{kind=link}
{kind=link}

- Python 3.8 (See requirements.txt's for libraries)
- MongoDB
- Postgres SQL
- Docker
- Twitter API
- Slack (Slackbot)
A basic ETL pipeline concept project which collects realtime tweets from the Twitter API mentioning or from six selected world leaders. Assigns a sentiment score to these tweets and posts the best scoring and worst scoring tweet per hour to a Slack channel via Slack Bot.
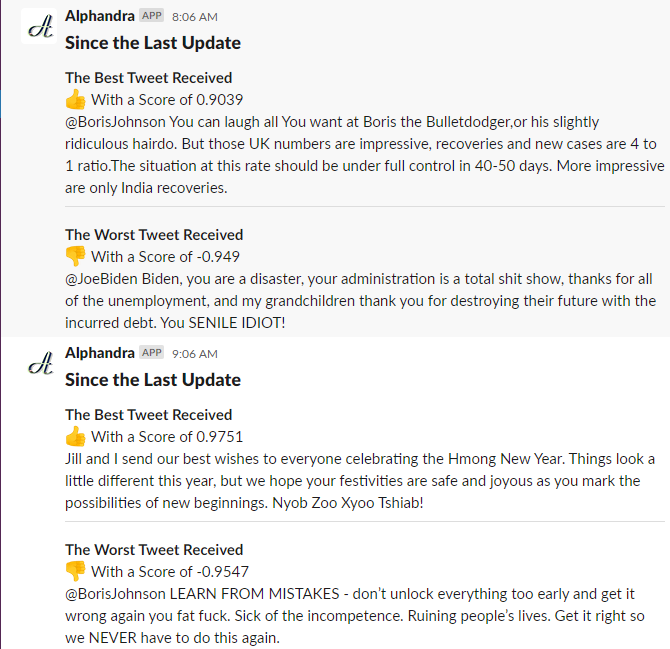
A sample output on Slack 1 hour apart. Note that the 3rd tweet is a tweet by Joe Biden, the rest of the tweets are by other users mentioning selected leaders
The pipeline consists of 5 components:
A python script that uses the Tweepy library to listen to Twitter API streams in real time. If one of the listened tweets mention one of the chosen world leaders it is caught pre-processed (we are only interested in the original tweet text and get the original from retweets) and stored in MongoDB
MongoDB is our Data Lake, where we dump the collected tweets through the Tweet Collector. ETL Job reads from MongoDB and Tweet Collector writes to it
The Postgres SQL is our Data Warehouse. Where we store sentiment analysed and timestamped tweets. ETL Job writes to Postgres and Slackbot reads from it
A python script that reads the tweets at MongoDB, performs a sentiment analysis on them, then writes them to Postgres SQL DB with a timestamp
A python script that reads the highest and lowest ranking tweet in the Postgres SQL DB placed in the DB every hour and posts them to the selected Slack channel
Each component runs in the local machine in its own docker container, these containers are handled by docker compose
- @AlphanAksoyoglu Alphan Aksoyoglu
- @ai-aksoyoglu Alexandra Irina Aksoyoglu
-
Since this is a concept project, only 100 tweets of interest (followed tweets) are processed per 5 minutes. Reading more tweets is possible with the free Twitter API credentials, but we chose to limit it at this rate.
-
The timing of the scripts are handled with sleep statements inside the scripts. There exists better technologies to handle communication between different components and orchestrating them (Kubernetes, Apache Kafka, Apache Airflow, Google Cloud Pub/Sub and many more...)
-
Proper logging and error handling should be implemented, at this stage error handling is minimally functional.