{kind=link}
{kind=link}
{kind=link}
In this project, I created a convolutional neural network to classify traffic signs. The model was trained and validated with data from the German Traffic Sign Dataset.
A random image from the training dataset was chosen and plotted to have an idea of what the images look like. Then an exploration of the datasets was performed using numpy and python and produced the following:

The data was augmented to provide an extra 10000 images in the training dataset. The script that executes this is in the root of the repository and is named 'augment_data.py'. The images were augmented using a variety of techniques such as Rotating the image, translating it to a different position and changing the shear and the brightness. In the augmentation process a random image was chosen 10000 times and augmented then added to the existing dataset to produce a new dataset stored in a file named 'train_augmented.p'. * Note This script would need to be executed prior to the running of the notebook *
Training Dataset

Validtion Dataset

Test Dataset

The 3 above charts shows the class distribution over the training, validation and test set respectively(After augmentation). As we can observe the data is skewed in favor of certain classes but this is consistent across all the datasets so there was no need to supplement the training dataset to have a uniform distribution across classes.
- Converting it to grayscale along with applying a histogram equalization to reduce the color channels that the network needs to focus on to 1 so that it can train better.
- Normalization by simply applying the formula (pixel-180)/180 to the pixels in the images, to keep the values between -1 and 1 instead of 0 and 255.
The final model consisted of the following layers:
| Layer | Description |
|---|---|
| Input | 32x32x1 grayscale image image |
| Convolution 3x3 | 1x1 stride, valid padding, outputs 28x28x6 |
| RELU | |
| Dropout | Keep probability of 0.8 |
| Max pooling | 2x2 stride, valid padding, outputs 14x14x6 |
| Convolution 3x3 | 1x1 stride, valid padding, outputs 10x10x16 |
| RELU | |
| Dropout | Keep probability of 0.8 |
| Max pooling | 2x2 stride, valid padding, outputs 5x5x6 |
| Flatten | Input 5x5x16, output 400 |
| Fully connected | Inputed 400, output 120 |
| RELU | |
| Dropout | Keep probability of 0.8 |
| Fully connected | Inputed 120, output 84 |
| RELU | |
| Dropout | Keep probability of 0.8 |
| Fully connected | Inputed 84, output 43 |
This architecture is a variation of the LeNet Architecture that was updated from previously recognizing characters from the MNIST dataset to recognizing traffic signs. A dropout with a keep probability of 80% was added at each layer in the network and resulted in a improvement in the networks performance on the Traffic Sign data. The reason LeNet was chosen is due to its reputation for being a suitable architecture for OCR and Document recognition along with being recommended as a starting point for the project from the Udacity mentors :)
The model was trained with a learning rate of 0.001 over 20 EPOCHS and a batch size of 128. The Adam algorithm was then used to minimize the loss in the data passed to the network compared to the ground truth labels.
My final model results was an accurracy of about 96% on the validation set.

And about 93% accuracy on the test set

Here are five German traffic signs that I found on the web:





Here are the results of the prediction:
| Image | Prediction |
|---|---|
| General Caution | General Caution |
| Road Narrows on Right | Road Narrows on right |
| Beware of ice/snow | Beware of ice/snow |
| Turn right ahead | Speed Limit(60km/h) |
| Turn left ahead | Turn left ahead |
The model was able to correctly guess 4 of the 5 traffic signs, which gives an accuracy of 80%. This is compares somewhat equivalently to the 93% achieved on the test set.
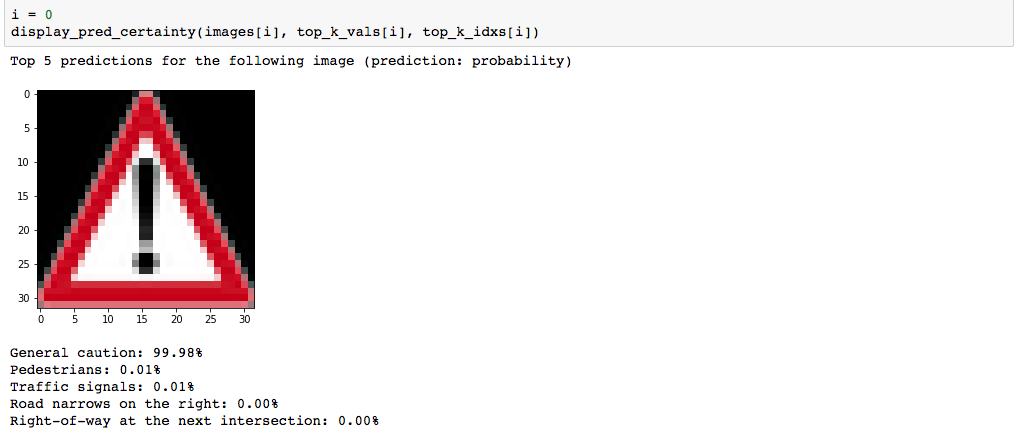
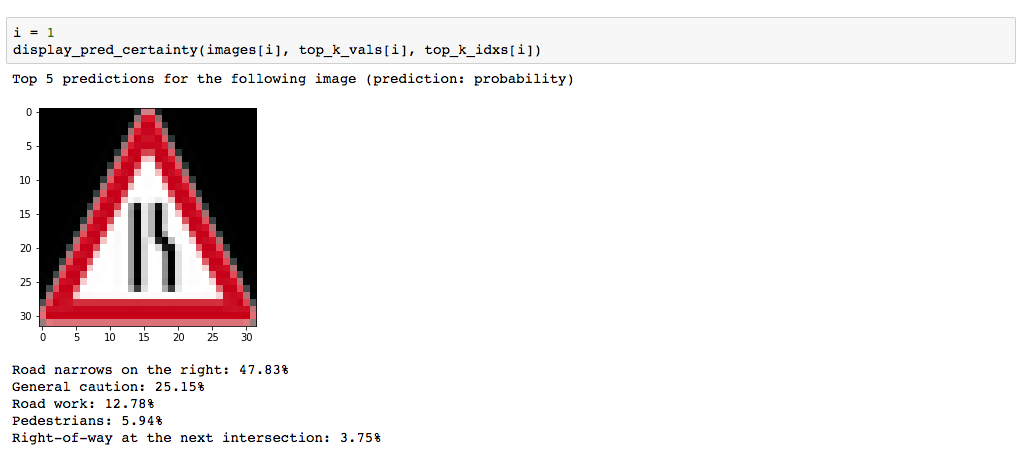
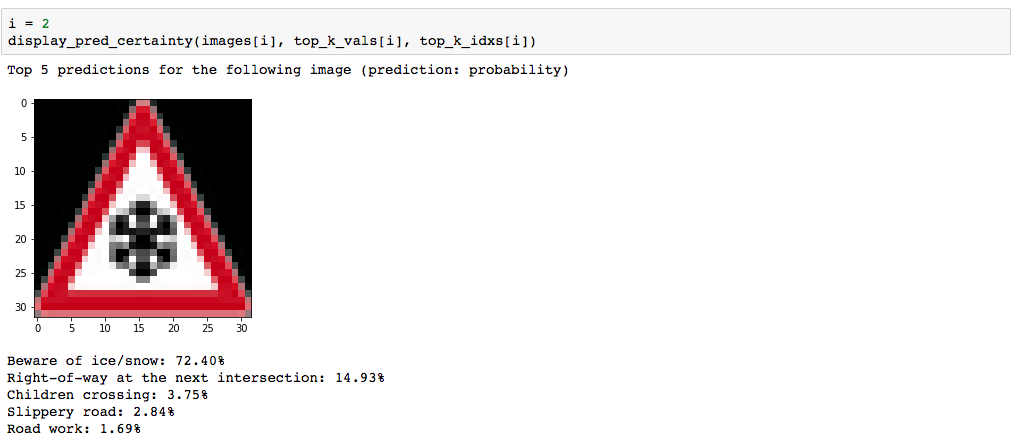

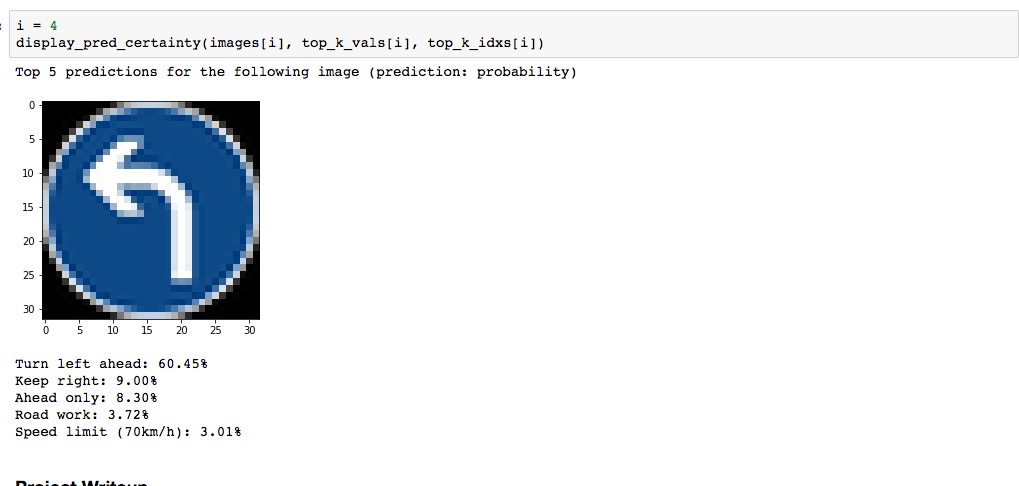
I found it interesting that for the 4th image(i=3) None of the top 5 softmax probabilities was correct. I'm unsure what this means about the quality of my architecture and the steps I took.