ecosystem, so it seemed only natural to try and see if we could make use of it for modeling too. Now, even though we are very comfortable with org-mode, this is not a decision to be taken lightly because we've been using Dia since Dogen's inception, over eight years ago.
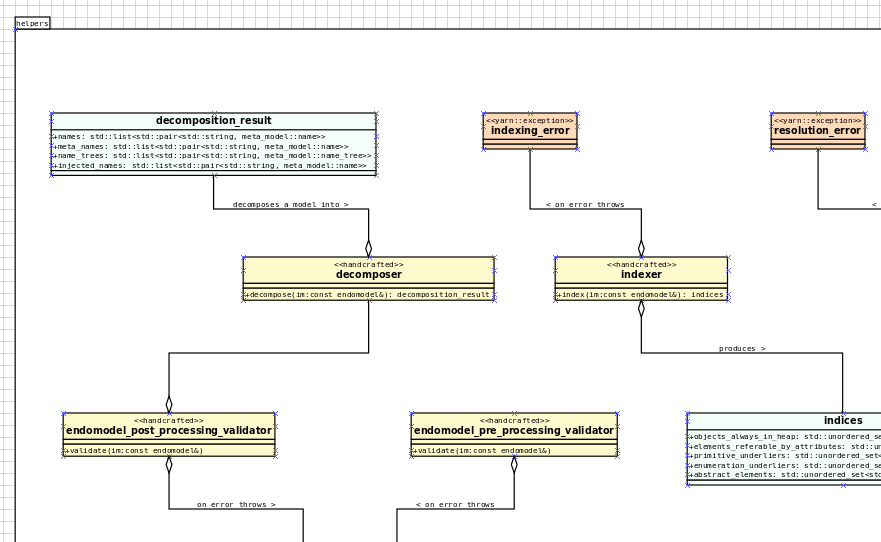
Figure 1: Dia diagram for a Dogen model with the introduction of colouring, Dogen v1.0.06
As much as we profoundly love Dia, the truth is we've had concerns about relying on it too much due to its somewhat sparse maintenance, with the last release happening some nine years ago. What's more pressing is that Dia relies on an old version of GTK, meaning it could get pulled from distributions at any time; we've already had a similar experience with Gnome Referencer, which wasn't at all pleasant. In addition, there are a number of "papercuts" that are mildly annoying, if livable, and which will probably not be addressed; we've curated a list of such issues, in the hope of one day fixing these problems upstream, but that day never came. The direction of travel for the maintenance is also not entirely aligned with our needs. For example, we recently saw the removal of python support in Dia - at least in the version which ships with Debian - a feature in which we relied upon heavily, and intended to do more so in the future. All of this to say that we've had a number of ongoing worries that motivated our decision to move away from Dia. However, I don't want to sound too negative here - and please don't take any of this as a criticism to Dia or its developers. Dia is an absolutely brilliant tool, and we have used it for over two decades; It is great at what it does, and we'll continue to use it for free modeling. Nonetheless, it has become increasingly clear that the directions of Dia and Dogen have started to diverge over the last few years, and we could not ignore that. I'd like to take this opportunity to give a huge thanks to all of those involved in Dia (past and present); they have certainly created an amazing tool that stood the test of time. Also, although we are moving away from Dia use in mainline Dogen, we will continue to support the Dia codec and we have tests to ensure that the current set of features will continue to work.
That's that for the rationale for moving away from Dia. But why org-mode? We came up with a nice laundry list of reasons:
- "Natural" Representation: org-mode documents are trees, with arbitrary nesting, which makes it a good candidate to represent the nesting of namespaces and classes. It's just a natural representation for structural information.
- Emacs tooling: within the org-mode document we have full access to Emacs features. For example, we have spell checkers, regular copy-and-pasting, etc. This greatly simplifies the management of models. Since we already use Emacs for everything else in the development process, this makes the process even more fluid.
- Universality: org-mode is fairly universal, with support in Visual Studio Code, Atom and even Vim (for more details, see Get started with Org mode without Emacs). None of these implementations are as good as Emacs, of course - not that we are biased, or anything - but they are sufficient to at least allow for basic model editing. And installing a simple plugin in your editor of choice is much easier than having to learn a whole new tool.
- "Plainer" plain-text: org-mode documents are regular text files, and thus easy to life-cycle in a similar fashion to code; for example, one can version control and diff these documents very easily. Now, we did have Dia's files in uncompressed XML, bringing some of these advantages, but due to the verbosity of XML it was very hard to see the wood for the trees. Lots of lines would change every time we touched a model element - and I literally mean "touch" - making it difficult to understand the nature of the change. Bisection for example was not helped by this.
- Models as documentation: Dogen aims to take the approach of "Literate Modeling" described in papers such as Literate Modelling - Capturing Business Knowledge with the UML. It was clear from the start that a tool like Dia would not be able to capture the wealth of information we intended to add to the models. Org-mode on the other hand is the ideal format to bring disparate types of information together (see Replacing Jupyter with Orgmode for an example of the sort of thing we have in mind).
- Integration with org-babel: Since models contain fragments of source code, org-mode's support for working with source code will come in handy. This will be really useful straight away on the handling of text templates, but even more so in the future when we add support for code merging.
Over the past few sprints we've been carrying out a fair bit of experimentation on the side, generating org-mode files from the existing Dia models; it was mostly an exercise in feasibility to see if we could encode all of the required information in a comprehensible manner within the org-mode document. These efforts convinced us that this was a sensible approach, so this sprint we focused on adding end-to-end support for org-mode. This entailed reading org-mode documents, and using them to generate the exact same code as we had from Dia. Unfortunately, though C++ support for org-mode exists, we could not find any suitable library for integration in Dogen. So we decided to write a simple parser for org-mode documents. This isn't a "generic parser" by any means, so if you throw invalid documents at it, do expect it to blow up unceremonially. Figure 2 shows the dogen.org model represented as a org-mode document.

Figure 2: dogen.org model in the org-mode representation.
We tried as much as possible to leverage native org-mode syntax, for example by using tags and property drawers to encode Dogen information. However, this is clearly a first pass and many of the decisions may not survive scrutiny. As always, we need to have a great deal of experience editing models to see what works and what does not, and it's likely we'll end up changing the markup ...
Dogen v1.0.29, "Bar 'O Stop'"
Bar O Stop, Namibe. (C) 2010 Jo Sinfield

Introduction
And so t'was that the 29th sprint of the 1.0 era finally came to a close; and what a bumper sprint it was. If you recall, on Sprint 28 we saw the light and embarked on a coding walkabout to do a "bridge refactor". The rough objective was to complete a number of half-baked refactors, and normalise the entire architecture around key domain concepts that have been absorbed from MDE (Model Driven Engineering) literature. Sprint 29 brings this large wandering to a close - well, at least as much as one can "close" these sort of never ending things - and leaves us on a great position to focus back on "real work". Lest you have forgotten, the "real work" had been to wrap things up with the PMM (Physical Meta-Model), but it had fallen by the wayside since the end of Sprint 27. When this work resumes, we can now reason about the architecture without having to imagine some idealised target state that would probably never arrive (at the rate we were progressing), making the effort a lot less onerous. Alas, this trivialises the sprint somewhat. The truth was that it took over 380 commits and 89 hours of intense effort to get us in this place, and it is difficult to put in words the insane amount of work that makes up this release. Nevertheless, one is compeled to give it a good old go, so settle in for the ride that was Sprint 29.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
Video 1: Sprint 29 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
This sprint had two key goals, both of which were achieved:
- moving remaining "formattable" types to logical and physical models.
- Merge
textmodels.
By far, the bulk of the work went on the second of these two goals. In addition, a "stretch" goal appeared towards the end of the sprint, which was to tidy-up and merge the codec model. These goals were implemented by means of four core stories, which captured four different aspects of the work, and were then aided by a cast of smaller stories which, in truth, were more like sub-stories of these "conceptual epics". We shall cover the main stories in the next sections and slot in the smaller stories as required. Finally, there were a number of small "straggler stories" which we'll cover at the end.
Complete the formattables refactor
A very long running saga - nay, a veritable Brazilian soap opera of coding - finally came to an end this sprint with the conclusion of the "formattables" refactor. We shan't repeat ourselves explaining what this work entailed, given that previous release notes had already done so in excruciating detail, but its certainly worth perusing those writings to get an understanding of the pain involved. This sprint we merely had to tie up lose ends and handle the C# aspects of the formattables namespace. As before, all of these objects were moved to "suitable" locations within the LPS (Logical-Physical Space), though perhaps further rounds of modeling clean-ups are required to address the many shortcomings of the "lift-and-shift" approach taken. This was by design, mind you; it would have been very tricky, and extremely slow-going, if we had to do a proper domain analysis for each of these concepts and then determine the correct way of modeling them. Instead, we continued the approach laid out for the C++ model, which was to move these crazy critters to the logical or physical models with the least possible amount of extra work. To be fair, the end result was not completely offensive to our sense of taste, in most cases, but there were indeed instances that required closing one's eyes and "just get on with it", for we kept on being tempted to do things "properly". It takes a Buddhist-monk-like discipline to restrict oneself to a single "kind" of refactor at a time, but it is crucial to do so because otherwise one will be forever stuck in the "refactor loop", which we described in The Refactoring Quagmire all those moons ago.
It is also perhaps worth spending a few moments to reflect on the lessons taught by formattables. On one hand, it is a clear validation of the empirical approach. After all, though the modeling was completely wrong from a domain expertise standpoint, much of what was laid out within this namespace captured the essence of the task at hand. So, what was wrong about formattables? The key problem was that we believed that there were three representations necessary for code-generation:
- the external representation, which is now housed in the
codecmodel; - the "language agnostic" representation, which is now housed in the
logicmodel; - the "language-specific" representation, which was implemented by formattables (i.e.,
text.cppandtext.csharp).
What the empirical approach demonstrated was that there is no clear way to separate the second and third representations, try as we might, because there is just so much overlap between them. The road to the LPS had necessarily to go through formattables, because in theory it appeared so clear and logical that separate TSs (Technical Spaces) should have clean, TS-specific representations which were ready to be written to files. As Mencken stated:
Every complex problem has a solution which is simple, direct, plausible—and wrong.
In fact, It took a great deal of careful reading through the literature, together with a lot of experimentation, to realise that doing so is not at all practical. Thus, it does not seem that it was possible to have avoided making this design mistake. One could even say that this "mistake" is nothing but the empirical approach at play, because you are expected to conduct experiments and accumulate facts about your object of study, and then revise your hypothesis accordingly. The downside, of course, is that it takes a fair amount of time and effort to perform these "revisions" and it certainly feels as if there was "wasted time" which could have been saved if only we started off with the correct design in the first place. Alas, it is not clear how would one simply have the intuition for the correct design without the experimentation. In other words, the programmer's perennial condition.
Move helpers into text model and add them to the PMM
As described in the story above, it has become increasingly clear that the text model is nothing but a repository of M2T (Model to Text) transforms, spread out across TS's and exposed programatically into the PMM for code generation purposes. Therefore, the TS-specific models for C++ and C# no longer make any sense; what is instead required is a combined text model containing all of the text transforms, adequately namespaced, making use of common interfaces and instantiating all of the appropriate PMM entities. This "merging" work fell under the umbrella of the architectural clean up work planned for this sprint.
The first shot across the bow in the merging war concerned moving "helpers" from both C++ and C# models into the combined model. A bit of historical context is perhaps useful here. Helpers, in the M2T sense, have been a pet-peeve of ours for many many moons. Their role is to code-generate functionlets inside of the archetypes (e.g. the "real" M2T transforms). These helpers, via an awfully complicated binding logic which we shall not bore you with, bind to the type system and then end up acting as "mini-adapters" for specific purposes, such as allowing us to use third-party libraries within Dogen, cleaning up strings prior to dumping them in streams and so forth. A code sample should help in clarifying this notion. The below code fragment, taken from logical::entities::element, contains the output three different helper functions:
inline std::string tidy_up_string(std::string s) {
boost::replace_all(s, "\r\n", "<new_line>");
boost::replace_all(s, "\n", "<new_line>");
boost::replace_all(s, "\"", "<quote>");
boost::replace_all(s, "\\", "<backslash>");
return s;
}
namespace boost {
inline bool operator==(const boost::shared_ptr<dogen::variability::entities::configuration>& lhs,
const boost::shared_ptr<dogen::variability::entities::configuration>& rhs) {
return (!lhs && !rhs) ||(lhs && rhs && (*lhs == *rhs));
}
}
namespace boost {
inline std::ostream& operator<<(std::ostream& s, const boost::shared_ptr<dogen::variability::entities::configuration>& v) {
s << "{ " << "\"__type__\": " << "\"boost::shared_ptr\"" << ", "
<< "\"memory\": " << "\"" << static_cast<void*>(v.get()) << "\"" << ", ";
if (v)
s << "\"data\": " << *v;
else
...Dogen v1.0.28, "Praia das Miragens"
Artesanal market, Praia das Miragens, Moçâmedes, Angola. (C) 2015 David Stanley.

Introduction
Welcome to yet another Dogen release. After a series of hard-fought and seemingly endless sprints, this sprint provided a welcome respite due to its more straightforward nature. Now, this may sound like a funny thing to say, given we had to take what could only be construed as one massive step sideways, instead of continuing down the track beaten by the previous n iterations; but the valuable lesson learnt is that, oftentimes, taking the theoretically longer route yields much faster progress than taking the theoretically shorter route. Of course, had we heeded van de Snepscheut, we would have known:
In theory, there is no difference between theory and practice. But, in practice, there is.
What really matters, and what we keep forgetting, is how things work in practice. As we mention many a times in these release notes, the highly rarefied, highly abstract meta-modeling work is not one for which we are cut out, particularly when dealing with very complex and long-running refactorings. Therefore, anything which can bring the abstraction level as close as possible to normal coding is bound to greatly increase productivity, even if it requires adding "temporary code". With this sprint we finally saw the light and designed an architectural bridge between the dark old world - largely hacked and hard-coded - and the bright and shiny new world - completely data driven and code-generated. What is now patently obvious, but wasn't thus far, is that bridging the gap will let us to move quicker because we don't have to carry so much conceptual baggage in our heads every time we are trying to change a single line of code.
Ah, but we are getting ahead of ourselves! This and much more shall be explained in the release notes, so please read on for some exciting news from the front lines of Dogen development.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
Video 1: Sprint 28 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
The main story this sprint was concerned with removing the infamous locator from the C++ and C# models. In addition to that, we also had a small number of stories, all gathered around the same theme. So we shall start with the locator story, but provide a bit of context around the overall effort.
Move C++ locator into physical model
As we explained at length in the previous sprint's release notes, our most pressing concern is finalising the conceptual model for the LPS (Logical-Physical Space). We have a pretty good grasp of what we think the end destination of the LPS will be, so all we are trying to do at present is to refactor the existing code to make use of those new entities and relationships, replacing all that has been hard-coded. Much of the problems that still remain stem from the "formattables subsystem", so it is perhaps worthwhile giving a quick primer of what formattables were, why they came to be and why we are getting rid of them. For this we need to travel in time, to close to the start of Dogen. In those long forgotten days, long before we had the benefit of knowing about MDE (Model Driven Engineering) and domain concepts such as M2M (Model-to-Model) and M2T (Model-to-Text) transforms, we "invented" our own terminology and approach to converting modeling elements into source code. The classes responsible for generating the code were called formatters because we saw them as a "formatting engine" that dumped state into a stream; from there, it logically followed that the things we were "formatting" should be called "formattables", well, because we could not think of a better name.
Crucially, we also assumed that the different technical spaces we were targeting had lots of incompatibilities that stopped us from sharing code between them, which meant that we ended up creating separate models for each of the supported technical spaces - i.e., C++ and C#, which we now call major technical spaces. Each of these ended up with its own formattables namespace. In this world view, there was the belief that we needed to transform models closer to their ultimate technical space representation before we could start generating code. But after doing so, we began to realise that the formattable types were almost identical to their logical and physical counterparts, with a small number of differences.

Figure 1: Fragment of the formattables namespace, C++ Technical Space, circa sprint 23.
What we since learned is that the logical and physical models must be able to represent all of the data required in order to generate source code. Where there are commonalities between technical spaces, we should exploit them, but where there are differences, well, they must still be represented within the logical and physical models; there simply is nowhere else to place them. In other words, there isn't a requirement to keep the logical and physical models technical space agnostic, as we long thought was needed; instead, we should aim for a single representation, but also not be afraid of multiple representations where they make more sense. With this began a very long-standing effort to move modeling elements across, one at a time, from formattables and the long forgotten fabric namespaces into their final resting place. The work got into motion circa sprint 18, and fabric was swiftly dealt with, but formattables proved more challenging. Finally, ten sprints later, this long running effort came unstuck when we tried to deal with the representation of paths (or "locations") in the new world because it wasn't merely just "moving types around"; the more the refactoring progressed, the more abstract it was becoming. For a flavour of just how abstract things are getting, have a read on Section "Add Relations Between Archetypes in the PMM" in sprint 26's release notes.
Ultimately, it became clear that we tried to bite more than we could chew. After all, in a completely data driven world, all of the assembly performed in order to generate a path is done by introspecting elements of the logical model, the physical meta-model (PMM) and the physical model (PM). This is extremely abstract work, where all that once were regular programming constructs have now been replaced by a data representation of some kind; and we had no way to validate any of these representations until we reached the final stage of assembling paths together, a sure recipe for failure. We struggled with this on the back-end of the last sprint and the start of this one, but then it suddenly dawned that we could perhaps move one step closer to the end destination without necessarily making the whole journey; going half-way or bridging the gap, if you will. The moment of enlightenment revealed by this sprint was to move the hard-coded concepts in formattables to the new world of transforms and logical/physical entities, without fully making them data-driven. Once we did that, we found we had something to validate against that was much more like-for-like, instead of the massive impedance mismatch we are dealing with at present.
So this sprint we moved the majority of types in formattables into their logical or physical locations. As the story title implies, the bulk of the work was connected to moving the locator class on both C# and C++ formattables. This class had a seemingly straightforward responsibility: to build relative and full paths in the physical domain. However, it was also closely intertwined with the old-world formatters and the generation of dependencies (such as the include directives). It was difficult to unpick all of these different strands that connected the locator to the old world, and encapsulate them all inside of a transform, making use only of data available in the physical meta model and physical model, but once we achieved that all was light.
There were lots of twists and turns, of course, and we did find some cases that do not fit terribly well the present design. For instance, we had assumed that there was a natural progression in terms of projections, i.e.:
- from an external representation;
- to the simplified internal representation in the codec model;
- to the projection into the logical model;
- to the projection into the physical model;
- to, ultimately, the projection into a technical space - i.e., code generation.
As it turns out, sometimes we need to peek into the logical model after the projection to the physical model has been performed, which is not quite so linear as we'd want. This may sound slightl...
Dogen v1.0.27, "Independência"
Abandoned freighter North of Namibe, Angola. (C) Alfred Weidinger, 2011

Introduction
We've been working on Dogen for long enough to know that there is no such thing as an easy sprint; still, after a long sequence of very challenging ones, we were certainly hoping for an easier ride this time round. Alas, not to be. Due to never ending changes in personal circumstances, both with work and private life, Sprint 27 ended up being an awfully long sprint, with a grand total of 70 elapsed days rather than the 30 or 40 customary ones. To make matters worse, not only was it a bit of a fragmented sprint in time - a bit stop-start, if we're honest - but it was also somewhat disjointed in terms of the work as well. One never ending story occupied the bulk of the work, though it did have lots of challenging variations; and the remainder - a smattering of smaller stories - were insufficient to make any significant headway towards the sprint goals. Ah, the joys of working on such a long, open-ended project, hey. And to round it all up nicely, we weren't able to do a single MDE Paper of the Week (PofW); there just weren't enough hours in the day, and these were the first ones to fall by the wayside. They will hopefully resume at the usual cadence next sprint.
The picture may sound gloomy, but do not fear. As we shall see in these release notes, we may have not achieved what we set out to achieve originally, but much else was achieved nevertheless - giving us more than sufficient grounds for our unwavering developer optimism. Omnia mutantur, nihil interit, as Ovid would say.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
Video 1: Sprint 27 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
The story arc of the last few sprints has been centred around reducing the impedance mismatch between Dogen's source code and the conceptual model for the Logical-Physical Space (at times called the LPS). In turn, the LPS stemmed from the work we were doing in cleaning up the text models - in particular the C++ and C# backends; in other words, what we have been trying to achieve for some time now is to remove a large amount of hard-coding and just plain old bad modeling in those two models. For a throw back, see the section Towards a physical Model in the release notes of Sprint 23. At any rate, every time we try to address what appears to be a fairly straightforward issue, we soon realise it has big implications for the LPS, and then we end up going on yet another wild goose chase to try to find a solution that is in keeping with the conceptual model. Once its all resolved, we then go back to the task at hand and move forwards by a metre or so... until we find the next big issue. It has been this way for a while and sadly this sprint was no different. The main story that consumed just under 51% of the ask was the creation of a new model, the identification model, which was not directly aligned with the sprint goal. We then worked on a series of smaller stories that were indeed aligned with the goal, but which also required what appears to be a never ending series of mini-spikes. Lets have a quick look at all of these stories.
Create an identification model
The graph of relationships between the different models in Dogen has been a source of concern for a very long time, as this blog post attests. We are facing the typical engineering trade-offs: on one hand, we do not want cycles between models because that severely impairs testability and comprehension; on the other hand, we do not want a small number of "modelets", which have no well-defined responsibilities beyond simply existing to break up cycles. One such bone of contention has been the strange nature of the relationship between the logical and physical models. To be fair, this tangled relationship is largely a byproduct of the fundamental nature of the LPS, which posits that the logical-physical space is one combined entity. Predictably, these two models have a lot of references to each other:
- the
logicalmodel contains inside of it a model of thephysicalentities, which is use to code-generate these entities. - the
physicalmodel represents regions of the LPS for a given point in the logical axis of the LPS, and therefore needs to reference thelogicalmodel.
Until this sprint the problem had been resolved by duplicating types from both models. This was not an ideal approach but it did address both the problem of cycles as well as avoiding the existence of modelets. As we continued to move types around on our clean ups, we eventually realised that there are only a small number of types needed for these cross-model relationships to be modeled correctly; and as it turns out, pretty much all of these types seem to be related in one way or another to the "identification" of LPS entities. Now, this is not completely true - a few types are common but not really related to identification; but in the main, the notion holds sufficiently true. Therefore we decided to create a model with the surprising name of identification and put all the types in there. So far so good. This could have possibly been done with a simple set of renames, which would not take us too long. However, we were not content and decided to address a second long standing problem: avoid the use of "strings" everywhere for identification. If you've watched the Kevlin Henney classic presentation Seven Ineffective Coding Habits of Many Programmers, you should be aware that using strings and other such types all over the place is a sign of weak domain modeling. If you haven't, as with all Henney talks, I highly recommend it. At any rate, for the purposes of the present exercise, the Thomas Fagerbekk summary suffices:
4. We don't abstract enough.
Use your words, your classes, your abstractions. Don't do Strings, Lists and integers all over the place. [...] Instead, think about how you can communicate the meaning of the objects in the domain. Kevlin pulls up a wordcloud of the words used most frequently in a codebase (about 38-minute mark in the video): The most common words should tell you something about what the codebase is about. [...] A bad example shows List, Integer, String and such basic structures as the most common words. The better example has PrintingDevice, Paper, Picture. This makes the code less readable, because such generic variables can represent so many different things.
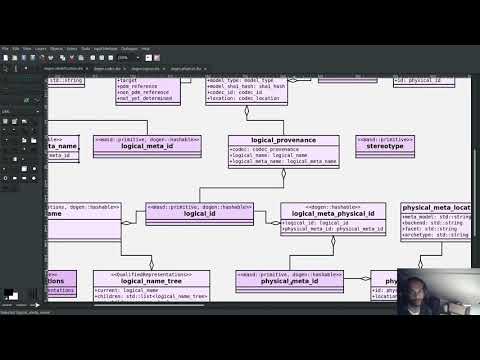
Now, if you have even a passing familiarity with Dogen's source code, you could not have helped but notice that we have a very large number of distinct IDs and meta-IDs all represented as strings. We've known for a long while that this is not ideal, not just because of Henney's points above, but also because we often end up using a string of "type" A as if it were a string of "type" B (e.g. using a logical meta-model ID when we are searching for a physical ID, say). These errors are painful to get to the bottom of. Wouldn't it be nice if the type system could detect them up front? Given these are all related to identification, we thought, might as well address this issue at the same time. And given Dogen already has built-in support for primitive types - that is, wrappers for trivial types such as string - it did seem that we were ready to finally make this change. Designing the new model was surprisingly quick; where the rubber met the road was on refactoring the code base to make use of the shiny new types.
Video 2: Part 1 of 3 of the series of videos on the Identification Refactor.
As you can imagine, and we now know first hand, modifying completely how "identification" works across a large code base is anything but a trivial exercise. There were many, many places where these types were used, sometimes incorrectly, and each of these places had its own subtleties. This change was one long exhausting exercise of modifying a few lines of code, dealing with a number of compilation errors and then dealing with many test failures. Then, rinse, repeat. Part of the not-exactly-fun-process was recorded on a series of videos, available on the playlist MASD - Dogen Coding: Identification Refactor:
- MASD - Dogen Coding: Identification Refactor - Part 1
- MASD - Dogen Coding: Identification Refactor - Part 2
- MASD - Dogen Coding: Identification Refactor - Part 3
These videos catch a tiny sliver of the very painful refactor, but they are more than sufficient to give a flavour of the over 4...
Dogen v1.0.26, "Rio Bentiaba"
Bentiaba river, Namibe, Angola. (C) 2016 O Viajante.

Introduction
Welcome to yet another Dogen sprint! This one was a bit of a Klingon Release, if we've ever seen one. Now, I know we did say Sprint 25 was a hard slog, but on hindsight 'twas but a mere walk in the park when compared to what was to come. Sprint 26 was at least twice as hard, lasted almost twice as long in terms of elapsed-time, had around 20% extra resourcing compared to what we usually allocate to a sprint and involved such a degree of abstract thinking - given our modest abilities - we often lost the plot altogether and had to go back to first principles. To add insult to injury, after such an intense a bout of coding, we still ended up miles off of the original sprint goal, which was clearly far too ambitious to begin with. For all of its hardships, the sprint did end on a high note when we finally had time to reflect on what was achieved; and the conceptual model does appear to be nearing its final shape - though, of course, you'd be forgiven for thinking you've heard that one before. Alas, some things never change.
But that's quite enough blabbering - let's look at how and where the action took place.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were only two small user facing features, the video also discusses the work on internal features.
Video 1: Sprint 26 Demo.
Archetype Factories and Transforms
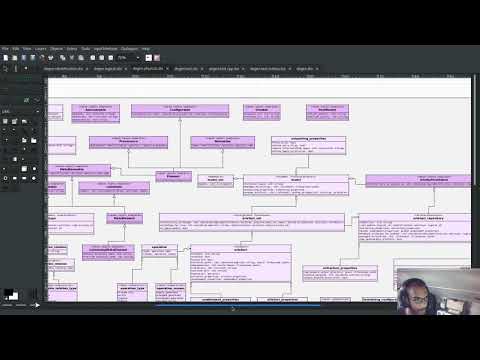
The main story visible to end users this sprint is deeply connected to our physical model changes, so it requires a fair amount of background in order to make sense of it. Before we proceed, we must first go through the usual disclaimers, pointing out that whilst this is technically a user facing story - in that any user can make use of this feature - in practice, it's only meant for those working in Dogen's internals - i.e. generating the code generator. It's also worthwhile pointing out that Dogen uses a generative architecture, where we try to generate as much as possible of Dogen using Dogen; and that we want the generated portion to increase over time. With those two important bits of information in hand, let's now take a step back to see how it all fits together.
MASD's logical model contains a set of modeling elements that capture the essential characteristics of the things we want to code-generate. Most of these elements are familiar to programmers because our targets tend to be artefacts created by programmers; these are classes, methods, enumerations and the like, the bricks and mortar we typically associate with the coding activity. However, from a MASD perspective, the story does not end there - and hence why we used the term "things". Ultimately, any artefact that contributes to a software product can be modeled as a logical entity, provided it exhibits "commonalities" which can be abstracted in order to recreate it via code generation. The fact that we model programming constructs is seen as more of a "coincidence" than anything else; what we really care about is locating and extracting certain kinds of structural patterns on files. One way to think about this is that we see some files as higher-dimensional structures that embed lower dimensional structures, which contain enough information to enable us to recreate the higher-dimensional structure. Our quest is to find cases where this happens, and to add the lower dimensional structures to our logical model. It just so happens that those lower dimensional structures are often programming constructs.

Figure 1: Archetypes representing M2T transforms in text.cpp model, on Sprint 25.
MASD provides a separation between logical entities and their eventual physical representation as a file. The mapping between the logical domain and the physical domain is seen as a projection through these spaces; one logical element projects to zero, one or many physical elements. In the physical domain, files are abstracted into artefacts (the physical model or PM), and each artefact is an instance of an archetype (the physical meta model or PMM). These are related in very much the same way a class and an object are: the artefact is an instance of an archetype. Until recently, we had to tell Dogen about the available archetypes "by hand" (a rough approximation): each text template had some boilerplate to inject the details of the archetype into the framework. After a great deal of effort, Sprint 25 finally brought us to a point where this code was generated by Dogen in the spirit of the framework. This was achieved by treating archetypes themselves as logical concepts, and providing physical projections for these logical elements as we do for any other logical element. Which neatly brings us to the present.
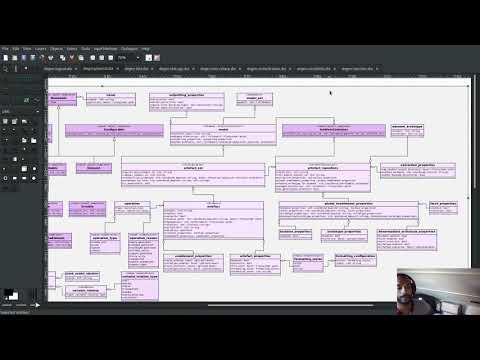
Archetypes had a single projection that contained two distinct bits of functionality:
- Telling the system about themselves: the above mentioned registration of the archetype, which is used by a set of transforms to generate the PMM.
- Providing an M2T transform: each archetype takes an associated logical element and generates its representation as an artefact.
The more we thought about it, the more it seemed strange that these two very different concerns were bundled into the same archetype. After all, we don't mix say serialisation with type definition on the same archetype, and for good reason. After some deliberation, we concluded it was there only for historical reasons. So this sprint we decided to project logical representations of some physical meta-model elements - e.g., backend, facet, archetype - onto two distinct physical archetypes:
- Factory: responsible for creating the physical meta-model element for the purposes of the PMM.
- Transform: responsible for the M2T transform.

Figure 2: Archetypes after the split in the present sprint.
It all seemed rather logical (if you pardon the pun), until one started to implement it. Trouble is, because we are knee-deep in the meta-land, many things end up in surprising places when one takes them to their logical consequences. Take archetypes for example. There is an archetype that represents the archetype factory itself, as there is an archetype that represents the archetype transform itself too, and there are permutations of the two as well - leading us to very interesting names such as archetype_class_header_factory_factory, archetype_class_header_transform_transform and the like. At first glance, these appear to be straight out of Spolsky's Factory Factory Factory parable - a threshold that, when reached, normally signals a need to halt and rethink the design. Which we did. However, in our defence, there is some method to the madness. Let's dissect the first name:
- the logical element this archetype maps to is
archetype; - the particular item it is interested in is a C++
class_header; - but its not just any old archetype class header, its the one specifically made for the
factoryof the archetype; - which, as it turns out, its also the factory which generates the
factoryof the archetype.
I guess every creator of a "framework" always comes up with justifications such as the above, and we'd be hard-pressed to explain why our case is different ("it is, honest guv!"). At any rate, we are quite happy with this change as its consistent with the conceptual model and made the code a lot cleaner. Hopefully it will still make sense when we have to maintain it in a few years time.
Add Support for CSV Values in Variability
The variability model is a very important component of Dogen that often just chugs along, with only the occasional sharing of the spotlight (Sprint 22). It saw some minor attention again this sprint, as we decided to add a new value type to the variability subsystem. Well, two value types to be precise, both on the theme of CSV:
comma_separated: allows meta-data values to be retrieved as a set of CSV values. These are just a container of strings.comma_separated_collection: allows meta-data values to be collections ofcomma_separatedvalues.
We probably should have used the name csv for these types, to be fair, given its a well known TLA. A clean up for future sprints, no doubt. At any rate, this new feature was implemented to allow us to process relation information in a more natural way, like for example:
#DOGEN masd.physical.constant_relation=dogen.physical.helpers.meta_name_factory,archetype:masd.cpp.types.class_header
#DOGEN masd.physical.variable_relation=self,archetype:masd.cpp.types.archetype_class_header_factory
For details on relations in the PMM, see the internal stories section.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important e...
Dogen v1.0.25, "Foz do Cunene"
River mouth of the Cunene River, Angola. (C) 2015 O Viajante.

Introduction
Another month, another Dogen sprint. And what a sprint it was! A veritable hard slog, in which we dragged ourselves through miles in the muddy terrain of the physical meta-model, one small step at a time. Our stiff upper lips were sternly tested, and never more so than at the very end of the sprint; we almost managed to connect the dots, plug in the shiny new code-generated physical model, and replace the existing hand-crafted code. Almost. It was very close, but, alas, the end-of-sprint bell rung just as we were applying the finishing touches, meaning that, after a marathon, we found ourselves a few yards short of the sprint goal. Nonetheless, it was by all accounts an extremely successful sprint. And, as part of the numerous activities around the physical meta-model, we somehow managed to also do some user facing fixes too, so there are goodies in pretty much any direction you choose to look at.
So, lets have a gander and see how it all went down.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail.
Video 1: Sprint 25 Demo.
Profiles do not support collection types
A long-ish standing bug in the variability subsystem has been the lack of support for collections in profiles. If you need to remind yourself what exactly profiles are, the release notes of sprint 16 contain a bit of context which may be helpful before you proceed. These notes can also be further supplemented by those of sprint 22 - though, to be fair, the latter describe rather more advanced uses of the feature. At any rate, profiles are used extensively throughout Dogen, and on the main, they have worked surprisingly well. But collections had escaped its remit thus far.
The problem with collections is perhaps best illustrated by means of an example. Prior to this release, if you looked at a random model in Dogen, you would likely find the following:
#DOGEN ignore_files_matching_regex=.*/test/.*
#DOGEN ignore_files_matching_regex=.*/tests/.*
...
This little incantation makes sure we don't delete hand-crafted test files. The meta-data key ignore_files_matching_regex is of type text_collection, and this feature is used by the remove_files_transform in the physical model to filter files before we decide to delete them. Of course, you will then say: "this smells like a hack to me! Why aren't the manual test files instances of model elements themselves?" And, of course, you'd be right to say so, for they should indeed be modeled; there is even a backlogged story with words to that effect, but we just haven't got round to it yet. Only so many hours in the day, and all that. But back to the case in point, it has been mildly painful to have to duplicate cases such as the above across models because of the lack of support for collections in variability's profiles. As we didn't have many of these, it was deemed a low priority ticket and we got on with life.
With the physical meta-model work, things took a turn for the worse; suddenly there were a whole lot of wale KVPs lying around all over the place:
#DOGEN masd.wale.kvp.class.simple_name=primitive_header_transform
#DOGEN masd.wale.kvp.archetype.simple_name=primitive_header
Here, the collection masd.wale.kvp is a KVP (e.g. key_value_pair in variability terms). If you multiply this by the 80-odd M2T transforms we have scattered over C++ and C#, the magnitude of the problem becomes apparent. So we had no option but get our hands dirty and fix the variability subsystem. Turns out the fix was not trivial at all, and required a lot of heavy lifting but by the end of it we addressed it for both cases of collections; it is now possible to add any element of the variability subsystem to a profile and it will work. However, its worthwhile considering what the semantics of the merging mean after this change. Up to now we only had to deal with scalars, so the approach for the merge was very simple:
- if an entry existed in the model element, it took priority - regardless of existing on a bindable profile or not;
- if an entry existed in the profile but not in the modeling element, we just used the profile entry.
Because these were scalars we could simply take one of the two, lhs or rhs. With collections, following this logic is not entirely ideal. This is because we really want the merge to, well, merge the two collections together rather than replacing values. For example, in the KVP use case, we define KVPs in a hierarchy of profiles and then possibly further overload them at the element level (Figure 1). Where the same key exists in both lhs and rhs, we can apply the existing logic for scalars and take one of the two, with the element having precedence. This is what we have chosen to implement this sprint.

Figure 1: Profiles used to model the KVPs for M2T transforms.
This very simple merging strategy has worked for all our use cases, but of course there is the potential of surprising behaviour; for example, you may think the model element will take priority over the profile, given that this is the behaviour for scalars. Surprising behaviour is never ideal, so in the future we may need to add some kind of knob to allow configuring the merge strategy. We'll cross that bridge when we have a use case.
Extend tracing to M2T transforms
Tracing is one of those parts of Dogen which we are never quite sure whether to consider it a "user facing" part of the application or not. It is available to end users, of course, but what they may want to do with it is not exactly clear, given it dumps internal information about Dogen's transforms. At any rate, thus far we have been considering it as part of the external interface and we shall continue to do so. If you need to remind yourself how to use the tracing subsystem, the release notes of the previous sprint had a quick refresher so its worth having a look at those.
To the topic in question then. With this release, the volume of tracing data has increased considerably. This is a side-effect of normalising "formatters" into regular M2T transforms. Since they are now just like any other transform, it therefore follows they're expected to also hook into the tracing subsystem; as a result, we now have 80-odd new transforms, producing large volumes of tracing data. Mind you, these new traces are very useful, because its now possible to very quickly see the state of the modeling element prior to text generation, as well as the text output coming out of each specific M2T transform. Nonetheless, the incrase in tracing data had consequences; we are now generating so many files that we found ourselves having to bump the transform counter from 3 digits to 5 digits, as this small snippet of the tree command for a tracing directory amply demonstrates:
...
│ │ │ ├── 00007-text.transforms.local_enablement_transform-dogen.cli-9eefc7d8-af4d-4e79-9c1f-488abee46095-input.json
│ │ │ ├── 00008-text.transforms.local_enablement_transform-dogen.cli-9eefc7d8-af4d-4e79-9c1f-488abee46095-output.json
│ │ │ ├── 00009-text.transforms.formatting_transform-dogen.cli-2c8723e1-c6f7-4d67-974c-94f561ac7313-input.json
│ │ │ ├── 00010-text.transforms.formatting_transform-dogen.cli-2c8723e1-c6f7-4d67-974c-94f561ac7313-output.json
│ │ │ ├── 00011-text.transforms.model_to_text_chain
│ │ │ │ ├── 00000-text.transforms.model_to_text_chain-dogen.cli-bdcefca5-4bbc-4a53-b622-e89d19192ed3-input.json
│ │ │ │ ├── 00001-text.cpp.model_to_text_cpp_chain
│ │ │ │ │ ├── 00000-text.cpp.transforms.types.namespace_header_transform-dogen.cli-0cc558f3-9399-43ae-8b22-3da0f4a489b3-input.json
│ │ │ │ │ ├── 00001-text.cpp.transforms.types.namespace_header_transform-dogen.cli-0cc558f3-9399-43ae-8b22-3da0f4a489b3-output.json
│ │ │ │ │ ├── 00002-text.cpp.transforms.io.class_implementation_transform-dogen.cli.conversion_configuration-8192a9ca-45bb-47e8-8ac3-a80bbca497f2-input.json
│ │ │ │ │ ├── 00003-text.cpp.transforms.io.class_implementation_transform-dogen.cli.conversion_configuration-8192a9ca-45bb-47e8-8ac3-a80bbca497f2-output.json
│ │ │ │ │ ├── 00004-text.cpp.transforms.io.class_header_transform-dogen.cli.conversion_configuration-b5ee3a60-bded-4a1a-8678-196fbe3d67ec-input.json
│ │ │ │ │ ├── 00005-text.cpp.transforms.io.class_header_transform-dogen.cli.conversion_configuration-b5ee3a60-bded-4a1a-8678-196fbe3d67ec-output.json
│ │ │ │ │ ├── 00006-text.cpp.transforms.types.class_forward_declarations_transform-dogen.cli.conversion_configuration-60cfdc22-5ada-4cff-99f4-5a2725a98161-input.json
│ │ │ │ │ ├── 00007-text.cpp.transforms.types.class_forward_declarations_transform-dogen.cli.conversion_configuration-60cfdc22-5ada-4cff-99f4-5a2725a98161-output.json
│ │ │ │ │ ├── 00008-text.cpp.transforms.types.class_implementation_transform-dogen.cli.conversion_configuration-d47900c5-faeb-49b7-8ae2-c3a0d5f32f9a-inp...
Dogen v1.0.24, "Imbondeiro no Iona"
A baobab tree in Iona national park, Namib, Angola. (C) 2011 Alfred Weidinger

Introduction
Welcome to the second release of Dogen under quarantine. As with most people, we have now converged to the new normal - or, at least, adjusted best one can to these sorts of world-changing circumstances. Development continued to proceed at a steady clip, if somewhat slower than the previous sprint's, and delivered a fair bit of internal changes. Most significantly, with this release we may have finally broken the back of the fabled generation model refactor - though, to be fair, we'll only know for sure next sprint. We've also used some of our copious free time to make key improvements to infrastructure, fixing a number of long-standing annoyances. So, grab yourself a hot ${beverage_of_choice} and get ready for yet another exciting Dogen sprint review!
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there have only been a small number of user facing changes, we've also used the video to discuss the internal work.
Video 1: Sprint 24 Demo.
Add model name to tracing dumps
Though mainly useful for Dogen developers, the tracing subsystem can be used by end users as well. As before, it can be enabled via the usual flags:
Tracing:
--tracing-enabled Generate metrics about executed transforms.
--tracing-level arg Level at which to trace.Valid values: detail,
summary. Defaults to summary.
--tracing-guids-enabled Use guids in tracing metrics, Not recommended
when making comparisons between runs.
--tracing-format arg Format to use for tracing metrics. Valid
values: plain, org-mode, graphviz. Defaults to
org-mode.
--tracing-backend arg Backend to use for tracing. Valid values:
file, relational.
--tracing-run-id arg Run ID to use to identify the tracing session.
With this release, we fixed a long standing annoyance with the file backend, which is to name the trace files according to the model the transform is operating on. This is best demonstrated by means of an example. Say we take an arbitrary file from a tracing dump of the injection subsystem. Previously, files were named like so:
000-injection.dia.decoding_transform-c040099b-858a-4a3d-af5b-df74f1c7f52c-input.json
...
This made it quite difficult to find out which model was being processed with this transform, particularly when there are large numbers of similarly named files. With this release we've added the model name to the tracing file name for the transform (e.g., dogen.logical):
000-injection.dia.decoding_transform-dogen.logical-c040099b-858a-4a3d-af5b-df74f1c7f52c-input.json
...
This makes locating the tracing files much easier, and we've already made extensive use of this feature whilst troubleshooting during development.
Primitives use compiler generated default constructors
Up to now our valgrind output had been so noisy that we weren't really paying too much attention to it. However, with this release we finally tidied it up - as we shall see later on in these release notes - and, would you believe it, obvious bugs started to get uncovered almost immediately. This particular one was detected with the help of two sharp-eyed individuals - Indranil and Ian - as well as valgrind. So, it turns out we were generating primitives that used the compiler provided default constructor even when the underlying type was a built-in type. Taking an example for the C++ reference model:
class bool_primitive final {
public:
bool_primitive() = default;
...
private:
bool value_;
This of course resulted in uninitialised member variables. With this release the generated code now creates a manual default constructor:
class bool_primitive final {
...
public:
bool_primitive();
...
Which does the appropriate initialisation (do forgive the static_cast, these will be cleaned up at some point in the future):
bool_primitive::bool_primitive()
: value_(static_cast<bool>(0)) { }
This fix illustrates the importance of static and dynamic analysis tools, forcing us to refresh the story on the missing LLVM/Clang tools. Sadly there aren't enough hours of the day to tackle all of these but we must get to them sooner rather than later.
Circular references with boost::shared_ptr
Another valgrind catch was the detection of a circular reference when using boost::shared_ptr. We did the classic school-boy error of having a data structure with a child pointing to its parent, and the parent pointing to the child. This is all fine and dandy but we did so using boost::shared_ptr for both pointers (in node.hpp):
boost::shared_ptr<dogen::logical::helpers::node> parent_;
...
std::list<boost::shared_ptr<dogen::logical::helpers::node> > children_;
In these cases, the literature advises one to use weak_ptr, so that's what we did:
boost::weak_ptr<dogen::logical::helpers::node> parent_;
...
std::list<boost::shared_ptr<dogen::logical::helpers::node> > children_;
With this the valgrind warning went away. Of course, the alert reader will point out that we probably should be using pointer containers for the children but I'm afraid that's one for another story.
Allow creating models with no decorations
While we're on the subject of brown-paper-bag bugs, another interesting one was fixed this sprint: our "sanity check model", which we use to make sure our packages produce a minimally usable Dogen binary, was causing Dogen to segfault (oh, the irony, the irony). This is, in truth, a veritable comedy of errors, so its worth recapping the series of events that led to its discovery. It all started with our test packaging script, who needs to know the version of the compiler for which the package was built, so that it can look for the binaries in the filesystem. Of course, this is less than ideal, but it is what it is and sadly we have other more pressing matters to look at so it will remain this way for some time.
The code in question is like so:
#
# Compiler
#
compiler="$1"
shift
if [[ "x${compiler}" = "x" ]]; then
compiler="gcc8";
echo "* Compiler: ${compiler} (default)"
...
elif [ "${compiler}" = "clang8" ]; then
echo "* Compiler: ${compiler}"
else
echo "* Unrecognised compiler: ${compiler}"
exit
fi
However, we forgot to update the script when we moved to clang-9. Now, normally this would have been picked up by travis as a red build, except we decided to return a non-error-error-code (see above). This meant that packages had not been tested for quite a while. To make matters interesting, we did introduce a bad bug over time; we changed the handling of default decorations. The problem is that all test models use the test profile, and the test profile contains decorations. The only model that did not contain any decorations was - you guessed it - the hello world model that is used in the package sanity tests. So once we fixed the package testing script we then had to fix the code that handles default decorations.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Ephemerides
The 11,111th commit was reached during this release.

Figure 1: 11,111th commit in the Dogen git repository.
Milestones
The first set of completely green builds have been obtained for Dogen - both nightlies and continuous builds. This includes tests, dynamic analysis and code coverage.

Figure 2: Builds for Dogen in CDash's dashboard.
The first set of completely green nightly builds have been obtained for the C++ Reference Model. Work still remains on continuous builds for OSX and Windows, with 4 and 2 test failures respectively.

Figure 3: Builds for C++ reference model in CDash's dashboard.
Significant Internal Stories
There were several stories connected to the generation model refactor, which we have aggregated under one sundry umbrella to make our life easier. The remaining stories are al...
Dogen v1.0.23, "Docas de Moçamedes"
Docks in Moçamedes, Namibe, Angola. (C) 2016 Ampe Rogério - Rede Angola

Introduction
Welcome to the first release of Dogen under quarantine. I hope you have been able to stay home and stay safe, in what are very trying times for us all. This release is obviously unimportant in the grand scheme of things, but perhaps it can provide a momentary respite to those of us searching for something else to focus our attention on. The sprint itself was a rather positive one, if somewhat quiet on the user-facing front; of particular note is the fact that we have finally made major inroads on the fabled "generation" refactoring, which we shall cover at length. So get ready for some geeky MDE stories.
User Visible Changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. Since there were only a couple of minor user facing changes, we've used the video to chat about the internal work as well.
Video 1: Sprint 23 Demo.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Generate the MASD Palette
Whilst positive from an end-goal perspective, the growth of the logical model has had a big impact on the MASD palette, and we soon started to struggle to find colours for this zoo of new meta-model elements. Predictably, the more the model grew, the bigger the problem became and the direction of travel was more of the same. We don't have a lot of time for artistic reveries, so this sprint we felt enough's enough and took the first steps in automating the process. To our great astonishment, even something as deceptively simple as "finding decent colours" is a non-trivial question, for which there is published research. So we followed Voltaire's sound advice - le mieux est l'ennemi du bien and all that - and went for the simplest possible approach that could get us moving in the right direction.

Figure 1: Fragment of the old MASD palette, with manually crafted colours.
A trivial new script to generate colours was created. It is based on the above-linked Seaborn python library, as it appears to provide sets of palettes for these kinds of use cases. We are yet to master the technicalities of the library, but at this point we can at least generate groups of colours that are vaguely related. This is clearly only the beginning of the process, both in terms of joining the dots of the scripts (at present you need to manually copy the new palettes into the colouring script) but also as far as finding the right Seaborn palettes to use; as you can see from Figure 2, the new MASD palette has far too many similar colours, making it difficult to visually differentiate meta-model elements. More exploration of Seaborn - and colouring in general - is required.

Figure 2: Fragment of the new MASD palette, with colours generated by a script.
Add org-mode output to dumpspecs
The previous sprint saw the addition of a new command to the Dogen command line tool called dumpspecs:
$ ./dogen.cli --help | tail -n 7
Commands:
generate Generates source code from input models.
convert Converts a model from one codec to another.
dumpspecs Dumps all specs for Dogen.
For command specific options, type <command> --help.
At inception,dumpspecs only supported the plain reporting style, but it became obvious that it could also benefit from providing org-mode output. For this, a new command line option was added: --reporting-style.
$ ./dogen.cli dumpspecs --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Displaying options specific to the dumpspecs command.
For global options, type --help.
Dumping specs:
--reporting-style arg Format to use for dumping specs. Valid values: plain,
org-mode. Defaults to org-mode.
The output can be saved to a file for visualisation and further processing:
$ ./dogen.cli dumpspecs --reporting-style org-mode > specs.org
The resulting file can be opened on any editor that supports org-mode, such as Emacs, Vim or Visual Studio Code. Figure 3 provides an example of visualising the output in Emacs.

Figure 3: Using Emacs to visualise the output of dumpspecs in org-mode format.
Development Matters
This section cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, if you are interested on all the gory details of the work carried out this sprint, please see the sprint log.
Milestones
The 11,000th commit was made to the Dogen GitHub repository during this release.

Figure 4: 11,000th commit for Dogen on GitHub.
The Dogen build is now completely warning and error free, across all supported configurations - pleasing to the eye for the OCD'ers amongst us. Of course, now the valgrind defects on the nightly become even more visible, so we'll have to sort those out soon.
Figure 5: Dogen's CI is finally free of warnings.
Significant Internal Stories
The sprint was dominated by smattering of small and medium-sized stories that, collectively, made up the "generation" refactor work. We've grouped the most significant of them into a handful of "themes", allowing us to cover the refactor in some detail. To be fair, it is difficult to provide all of the required context in order to fully understand the rationale for the work, but we tried our best.
Rename assets to the logical model
One change that was trivial with regards to resourcing but huge in conceptual terms was the rename of assets into the logical model. We'll talk more about the importance of this change in the next section - in the context of the logical-physical space - but here I just want to reflect a little on the historic evolution of this model, as depicted on Table 1.
| Release | Date | Name | Description | Problem |
|---|---|---|---|---|
| v0.0.20 | 16 Nov 2012 | sml |
The Simplified Modeling Language. | It was never really a "language". |
| v0.0.71 | 10 Aug 2015 | tack |
Random sewing term. | No one knew what it meant. |
| v0.0.72 | 21 Oct 2015 | yarn |
Slightly less random sewing term. | Term already used by a popular project; Dogen moves away from sewing terms. |
| v1.0.07 | 1 Jan 2018 | modeling |
Main point of the model. | Too generic a term; used everywhere in both Dogen and MDE. |
| v1.0.10 | 29 Oct 2018 | coding |
Name reflects entities better. | Model is not just about coding elements. |
| v1.0.18 | 2 Jun 2019 | assets |
Literature seems to imply this is a better name. | Name is somewhat vague; anything can be an asset. |
| v1.0.23 | 6 Apr 2020 | logical |
Rise of the logical-physical space and associated conceptual model. | None yet. |
Table 1: Historic evolution of the name of the model with the core Dogen entities.
What this cadence of name changes reveals is a desperate hunt to understand the role of this model in the domain. We are now hoping that it has reached its final resting place, but we'll only know for sure when we complete the write up of the MASD conceptual model.
Towards a physical Model
The processing pipeline for Dogen remains largely unchanged since its early days. Figure 6 is a diagram from sprint 12 describing the pipeline and associated models; other than new names, it is largely applicable to the code as it stands today. However, as we've already hinted, what has changed in quite dramatic fashion is our understanding of the conceptual role of these models. Over time, a picture of a sparse logical-physical space emerged; as elements travel through the pipeline, they are also traveling through this space, transformed by projections that are parameterised by variability, and ultimately materializing as fully-formed artefacts, ready to be written to the filesystem. Beneath those small name changes lies a leap in conceptual understanding of the domain, and posts such as the The Refactoring Quagmire give you a feel for just how long and windy the road to enlightenment has been.
![Processing pipeline](https://raw.g...