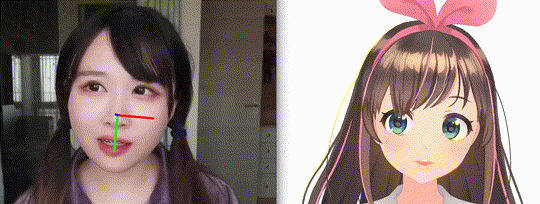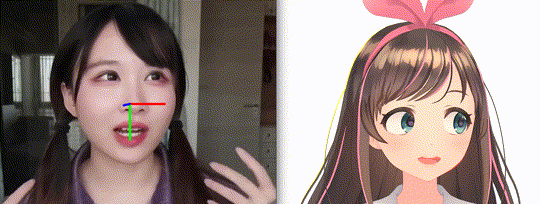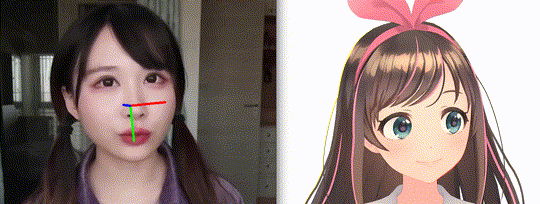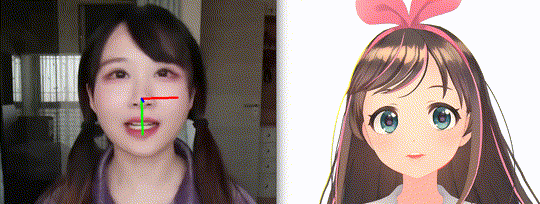

OpenVtuber: An application of real-time face and gaze analyzation via deep nerual networks.
- Lightweight network architecture for low computing capability devices.
- 3D gaze estimation based on the whole face semantic informations.
- The total framework is an upgradation of the [ECCV 2018] version.
- Drive MMD models through a single RGB camera.
- Python 3.6+
pip3 install -r requirements.txt- node.js and npm or yarn
cd NodeServer && yarn# install node modules
cd NodeServeryarn start- Open
http://127.0.0.1:6789/kizuna.html
python3 vtuber_link_start.py <your-video-path>
RetinaFace: Single-stage Dense Face Localisation in the Wild of CVPR 2020, is a practical single-stage SOTA face detector. It is highly recommended to read the official repo RetinaFace.
However, since the detection target of the face capture system is in the middle-close range, there is no need for complex pyramid scaling. We designed and published Faster RetinaFace to trade off between speed and accuracy, which can reach 500~1000 fps on normal laptops.
| Plan | Inference | Postprocess | Throughput Capacity (FPS) |
|---|---|---|---|
| 9750HQ+1660TI | 0.9ms | 1.5ms | 500~1000 |
| Jetson-Nano | 4.6ms | 11.4ms | 80~200 |
In this project, we apply the facial landmarks for calculating head pose and slicing the eye regions for gaze estimation. Moreover, the mouth and eys status can be inferenced via these key points.

The 2D pre-trained 106 landmarks model is provided by insightface repository, based on the coordinate regression face alignment algorithm. We refine this model into TFLite version with lower weights (4.7 MB), which can be found at here. For checking the effectiveness of landmark detection, run the following command at PythonClient sub directory:
python3 service/TFLiteFaceAlignment.py <your-video-path>The Perspective-n-Point (PnP) is the problem of determining the 3D position and orientation (pose) of a camera from observations of known point features. The PnP is typically formulated and solved linearly by employing lifting, or algebraically or directly.
Briefily, for head pose estimation, a set of pre-defined 3D facial landmarks and the corresponding 2D image projections need to be given. In this project, we employed the eyebrow, eye, nose, mouth and jaw landmarks in the AIFI Anthropometric Model as origin 3D feature points. The pre-defined vectors and mapping proctol can be found at here.

We adopt cv2.SolvePnP API for calculating the rotation vector and transform vector. Run the following command at PythonClient sub directory for real-time head pose estimation:
python3 service/SolvePnPHeadPoseEstimation.py <your-video-path>Estimating human gaze from a single RGB face image is a challenging task. Theoretically speaking, the gaze direction can be defined by pupil and eyeball center, however, the latter is unobservable in 2D images. Previous work of Swook, et al. presents a method to extract the semantic information of iris and eyeball into the intermediate representation, which so called gazemaps, and then decode the gazemaps into euler angle through regression network.
Inspired by this, we propose a 3D semantic information based gaze estimation method. Instead of employing gazemaps as the intermediate representation, we estimate the center of the eyeball directly from the average geometric information of human gaze.

Our eye region landmark detection and iris localization models are more robust than the original implementation, which leads to the higher accuracy in more complex situations. The demo of iris localization can be run as follows:
python3 service/TFLiteIrisLocalization.py <your-video-path>More details about 3D gaze estimation can be found at the Laser Eye repository.
- threejs.org: Applying Three.js WebGL Loader to render MMD models on web pages.
- kizunaai.com: モデルは無料でご利用いただけます.
@inproceedings{park2018deep,
title={Deep pictorial gaze estimation},
author={Park, Seonwook and Spurr, Adrian and Hilliges, Otmar},
booktitle={Proceedings of the European conference on computer vision (ECCV)},
pages={721--738},
year={2018}
}
@inproceedings{liu2018receptive,
title={Receptive field block net for accurate and fast object detection},
author={Liu, Songtao and Huang, Di and others},
booktitle={Proceedings of the European conference on computer vision (ECCV)},
pages={385--400},
year={2018}
}
@inproceedings{ke2017efficient,
title={An efficient algebraic solution to the perspective-three-point problem},
author={Ke, Tong and Roumeliotis, Stergios I},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={7225--7233},
year={2017}
}