Fetch data, feed to Zotonic pages.
- Run multiple scrapers, multiple URLs per scraper, multiple rules per URL
- Run all scrapers fully automatic at a configurable interval
- Connect rules to page properties
- Store scraped data as page properties
- Includes rules for Google's rich snippets for products
- Scraped data is compared to existing data, so only the changes are presented for copying over
A couple of features come with the libraries installed alongside:
- Data is extracted using XPath 1.0 rules
- Price texts are parsed to number and the currency symbol
Sometimes a service doesn't have an official feed. Sometimes the feed does not contain the data that you need, or it is less maintained than the public website. So the most complete and up to date data source may be the public web pages.
A number of online services have appeared to make scraping websites easier: Kimonolabs, import.io, Grepsr and so on. Their prices for "more than occasional scraping" are not provided publicly. Assume enterprise rates.
Then you want to use the scraped data. Online services offer XML feeds or Excel downloads. To get that data into a Zotonic database requires an additional step, with likely customization efforts to handle different sites.
The aim of this module is to help with that. Storing data into Zotonic pages can be done automatically, or you can choose to review and copy each data element.
This module comes with an example scraper. Have a look at your_site/admin/edit/bol_scraper and let it run.
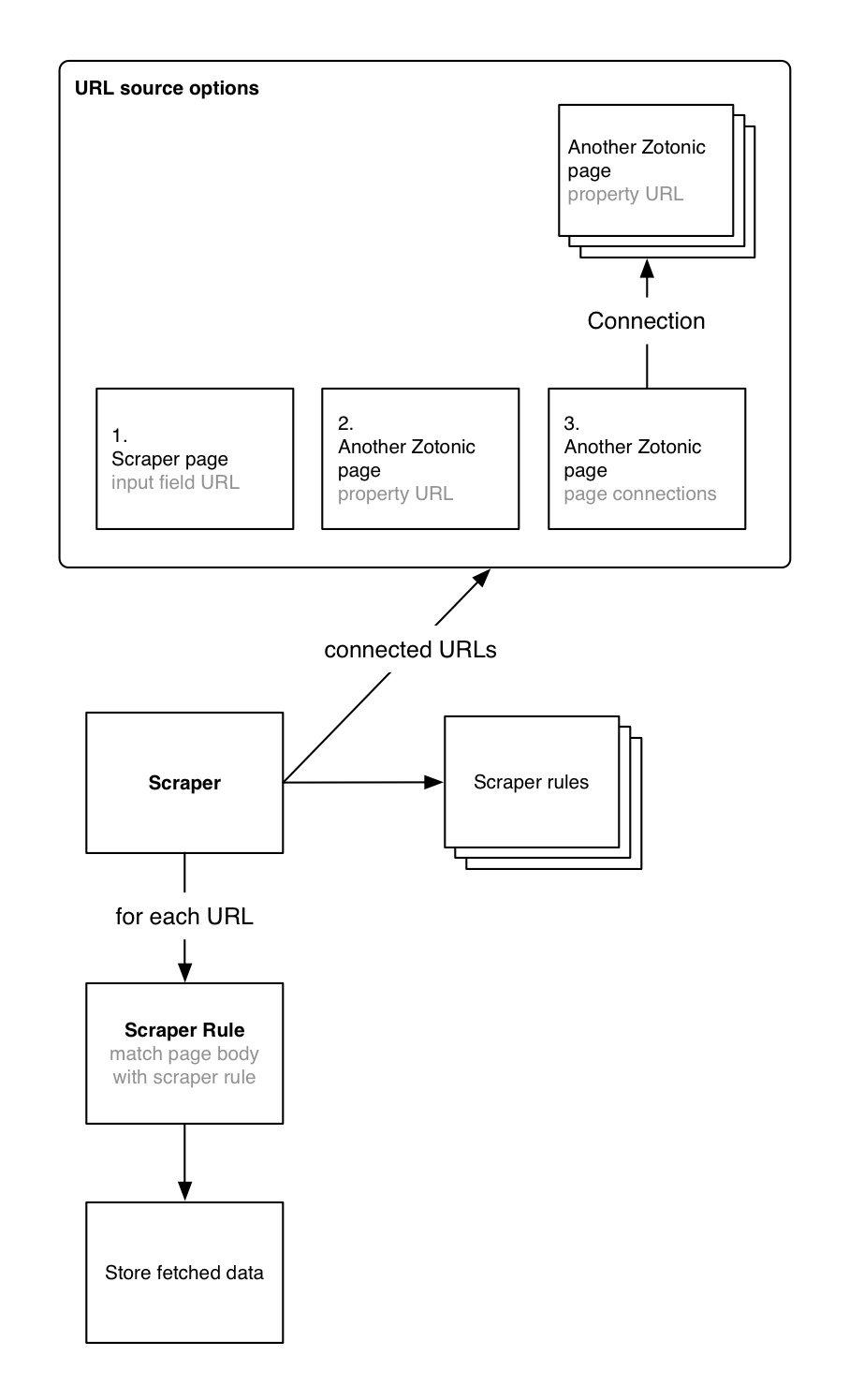
When you create a new scraper, the edit page will ask you where to get the URL/URLs from.The options for choosing the URL data source are:
This reveals an input field to enter a URL. Use this for a quick setup, but choose of the other options if you want to store the scraped data (not much use to store the data in the scraper page itself).
The URL will be read from another page, so that page must have a property 'url'. Use this for storing data from a single URL.
Adding this property to the page is done by adding a form field. How is described in the Zotonic documentation Creating a custom widget on the edit page. Make sure to use url for the name of the input field.
Use this to scrape multiple pages from a single website. Because the web pages will be predictable in layout, you can use the same scraping rules.
In this setup you have one "aggregator" page ("webshop") with connections to pages that have a property url ("product page") (see option 2).
The connection can either be outgoing or incoming.
If you have multiple pages without a uniform connection, you can provide a search query as data source. The result set will be filtered to only include pages with property url.
The example Search query contains:
cat='scraper_target'
The pages that provide the URLs are also called "connected pages". Any scraped data will be written to these pages - either as manual copy action (copy button) or automatically (with automatic rules).
Each data element to scrape (title, price) is described by a "scraper rule". Because each website is different in structure, there's a bit of an art to creating rules.
Luckily, many websites use structured data on the page - see "Leveraging rich snippets" below.
A scraper rule contains these fields, besides the title:
Instruction to read data from the page, see "XPath rule" below
How data should be processed. Supported types are:
- Text: for titles, summaries, product info, and so on
- Price: the price text will be parsed and written to extra fields:
price_text,price_currency,price_whole,price_fraction - Match: transform to
true/falsewhen a match is found - No match: transform to
true/falsewhen no match is found - Contains: transform to
true/falsewhen a specific text is found - URLs: handle links on the page for further processing
The field name (page property) of the connected page that should receive the scraped data. You can use Zotonic property fields such as "title" and "summary", or create your own property.
No property mapping is needed for type "price", because extra fields will be created automatically.
A website commonly contains aggregation pages (category and search results pages) that link to detail pages. From a data quality point of view it makes sense to scrape each detail page instead of the summaries.
Use data type URLs to follow each found URL with a chained scraper (see below).
A rule page with state "unpublished" will not be processed.
Google's rich snippets where introduced to produce better search results from web pages. For example to display the user rating:

Rich snippets are created by adding extra tags to the HTML source. These tags provide the necessary context for Google's crawlers.
The documentation says:
Google supports Rich Snippets for the following data types:
- Product -- Information about a product, including price, availability, and review ratings.
- Recipe -- Recipes that can be displayed in web searches and Recipe View.
- Review -- A review of an item such as a restaurant, movie, or store.
- Event -- An organized event, such as musical concerts or art festivals, that people may attend at a particular time and place.
- SoftwareApplication -- Information about a software app, including its URL, review ratings, and price.
Google's rich snippets can be recognized by the special HTML tag itemprop. If the website uses these tags, the quickest way to get data is to choose one of the pre-made "itemprop" rules.
There are 2 different types of "itemprop" rules. Which one should be used depends on the website. Often both types are used on the same page.
The itemprop tag is placed around visible text, such as:
<h1 itemprop="name">Game Of Thrones</h1>The itemprop data only visible when inspecting the page source:
<meta content="Warner Home Video" itemprop="name">When a site uses structured data on the page, you can be pretty sure that the structure of that data is relatively permanent. There will be no need to manually review the scraped data.
When a rule has the category automatic_scraper_rule, the scraped data will be automatically processed and written to the connected page. The pre-made "itemprop" rules are all processed like this.
And when you let the scrapers run automatically, scraping data is a completely automated job.
Set the interval for automatically running scrapers in Admin > Modules > Scraper, button "Configure".
When scraping data from less structured web pages, it is probably safer to manually review the results. Rules with the category scraper_rule will not be processed automatically.
Copying the data to the connected page is still relatively easy:
- Only changes are presented
- Just press the "Copy" button
Rule elements are described above. Most work will go into writing the correct XPath rule.
Most browsers have a way to grab the XPath of an element. I've had most success with Firefox plugin FirePath. Right-click on an element, choose "Inspect in FirePath".
On a Wikipedia page, when clicking on the page title, the found XPath rule is:
.//*[@id='firstHeading']
This finds the HTML element:
<h1 id="firstHeading" class="firstHeading" lang="es">Resident Evil 2</h1>But we don't want the entire HTML element, only the text contents. The easiest way to achieve that is to put string(...) around the XPath:
string(.//*[@id='firstHeading'])
Selecting an element with 1 class:
//div[@class="some-class"]
Selecting an element that has multiple classes (but we are interested in one only):
//div[contains(@class, "some-class")]
Selecting a nested element:
//div[contains(@class, "some-class")] and //div[contains(@class, "other-class")]
The data types "URLs", "Match" and "No match" let you define which scraper should be used to parse the found detail pages.
That is, a scraper rule can contain a reference to another scraper that will do the work. The found results will be listed at the original scraper.
You can optionally define a filter.
Currently the supported filter is "Select page with lowest price". All URLs will first be fetched, then compared on price, then the data from the page with the lowest price is kept.
To scrape a site with different types of pages, you can set up rules to assign a scraper per page type.
Take for example this setup where the top scraper only defines 2 rules:
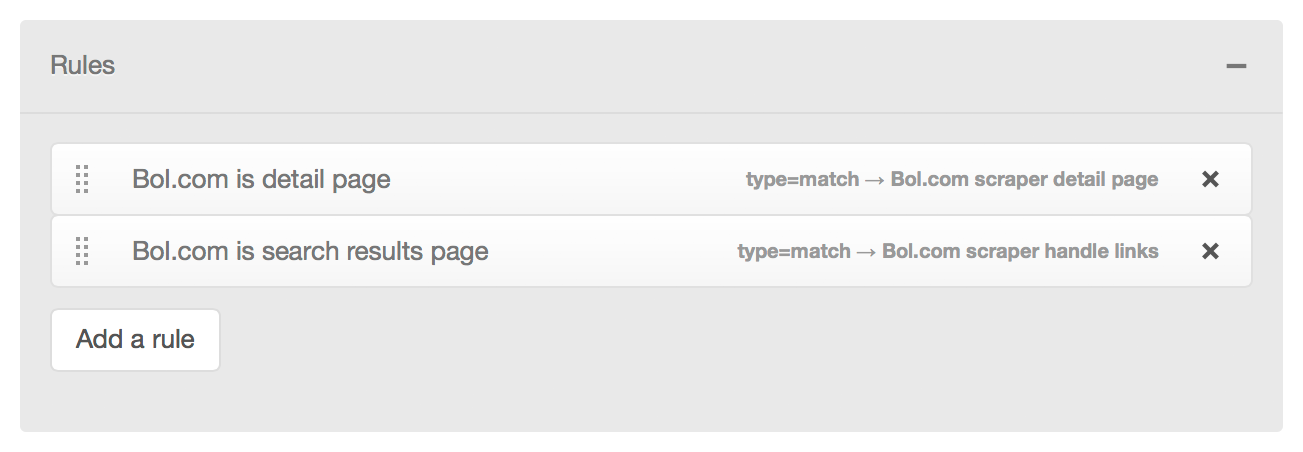
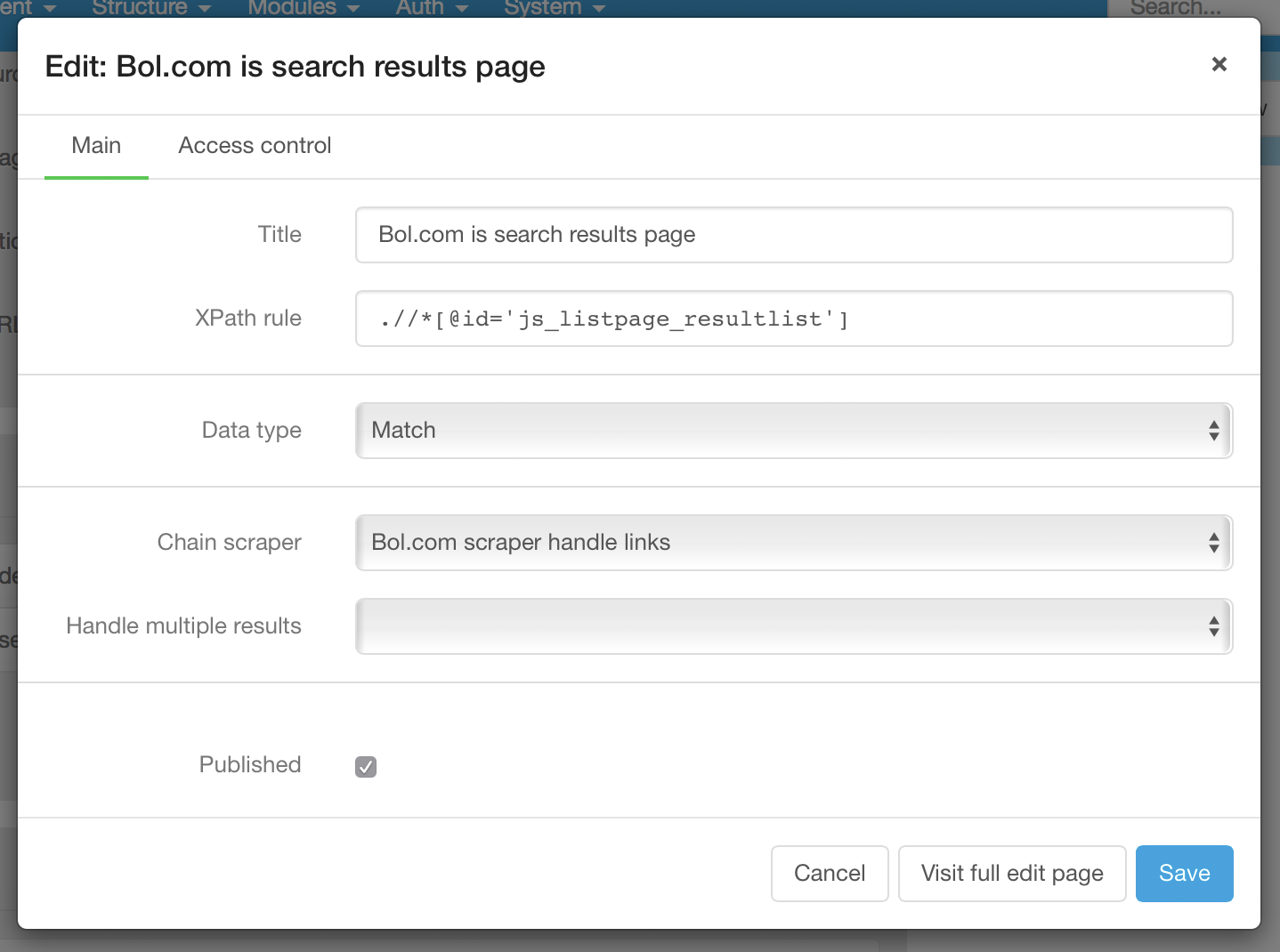
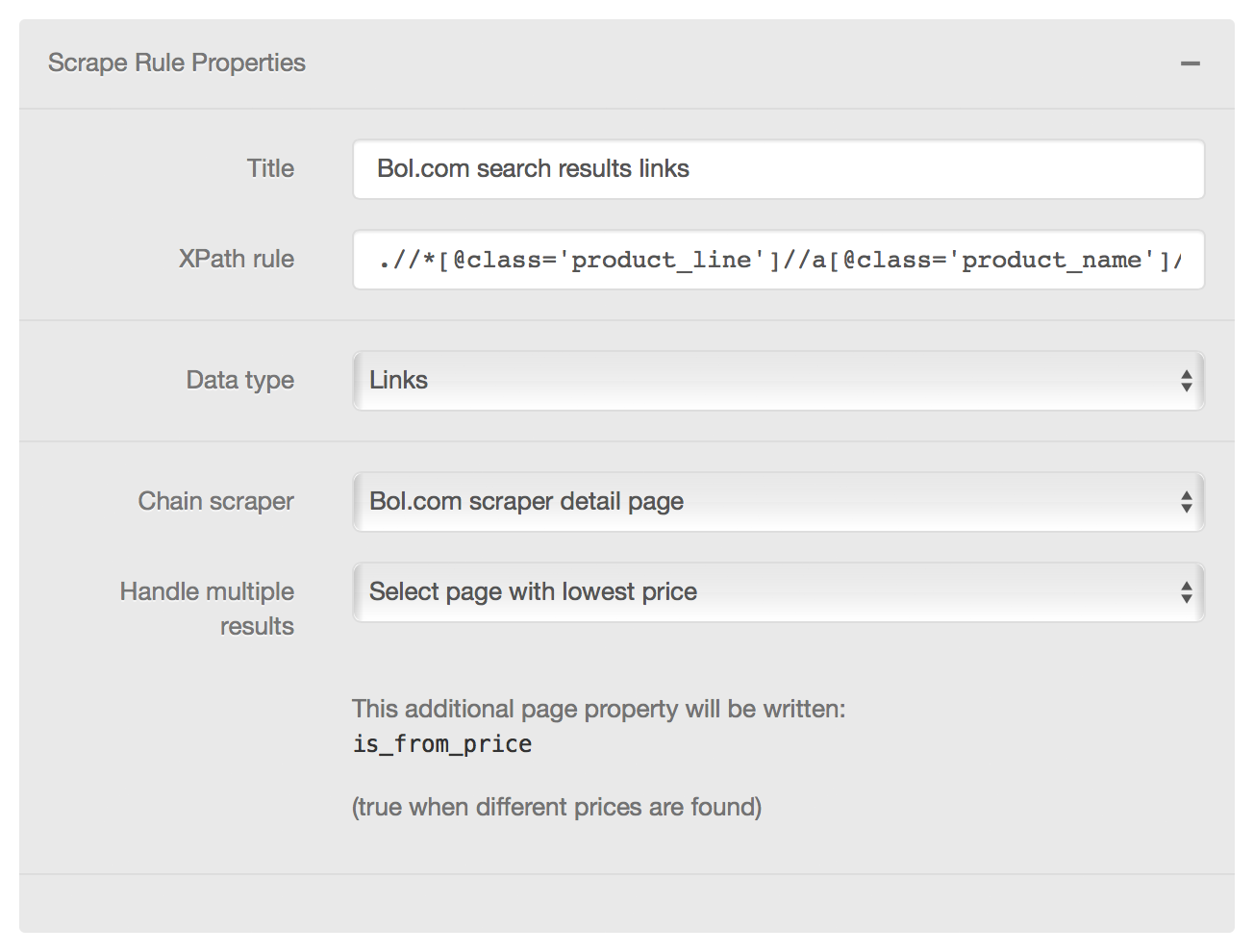
The search results rule is defined with data type "match". For each match, the chained scraper "handle links" is invoked:
The scraper only needs to deal with links on the page:
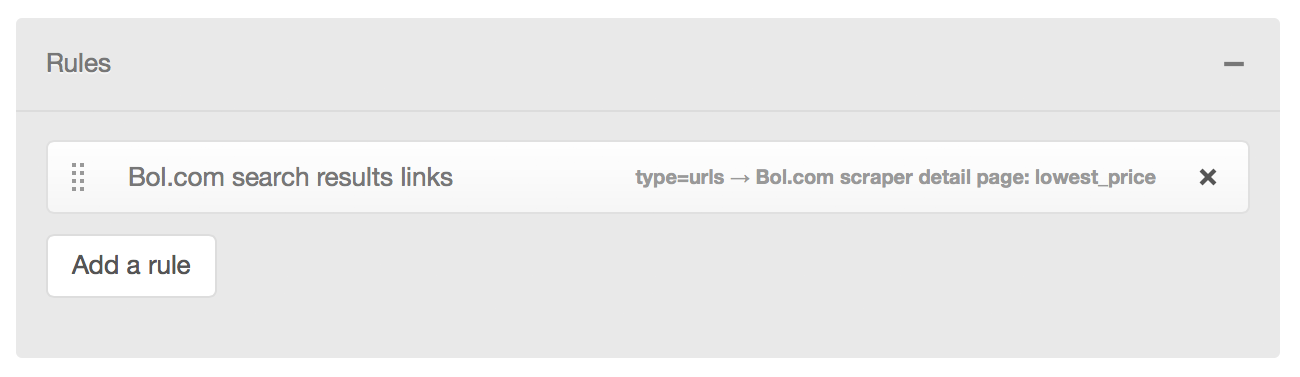
The scraper rule invokes the "detail page" scraper for each found link:
The processing flow then looks as follows:
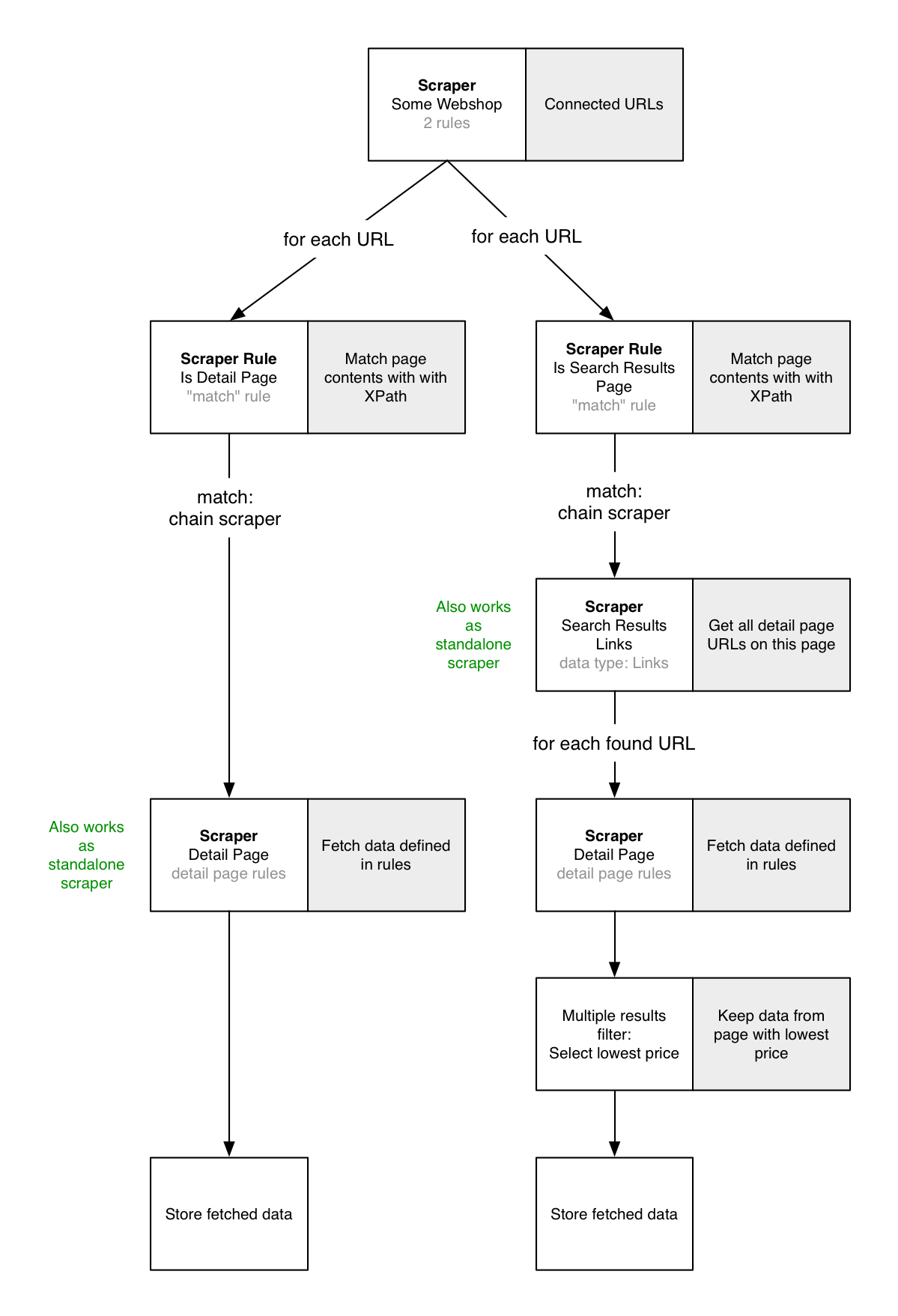
Note that the sub-scrapers "Detail Page" and "Search Results Links" each can have a data source themselves. The data source is useful for testing (and for running the scraper standalone); it will be ignored when the main scraper runs.
- To prevent clogging the network, there is an interval of 5 seconds for each URL. Scraping 10 urls will take about one minute.
- Unpublished rules are not processed.
- Unpublished scrapers are not run automatically (but can be run manually).
- Not all XPath functions are supported; check mochiweb_xpath_functions.erl for a list; using an unsupported function will likely result in a "parse error".
- Importing images
- Parsing dates
- Creating new Zotonic pages based on hits from overview pages (and support paging to other overview pages)
- More itemprop rules
- Determining the language of the page
- Erlang 17 or higher
- Zotonic 0.13.4 or newer, because the templates work with recent modifications to the admin interface.
Libraries that will be downloaded at installation (see below):
- Download and place this module in
your_zotonic_site/user/modules/ - Add 2 dependencies to
~/.zotonic/your_zotonic_version/zotonic.config:
{mochiweb_xpath, ".*", {git, "git@github.com:retnuh/mochiweb_xpath.git", {branch, "master"}}},
{parse_price, ".*", {git, "git@github.com:ArthurClemens/parse_price.git", {branch, "master"}}}- In the Zotonic folder, run
maketo install the dependencies - Activate this module in Admin > System > Modules
- Visit Admin > Modules > Scraper
- Set an interval for automatically running scrapers in Admin > Modules > Scraper, button "Configure"