@ Pikachu
目标是能实现一个web/mobile app,提供有效的菜谱搜索。平时生活中搜索菜谱时,往往结果并不是很理想,菜谱的质量参差不齐。所以我们希望能够控制搜索的各项指标权重,来获得最佳的用户搜索结果和体验。
技术栈选择全栈Javascript: MEAN,也就是MongoDB,Express.js, Angular.js, Node.js.
搜索引擎采用ElasticSearch。
主要技术栈介绍:
- MongoDB: MongoDB是一个开源的基于文件的NoSQL数据库,有便于开发和扩展的特性。
- Express.js: Express是一个快速,无偏见,极简的Node.js网站架构,有大量优秀的中间件可以使用。
- Angular.js: Angular是移动web和桌面web的开发平台,提供一整套web框架。
- Node.js: Node.js是基于Google Chrome的V8 JavaScript引擎的Javascript runtime,具有事件驱动,非阻塞I/O等特性。
- Ionic: Ionic是一个基于Angular的HTML5 Hybrid App开发框架,能够快速方便地开发出跨平台的交互式移动端app。
- ElasticSearch: ElasticSearch是基于Lucene的搜索引擎,提供分布式,多租户,全文搜索,RESTful API和JSON文件功能。
系统架构:

展示层:web前端架构由Angular.js实现,结合Ionic,可以生成Hybrid的移动端app。
业务逻辑层:主要由控制器(Controller),网页爬虫(Web Crawler)组成,使用Node.js和流行的Express框架实现。
持久层:使用MongoDB作为抓取数据存储的数据库,ElasticSearch用作搜索引擎。
最初选择技术时,主要有两种爬虫作为备选:
- Python Scrapy
- Node.js simplecrawler
最终选择了Node.js的爬虫框架。Python Scrapy虽然更完整,能够适用企业级的应用,但是考虑应用场景,可以采用更轻便的框架,与控制器相同的技术栈便于进行快速地开发。
完成技术的选型只是旅程的第一步,紧接着就遇到了爬虫被封禁的问题:

为了解决这个问题,我们需要了解目前常见的反爬虫机制。基本的反爬虫机制可以分为以下3个大类:
A. 异常流量/高下载率 - 特别是时间内,从单一的短的客户端/或IP地址发送的请求。
B. 在网站上重复执行的任务 - 基于假设是人类用户将无法一直执行相同的重复任务。
C. 通过检测蜜罐 - 蜜罐通常是那些对于一个普通用户不可见,而只有爬虫可见的链接。当爬虫试图访问该链接时,警报就会触发。
针对这些反爬虫机制,可以通过以下策略来避开或者绕过这样的封锁:
A. 轮换IP地址
IP黑名单是可能的爬虫的最简单的方法。通过创建IP地址池,并使用不同的IP发出请求,将使服务器很难检测到爬虫。
对策:
- 使用来自代理服务的IP列表,一定的时间间隔后随机挑选一个IP
B. 轮换Cookie
Cookies是加密存储在客户端的数据,有的网站使用Cookie来标识用户。如果用户在客户端发送高频请求,有可能被认定为可疑爬虫,从而拒绝访问。
对策:
- 自定义和管理cookie池
- 发送不包含cookie的请求到服务器,解析返回的包并设置cookie值; 它存储在cookie的收集器;
- 从cookie收集器中获取cookie,如果cookie不可用,则从cookie收集器中将其删除;
- 利用时间戳管理cookie收集器,这样是为了让爬虫每次首先获得的距离当前时间最远的cookie。
- 关闭Cookies
- 通过禁用cookie,可以帮助防止某些网站通过使用cookie来标识用户,从而导致爬虫被封禁。
C. 用户代理欺骗
伪装成浏览器的方法之一是修改用户代理(User Agent)。用户代理是在请求Header中的字符串,它包含用户代理信息,例如网络浏览器,客户端,操作系统等的版本。
对策:
- 通过用户代理的列表或者随机生成器,随机选择或生成对于每个请求的欺骗用户代理。设置为用户代理一个常见的网页浏览器,而不是使用默认的请求客户端。
D. 限制速度
降低抓取速度,善待网站,而不要让其不堪重负,或者DDoS攻击服务器。
对策:
- 在每个请求之间的放入一些随机休眠时间
- 在抓取一定的网页数后,添加一些延迟
- 使用尽可能小的并发请求数目
E *避免重复性爬行模式
有些网站实现智能防抓取机制,从而重复操作将有可能检测为爬虫。为了让爬虫看起来像一个人,加上随机点击,鼠标移动,随机行为等。使用自动化测试工具,如可模拟器正常的“人的行为”。
F *小心蜜罐
这些蜜罐(HoneyPot)通常是链接,普通用户无法看到,但爬虫则可以。他们有可能在CSS样式中显示“display: none”。因此,蜜罐的检测可能会非常棘手。
以上"反反爬虫"策略也可阅读博文Anti Anti-spider Strategy
对于网页服务来说,后端主要功能在于提供API。而Express就提供了很方便的路由机制,并且在中间件中可以进行一些诸如提供静态页、验证、过滤等功能。
MongoDB和Node.js有官方的原生驱动,不过为了便于建立数据模型,使用了Mongoose,好处在于可以提供较为方便的schema验证管理,而基础的查询操作依然可以使用原生驱动的API,以获得更高性能。
抓取的数据存储在MongoDB中,MongoDB本身有全文搜索功能,不过仅限于英文,对于中文全文搜索的支持比较弱。因此我们考虑使用支持中文全文搜索的引擎ElasticSearch和Apache Solr。
经过权衡,我们最终选择了ElasticSearch,主要原因在于:
- 对RESTful API的支持更好;
- 搜索性能上更胜一筹,扩展性更强;
- 有官方的Javascript库。
为了让ElasticSearch能够获取存储在MongoDB中的数据,我们需要对MongoDB和ElasticSearch进行连接。mongo-connector 是一个连接器,可以连接和同步MongoDB的数据到目标系统,比如Apache Solr,ElasticSearch,甚至MongoDB本身。
配置mongo-connector的难点在于配置MongoDB的复制集模式。在这种模式下,MongoDB内容的变化可以为mongo-connector所用,并传入目标系统以进行数据同步。
更完整的配置过程可以参考博文MongoDB & ElasticSearch For Full Text Search In Chinese
配置完成以后,重点则在于如何设置权重,让搜索结果更为合理和优化。因为抓取的数据包含了rating, likes, cooked, dishes, comments等数据(评分、收藏人数、做过人数、做过次数,评论数)。我们利用了ElasticSearch本身的function-score-query,对用户输入的查询关键词所得分数进行加权处理,包含rating, dishes,likes,cooked等,最终得出的数据综合考虑了用户的输入以及菜谱本身的质量。
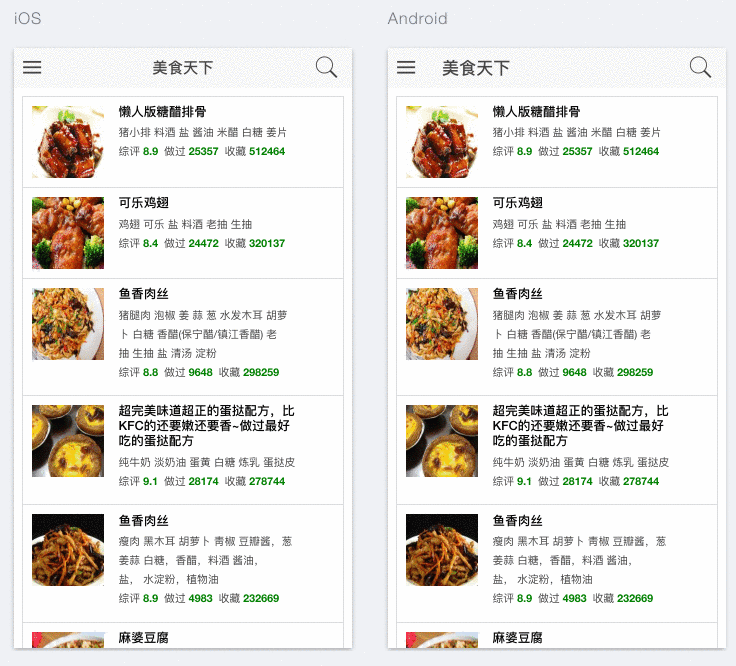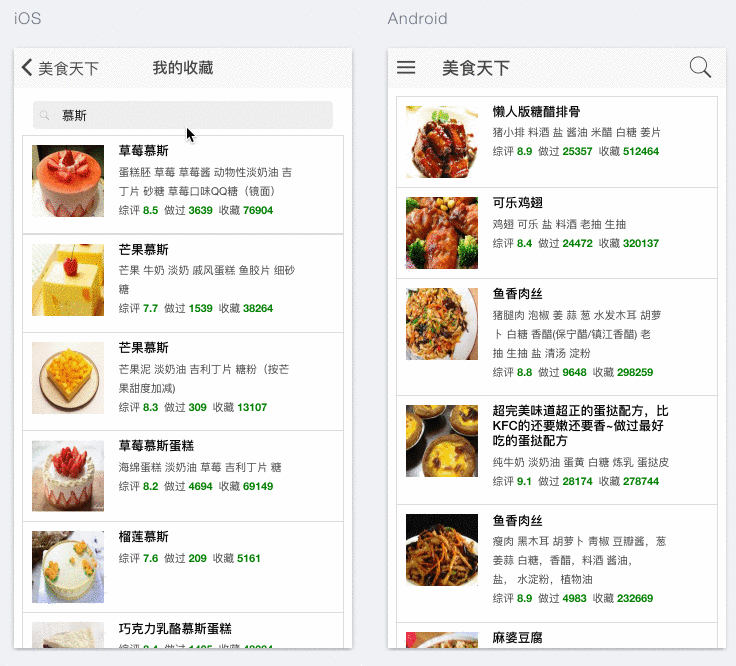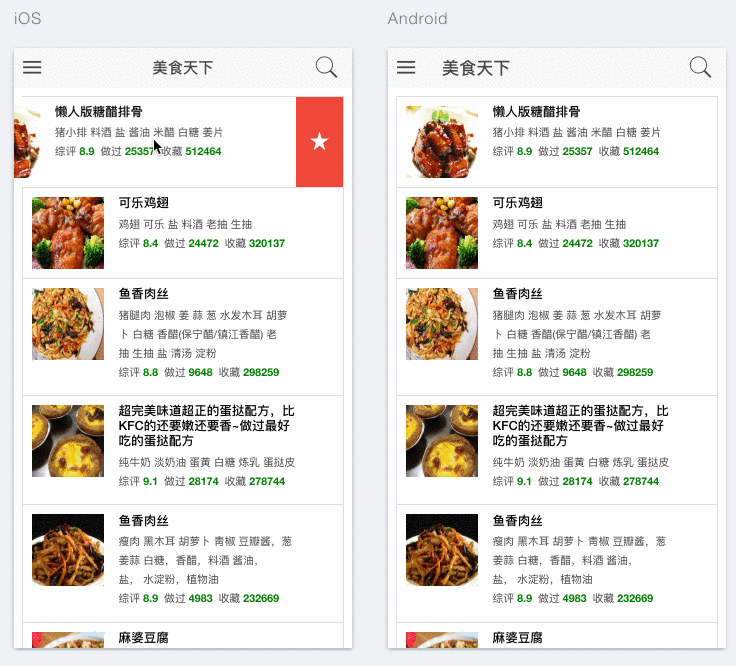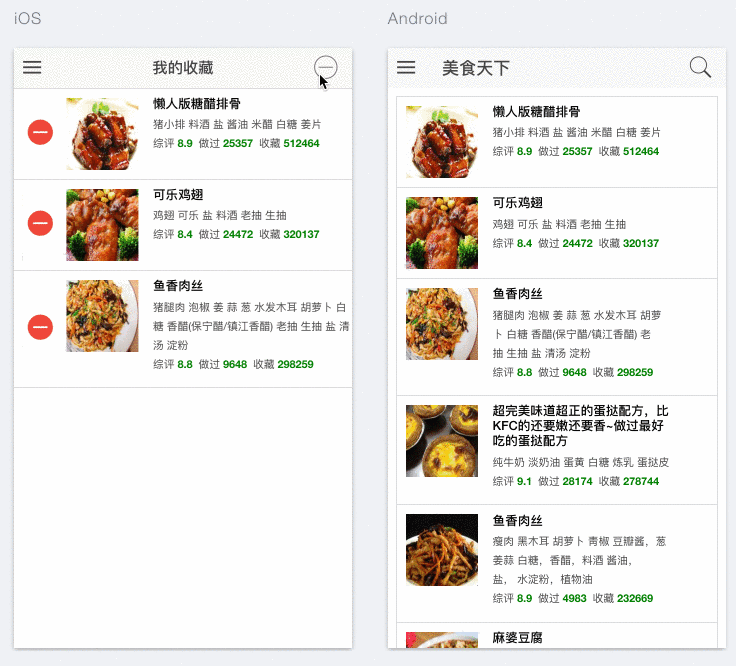
使用Ionic + Angular可以很好的实现Hybrid app开发,利用Ionic的模拟器,能够在网页上直接模拟移动端iOS和Android的效果,并且能够模拟手势操作。本项目中,首页和菜谱搜索均使用了ion-list来呈现API返回结果列表。List是在移动端被广泛使用的一种简洁而有效的呈现方式。它不仅可以承载图片、文本信息,亦可实现手势交互,如滑动、拖拽、下拉更新等。以本项目为例,用户可以通过向左滑动菜谱将其添加至收藏菜单。除List之外,另外一种实现方式是使用Ionic Card,效果可参考Google Now cards.
有关Hybrid App,可以参考Xinyue的原创博文浅谈Hybrid Mobile App
- 增加推荐系统,在用户账户的基础上做出个性化的推荐和搜索结果
- 拆分后端,采用微服务架构,分离控制器、网页爬虫、推荐系统
- 部署到云平台,诸如Bluemix,Heroku等
答:ElasticSearch + MongoDB具体实现过程: https://github.com/BitTigerInst/Pikachu/blob/master/docs/mongodb_elasticsearch_setup.md
答:MEAN stack选型,主要考虑了数据读取存储的
- 便利性:MongoDB可以方便地存储类似JSON的BSON文件,而在前端的API请求中,返回的JSON与存储的BSON结构内容类似
- 灵活性:MongoDB是schemaless,在开发过程可以灵活地增加field
答:最开始部署到了IBM Bluemix上,因为是开源Cloud Foundry的PaaS,能够很快的得到Node.js runtime; MongoDB 采用了mLab host的MongoB; 目前后端services host均在本地,未来会考虑部署到服务器上,比如Heroku, Bluemix,都是备选项
答:一台机器,使用多个IP proxy进行抓取
答:如果不使用IP Address Rotation的话,还是很可能被封的;也有很多网站对于来自AWS、阿里云等IP段的爬虫进行封禁
- Anti Anti-spider Strategy
- HOW TO PREVENT GETTING BLACKLISTED WHILE SCRAPING
- 防止爬虫被墙的方法总结
- 应对反爬虫之换Cookie
- node-simplecrawler
- cheerio
- Node.js Web Crawler Tutorials
- Solr vs ElasticSearch
- StackOverflow: Solr vs. ElasticSearch
- MongoDB & ElasticSearch For Full Text Search In Chinese
- 用 mongodb + elasticsearch 实现中文检索
- 使用Mongo Connector和Elasticsearch实现模糊匹配
- MongoDB 数据自动同步到 ElasticSearch
- Resyncing the Connector
- mongo-connector原理及改造
- 查询与过滤条件的合并
- MongoBD + Solr全文搜索的历程*
- mongo-connector原理及改造
- 使用 Elasticsearch 实现博客站内搜索
- StackOverflow: How to use Elasticsearch with MongoDB?
- Optimizing Search Results in Elasticsearch with Scoring and Boosting
- Elasticsearch: The Definitive Guide
- Elasticsearch权威指南(中文版)
- ElasticSearch Javascript API
- Elasticsearch Reference