This application was developed by Maximiliano Meyer during his final work titled "Development of a classifying tool to detect false transactions in credit card operations in real-time using Machine Learning" in the Computer Science course at the University of Santa Cruz do Sul - Unisc.
This research and project were developed in the first half of 2021 as a conclusion work of Computer Science course at the University of Santa Cruz do Sul - Unisc.
- Works with any fraudulent credit cards transactions dataset;
- Data persistency, since the created model is a local file. After the training process user can load the model on every classification, distribute it, etc;
- Automated search for the best set of parameters and values for each dataset;
- Easy to configure and use
Below you can see the tool in action in a video, audio in portuguese only.
The following topics will be covered here:
- Extreme Gradient Boosting
- Some parameters used in this tool
- Grid Search CV
- Balanced Bagging Classifier
- Recall value
- Dataset
- Usage and tests
- Next steps
This tool uses the Extreme Gradient Boosting (XGB) algorithm in its construction.
As a boosting algorithm, XGB implements several simpler algorithms in order to achieve a more complete and accurate classification result at the end.
In practice, algorithms of this type work as sequential decision trees since the value that was predicted at n will be taken into account for the prediction at n +1 where at every new tree the algorithm will give bigger weight to wrong predictions and smaller for the correct ones.
This way with a new set of random columns and values XGB tends to learn how to deal with the peculiarities of the WRONG classification from the previous round.
One of the highlights of the XGB is precisely the fact that it has dozens of configurable parameters.
These are the main ones used by this tool:
- Eta: Represents the learning rate, called eta in the official XGB documentation.
- N_estimators: Refers to the number of decision trees that will be created by the model during training.
- Min_child_weight: Defines the minimum sum of weights necessary for the tree to continue to be partitioned. The higher this value, the more conservative the algorithm will be and the less superspecific relationships will be learned.
- Max_depth: Represents the maximum depth of the tree. Like the previous parameter, it has the same control relationship with overfitting. However, in this case, the higher the more likely it is to overfit.
- Subsample: Determines the portion of random training data that will be passed to each tree before they increase by another level.'
- Colsample_bytree: Similar to the above, determine the portion of columns that will be given randomly when the trees are created.'
- Scale_pos_weight: Controls the balance between positive and negative weights. It is recommended for cases with a great imbalance between classes.
Grid Search CV is a module of the Scikit Learn library used to automate the parameter optimization process that XGB makes necessary. In addition to creating as many simulations as necessary through a data crossing, the tool is also capable of evaluating the performance of each of these arrangements using a metric defined by the user.
To use it, we just need to define which parameters will be tested, which will be the possible values for each scenario and the number of Cross Validations (CV) to be performed. The CV value represents the number of divisions in which the dataset will be partitioned. The technique consists of generating n cuts of the same size in order to achieve a greater variety of training and testing scenarios in a simulation.
For example: If we use a dataset with 70 thousand records and define CV value being 7, then this dataset will be divided into 7 parts of 10000 records each. Subsequently, these 7 datasets will undergo training and validation, alternating which part is being used as test and training until all combinations are performed, as shown below.

Part of the Imbalanced Learn library (a branch of Scikit Learn) this tool aims to diminish the damage of highly unbalanced classes. Using it, it is possible to create records for classes with undersampling, remove records in classes with oversampling and perform resampling, a technique in which the small amount of data available from an unbalanced class is used to estimate a population parameter.
To measure how correct it is the classification recall metric is used. With it, we know the percentage of values belonging to a given class that were identified among all the possibilities of the dataset. The recall metric is, usually, used when it seeks to reduce false negatives.
For training and results validation was used a public dataset, with real data collected from the digital payment platform Vesta, which was made available in Kaggle.
The dataset contains more than 590,000 credit card purchase and sale records labeled as fraudulent or non-fraudulent. The file is composed of 394 columns.
To run this tool, any IDE that supports projects developed in Python language or even the Windows command terminal can be used. Regardless of the option chosen, it is necessary to have Python installed on the machine. The application was not yet designed for use on operating systems based on Linux, Mac OS, or any others.
In the tests presented here, a machine equipped with a 4-core Intel Core i7-4720HQ processor and support for up to 8 threads, Nvidia GeForce GTX 960M graphics card with 2 GB of dedicated memory, 8 GB of RAM, and SSD installed was used. The operating system is Windows 10 and the development environment is Pycharm.
In this process, the mentioned dataset before was used. In this stage, the dataset was divided into 2 files: training.CSV, containing about 550 thousand transactions, and classification.CSV, with approximately 40 thousand transactions unseen to the model to generate a totally exempt rating. It is noteworthy that the cuts maintained similar false transaction rates, with 3.51% and 3.43%, respectively.
The following steps were performed (for a more detailed explanation, please refer to the file TCII - Maximiliano Meyer.pdf above - in portuguese):
1 - The initial action to be taken is setting up the environment for the initial run. For this, the user must edit the config.txt file, adding the label of the fraud column and the columns to be ignored in the correlation analysis stage. Should be added the training .CSV file in the Dataset folder. After performing these steps it is now possible to start the program
2 - The first step to be taken when working with a new dataset is to apply the data wrangling actions to the data via option 1 on the menu. The program then asks, this is a standard task, which file will be used in the chosen step. As there is only 1 file in the folder, just inform the number that identifies it and the process starts running.
Two files will be exported at the end of the execution of this pipeline. The first one, called pre_processing_done.csv is the result of the input dataset after going through the initial data processing and having the correlated and non-numeric columns removed and the NaN values NaN filled. This file will be exported to the Dataset folder and will be used in all future training and optimization steps.
The second file created upon completion of the data wrangling step is columns.TXT, which will be used during the sorting process to ensure that the transactions to be sorted will have the same column settings as the template created. Without this standardization, it is impossible to use the model and the data to be classified together.
3 - With the data wrangling done the training can be made. The user has the option to train using the default values or use another menus option to automatically search for the optimized values.
4 - The last step is to classify the unseen records with the generated model. The result will be saved as .CSV to the Dataset folder.
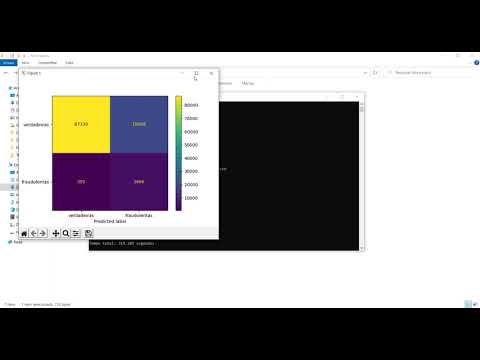
In this test, the tool achieved a recall of 0.87.

If you want to contribute to this project, your efforts are very welcome. This is a list of some open points:
- Diminish processing time for some steps, like Grid Search optimization. The way to do this could be distributed computing, for example, or any other else;
- Portability to Mac and Linux family OSs;
- Validation to different datasets to search for punctual issues;
- Any contribution and new ideas are appreciated;
The use of this tool is free as long as the source is informed.
For updates, clone or contribute to the project -> https://github.com/Evilmaax
Contact -> MaximilianoMeyer48@gmail.com
Version 0.1