The third exercise in the course Neural Networks for Computer Vision.
UCF101 dataset was used to train CNN classification architecture to classify videos.
There are two parts to the exercise:
First, an early fusion video classification architecture is implemented.
Second, a SlowFast video classifier using a ResNet-50 architecture and PytorchVideo.
Submitted By:
- Tal Goldengoren
- Guy Kabiri
Table of Contents:
The dataset used in this task is UCF101.
UCF 101 is a set of action recognition videos from YouTube, with 101 action categories.
In this exercise, five classes were used:
Basketball, Rope Climbing, Biking, Diving, Pizza Tossing.















import numpy as np
import pandas as pd
import torch
import cv2
import matplotlib.pyplot as plt
import seaborn as sns
import osphases = [ 'train', 'valid', 'test' ]
paths = { p: 'data/{}'.format(p) for p in phases }df = pd.DataFrame(columns=[ 'name', 'class', 'frames', 'phase' ])for p in phases:
for cls in os.listdir(paths[p]): # iterate over the classes of each phase
class_path = os.path.join(paths[p], cls)
videos = [ f for f in os.listdir(class_path) if os.path.isfile(os.path.join(class_path, f)) ]
for vid in videos:
video_path = os.path.join(class_path, vid)
cap = cv2.VideoCapture(video_path)
df = df.append({
'name': vid,
'class': cls,
'frames': int(cap.get(cv2.CAP_PROP_FRAME_COUNT)),
'phase': p
}, ignore_index=True)
cap.release()
for p in phases:
print('Samples in {} set: {}'.format(p, len(df[df['phase']==p])))Samples in train set: 522
Samples in valid set: 128
Samples in test set: 18
def plot_class_count(df):
fig = plt.figure(figsize=(15, 7))
ax = sns.countplot(x='class', hue='phase', data=df)
for p in ax.patches:
ax.annotate(p.get_height(), (p.get_x()+0.1, p.get_height()+0.15))
plot_class_count(df)
def plot_frames_dist(df):
# fig = plt.figure(figsize=(20, 10))
ax = sns.displot(df, x='frames', hue='phase', kde=True, element='poly', col='class', )
plot_frames_dist(df)
The first part of the exercise includes two early video processing methods, Early Fusion, and Late Fusion.
Unlike image classification, where a single image has three dimensions, video classification adds a fourth dimension - Time/Frame.
In order to make a CNN model suitable for video classification, a modification is required.
Several methods exist for dealing with this issue, including Early Fusion, Late Fusion, Slow Fusion, and Fast Fusion.

Implementing this exercise required either Early Fusion or Late Fusion, and Early Fusion was selected.
In a CNN model, the first convolution layer has an input of three channels, representing the three color channels in the image.
During video-CNN processing, the first layer handles 3 channels of color simultaneously in each frame.
How it works:
Video samples representing batch will be [ B, F, 3, H, W ]. Image CNN architectures, however, utilize 2D CNN blocks.
Additionally, all of the frames must be analyzed simultaneously. There is a reshape required, so the first convolution layer will be performed on all frames in the architecture.
Therefore, the new batch size dimensions are [ B, 3F, H, W ].
It means two things, each batch should be modified at runtime, and the first CNN layer in the architecture should be changed in advance to be in the shape of [3F, H, W].
Finally, when dealing with pre-trained architecture, the last fully connected layer should be modified as well to the desired number of classes.
Legend:
B- batch sizeF- number of framesC- number of channelsH- heightW- width
Various configurations were evaluated to determine which was the best.
EfficientNet, ResNet, and ResNeXt architectures were used.
The Adam and AdamW optimizers were tried, as well as different learning rates and schedulers.
Additionally, two methods of converting video into frames were used:
- Static-Batch: Data preprocessing by selecting a subset of frames from each video and training only on these frames.
As the frames were already stored in the storage and only needed to be loaded, training progress should be incredibly rapid. However, a small dataset may quickly overfit.
Each frame was sampled by a fixed step in this method. step = len(total_frames) / len(subset_frames).

- Dynamic-Batch: Sample a random group of frames each time.
This would be slower, but it could prevent overfitting since every time a video is loaded, a different set of frames is processed by the network.

The following graphs show a sample of different configurations that were tried.





Finally, the preferred configuration was as follows:
- Pre-trained ResNet-50.
- Pre-processed data (static dataset - the same frames were used in each video during training, instead of random ones).
- 32 frames for each video.
- Optimizer: Adam.
- Scheduler: ReduceLROnPlateau (factor=0.8, patience=2).
- Learning rate: 1e-5.
- Batch-size: 8.
- Epochs: 100.





As can see above, we achieved accuracy of almost 0.9 and loss a little less than 0.7.
The SlowFast architecture handles video in two ways.
In order to capture spatial semantics, the first approach uses a low frame rate, which will be called the Slow pathway.
A high frame rate is used in the second method, called the Fast pathway, to capture motion.
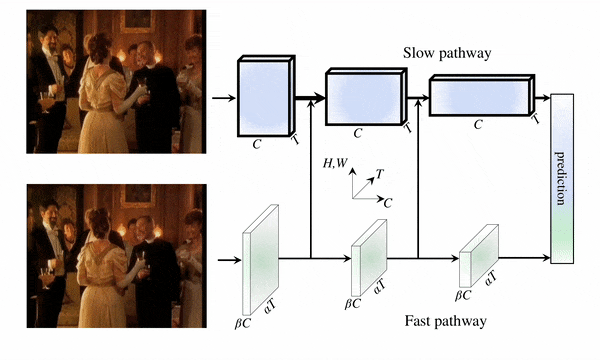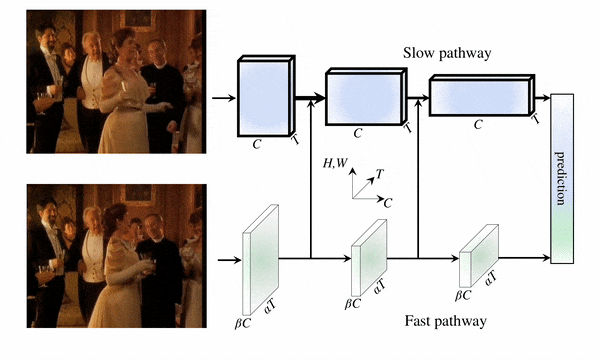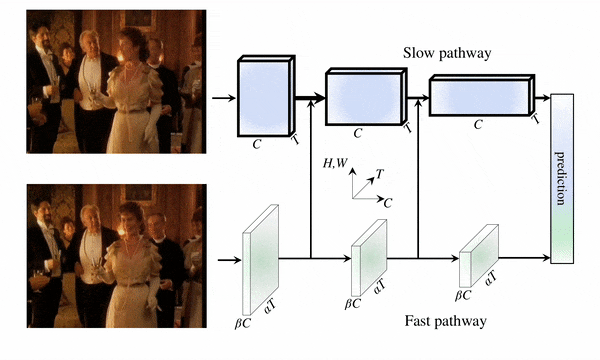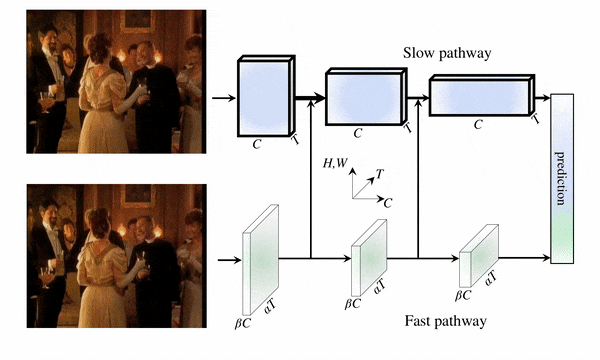
While both pathways use ResNet as their backbone, unlike the previous model, these use 3D CNN blocks.
A small number of channels is used to keep the Fast pathway fast since it samples many more frames than the Slow pathway.
In addition, the Fast pathway results are fed into the Slow pathway to improve prediction (taking into account the different shapes in each pathway).
The results from the Slow pathway are not fed into the Fast pathway since the researchers found no improvements while executing it.
SlowFast's training phase required some modifications in the data processing.
Firstly, SlowFast splits into 2 pathways, each of which consumes a different number of frames.
Second, the tensor shape differs from the early method.
While the early methods architecture was fed by [ B, F, 3, H, W ] tensors, the SlowFast architecture was fed by [ B, 3, F, H, W ].
In order to use the same dataset, when handling a SlowFast model, the tensor needs to be reshaped into the correct dimensions and then split into two tensors.
Getting the [ B, 3, F, H, W ] shape for the fast pathway, and the [ B, 3, F/4, H, W ] shape for the slow pathway.
Configuration used:
- Pre-trained SlowFast.
- Dynamic data (sample random frames from a video at each epoch).
- 32 frames for each video.
- Optimizer: ASGD.
- Scheduler: ReduceLROnPlateau (factor=0.9, patience=4).
- Scheduler: CosineAnnealingLR
- Learning rate: 1e-3.
- Batch-size: 4.
- Epochs: 100.
Despite trying several different configurations, we were unable to achieve good results with the SlowFast model.
Therefore, we can't compare the models since SlowFast should yield better results than the simpler methods.




