Humans observing images of a place unknowingly deduct a great deal of information.
Automation of this process requires the algorithm to understand what details are relevant.
It can be assumed that the relevant information for finding a geographic location in the city is present in street signs.
This code was created by undergrads as part of a half-year long project, with the goal to find the geographic location of a place pictured in a set of photo, based on the text present (Assuming the photos can create a panorama).
The project uses CharNet for the text detection.
- fuzzywuzzy 0.18.0
- python-Levenshtein 0.12.0
- gmplot 1.4.1
- googlemaps 4.4.2
- numpy 1.18.4
CharNet dependancies
- torch 1.4.0
- torchvision 0.5.0
- opencv-python 3.4.2
- opencv-contrib-python 3.4.2
- editdistance 0.5.3
- pyclipper 1.1.0
- shapely 1.7.0
- yacs 0.1.7
If you're having probelms downloading the correct torch/torchvision version, please try using:
pip install torch===1.4.0 torchvision===0.5.0 -f https://download.pytorch.org/whl/torch_stable.htmlTo check a signle scene use:
--single_scene ".\scene" --results_dir ".\output"scene should be a folder with a set of photos.
for checking multiple scenes at once, order the images in seperate folders and input the parent folder. e.g.:
├── Parent
│ ├── scene 1
│ ├── scene 2
│ ├── scene 3and then use:
--scenes_dir ".\Parent" --results_dir ".\output"- If you know the photos are ordered by name, you can add the option
--dont_reorderto vastly improve runtime. - if
--results_dirisn't given, the output will be generated in the input directory.
Hila Manor and Adir Krayden
Supervised and guided by Elad Hirsch
A video showcasing an overview of 3 runs of the projects:
- A simple scene.
- A simple scene, yet had problems with Google's GeocodingAPI.
- A complicated scene.

A video showcasing a run that used intersecting locations (close places) to find the location
- Panorama Creation
- Find images order
- Random images order input is assumed and fixed
- Feature-based matching
- Estimate focal length
- based on homographies
- Inverse cylindrical warp
- Use cylindrical panoramas to enable 360° field-of-view.
- Stitch panorama
- Stitch with affine transformation to fix ghosting and drift (camera can be hand-held, and not on a tripod)
- Find images order
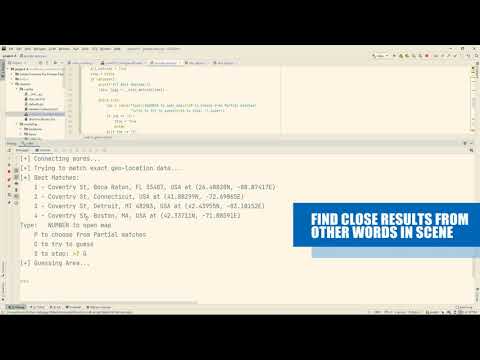
- Signs Extraction
- Split the panorama to windows
- enables runs on weaker GPUs
- Extract text using CharNet on each window
- Splitted words cause a new search in a centered window
- CharNet “fixes” detected text by comparing to a synthetic dictionary
- Concatenate words to signs
- Match geometry: close words vertically or horizontally
- Match colors: validate that the backgrounds colors are from the same distribution
- Catalogue signs by gradeing similarity to street-signs
- Background color
- Keywords presence (e.g. avenue, st.)
- Appearance in online streets list
- Filter out similar variations and long signs
- Split the panorama to windows
- Location Search
- Query Google’s GeocodeAPI only for street signs
- This API doesn’t understand points of interest
- Query Google’s PlacesAPI for each of the other signs individually.
- This API can’t handle intersecting data (2 businesses in 1 location)
- Search for close (geographically) responses
- Display options to choose from, and open a marked map
- Query Google’s GeocodeAPI only for street signs
- CharNet
- Xing, Linjie and Tian, Zhi and Huang, Weilin and Scott, Matthew R, “Convolutional Character Networks”, Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019
- Heung-Yeung Shum and R. Szeliski, Microsoft Research, “Construction of Panoramic Image Mosaics with Global and Local Alignment”, Sixth International Conference on Computer Vision and IJCV, 1999