![]()
A humble guide to give developers the tools they need to nail technical interviews!
❤️ PRs Welcome ❤️
- How to Prepare
- Resources
- Computer Science
- JavaScript + Web APIs
- Design Patterns
- HTML / CSS
- Questions
Invest time in preparing: It's important for any engineer, even senior ones, to brush up on their interview skills, coding skills and algorithms. An interview is typically different from your day-to-day job.
Practice answering many different coding questions: Practice answering a coding question with the most efficient bug-free solution without using a compiler. A few resources that offer coding questions to use for practice: Careercup, Topcoder, Project Euler, or Facebook Code Lab.
Go over data structures, algorithms and complexity: Be able to discuss the big-O complexity of your approaches. Don't forget to brush up on your data structures like lists, arrays, hash tables, hash maps, stacks, queues, graphs, trees, heaps. Also sorts, searches, and traversals (BFS, DFS).
Also review recursion and iterative approaches.
Think about your 2-5 years career aspirations: You will be asked to talk about your interest and your strengths as an engineer.
Prepare 1-2 questions to ask your interviewer: There is generally 5 minutes at the end of a typical interview for this.
- Cracking the Coding Interview
- Introduction to Algorithms
- Algorithms in C
- Data Structures and Algorithms and Big-O Cheat Sheet
- Coursera - Algorithms, Part 1
- Coursera - Algorithms, Part 2
- Udacity - Intro to Algorithms
- MIT Open courseware - Introduction to Algorithms
- “You Don’t Know JS” by Kyle Simpson - https://github.com/getify/You-Dont-Know-JS
- Cracking the javascript interview
- Data Structures and Algorithms Tutorial
- Cracking the Coding Interview (JS) Solutions
- Tech Interview Handbook
- Front End Interview Handbook
- Awesome JavaScript Interviews
- 500 Data Structures and Algorithms
- Top 10 Algos in Interview Questions
- HackerRank, Topcoder, Codeforces, Leetcode, InterviewBit or Kattis.
- Problems from Cracking the Coding Interview Book
- List of ACM-ICPC and Code Jam past questions
Data structures can implement one or more particular abstract data types (ADT), which specify the operations that can be performed on a data structure and the computational complexity of those operations. In comparison, a data structure is a concrete implementation of the specification provided by an ADT.
Different kinds of data structures are suited to different kinds of applications, and some are highly specialised to specific tasks. For example, relational databases commonly use B-tree indexes for data retrieval, while compiler implementations usually use hash tables to look up identifiers.
Data structures provide a means to manage large amounts of data efficiently for uses such as large databases and internet indexing services. Usually, efficient data structures are key to designing efficient algorithms. Some formal design methods and programming languages emphasise data structures, rather than algorithms, as the key organising factor in software design. Data structures can be used to organise the storage and retrieval of information stored in both main memory and secondary memory.
A linked list is a linear collection of data elements, in which linear order is not given by their physical placement in memory. Each pointing to the next node by means of a pointer. It is a data structure consisting of a group of nodes which together represent a sequence. Under the simplest form, each node is composed of data and a reference (in other words, a link) to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing efficient insertion or removal from arbitrary element references.
Linked lists are among the simplest and most common data structures. They can be used to implement several other common abstract data types, including lists (the abstract data type), stacks, queues, associative arrays, and S-expressions, though it is not uncommon to implement the other data structures directly without using a list as the basis of implementation.
A stack is an abstract data type that serves as a collection of elements, with two principal operations: push, which adds an element to the collection, and pop, which removes the most recently added element that was not yet removed. The order in which elements come off a stack gives rise to its alternative name, LIFO(for last in, first out). Additionally, a peek operation may give access to the top without modifying the stack.
The name "stack" for this type of structure comes from the analogy to a set of physical items stacked on top of each other, which makes it easy to take an item off the top of the stack, while getting to an item deeper in the stack may require taking off multiple other items first.[1]
Considered as a linear data structure, or more abstractly a sequential collection, the push and pop operations occur only at one end of the structure, referred to as the top of the stack. This makes it possible to implement a stack as a singly linked list and a pointer to the top element.
A stack may be implemented to have a bounded capacity. If the stack is full and does not contain enough space to accept an entity to be pushed, the stack is then considered to be in an overflow state. The pop operation removes an item from the top of the stack.
var stack = [];
stack.push(2); // stack is now [2]
stack.push(5); // stack is now [2, 5]
var i = stack.pop(); // stack is now [2]
alert(i); // displays 5A queue is a particular kind of abstract data type or collection in which the entities in the collection are kept in order and the principal (or only) operations on the collection are the addition of entities to the rear terminal position, known as enqueue, and removal of entities from the front terminal position, known as dequeue. This makes the queue a First-In-First-Out (FIFO) data structure. In a FIFO data structure, the first element added to the queue will be the first one to be removed. This is equivalent to the requirement that once a new element is added, all elements that were added before have to be removed before the new element can be removed. Often a peek or front operation is also entered, returning the value of the front element without dequeuing it. A queue is an example of a linear data structure, or more abstractly a sequential collection.
Queues provide services in computer science, transport, and operations research where various entities such as data, objects, persons, or events are stored and held to be processed later. In these contexts, the queue performs the function of a buffer.
Queues are common in computer programs, where they are implemented as data structures coupled with access routines, as an abstract data structure or in object-oriented languages as classes. Common implementations are circular buffers and linked lists.
var queue = [];
queue.push(2); // queue is now [2]
queue.push(5); // queue is now [2, 5]
var i = queue.shift(); // queue is now [5]
alert(i); // displays 2Priority Queue is similar to queue where we insert an element from the back and remove an element from front, but with a one difference that the logical order of elements in the priority queue depends on the priority of the elements. The element with highest priority will be moved to the front of the queue and one with lowest priority will move to the back of the queue. Thus it is possible that when you enqueue an element at the back in the queue, it can move to front because of its highest priority.
Let’s say we have an array of 5 elements : {4, 8, 1, 7, 3} and we have to insert all the elements in the max-priority queue.
- First as the priority queue is empty, so 4 will be inserted initially.
- Now when 8 will be inserted it will moved to front as 8 is greater than 4.
- While inserting 1, as it is the current minimum element in the priority queue, it will remain in the back of priority queue.
- Now 7 will be inserted between 8 and 4 as 7 is smaller than 8.
- Now 3 will be inserted before 1 as it is the 2nd minimum element in the priority queue.
Naive Approach: Suppose we have N elements and we have to insert these elements in the priority queue. We can use list and can insert elements in O(N) time and can sort them to maintain a priority queue in O(N logN ) time.
Efficient Approach: We can use heaps to implement the priority queue. It will take O(log N) time to insert and delete each element in the priority queue.
Based on heap structure, priority queue also has two types max-priority queue and min-priority queue.
Example Implementation:
class MaxHeap {
constructor() {
this._heap = [];
}
_getParent(index) {
return this._heap[(index - 1) / 2];
}
_getLeftChild(parentIndex) {
return this._heap[2 * parentIndex + 1];
}
_getRightChild(parentIndex) {
return this._heap[2 * parentIndex + 2];
}
_bubbleUp(index) {
const parentIndex = (index - 1) / 2;
if (parentIndex === 0) return;
if (this._getParent(index) < this._heap[index]) {
this._swap(parentIndex, index);
this._bubbleUp(parentIndex);
}
}
_sinkDown(index) {
const rightChildIndex = 2 * parentIndex + 2;
if (this._getRightChild(index) > this._heap.length) {
return;
}
if (this._getRightChild(index) > this._heap[index]) {
this._swap(index, rightChildIndex);
this._sinkDown(rightChildIndex);
}
}
_swap(indexOne, indexTwo) {
const temp = this._heap[indexOne];
this._heap[indexOne] = this._heap[indexTwo];
this._heap[indexTwo] = temp;
}
push(value) {
this._heap.push(value);
// Insert an element to the end of the heap
// If it's parent is smaller (max heap) or larger (min heap) It means we have
// a heap violation. We should swap the child (newly added value)
// with the parent until we restore the heap property
this._bubbleUp(this.heap.length);
}
pop() {
// Remove the first element in the heap. Swap the last element in the heap to the front.
// Sink down swapping with the right child until a position is found
const max = this._heap.shift();
this._swap(0, this._heap.length);
this._heap.pop();
this._sinkDown();
return max;
}
peek() {
this._heap[0];
}
}
class PriorityQueue {
// NOTE: Passing your heap implementation will
// allow you to switch from min to max heap with ease
constructor(heap) {
this._heap = heap;
}
enqueue(value) {
this._heap.push(value);
}
dequeue() {
this._heap.pop(value);
}
peek() {
this._heap.peek();
}
}
const priorityQueue = new PriorityQueue(new MaxHeap());A hash table (hash map) is a data structure which implements an associative array abstract data type, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
Ideally, the hash function will assign each key to a unique bucket, but most hash table designs employ an imperfect hash function, which might cause hash collisions where the hash function generates the same index for more than one key. Such collisions must be accommodated in some way.
In a well-dimensioned hash table, the average cost (number of instructions) for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key-value pairs, at constant average cost per operation.
In many situations, hash tables turn out to be more efficient than search trees or any other table lookup structure. For this reason, they are widely used in many kinds of computer software, particularly for associative arrays, database indexing, caches, and sets.
All a hash function does is turn a value into an array index. The hash function in turn is composed of two parts.
The first part, the hash code, takes a value and returns an integer. A function that always returned zero would be a hash coding function, but it would be a terrible one. More terrible ones include adding the ASCII values of a string together, multiplying the digits of a number, etc. A good hashing function minimizes the chance of a hash collision; a hash collision is when two distinct values have the same hash code. Good hashing functions, like SHA-256, have extremely small probabilities of hash collisions. I've heard that it's much more likely that a giant asteroid will impact the earth than a collision of SHA-256 ever happening in the wild. The second part of hash functions is the compression mapping. All this does is maps the integer to an array index using the modulus operator and the length of the underlying array.
A good hash function should be extremely fast to compute. Cryptographic-strength has functions often are relatively slow to compute, so faster ones are used that have higher collision rates. So how do we manage collisions?
A graph is an abstract data type that is meant to implement the undirected graph and directed graph concepts from mathematics, specifically the field of graph theory.
A graph data structure consists of a finite (and possibly mutable) set of vertices or nodes, together with a set of unordered pairs of these vertices for an undirected graph or a set of ordered pairs for a directed graph. These pairs are known as edges, arcs, or lines for an undirected graph and as arrows, directed edges, directed arcs, or directed lines for a directed graph. The vertices may be part of the graph structure, or may be external entities represented by integer indices or references.
A graph data structure may also associate to each edge some edge value, such as a symbolic label or a numeric attribute (cost, capacity, length, etc.).
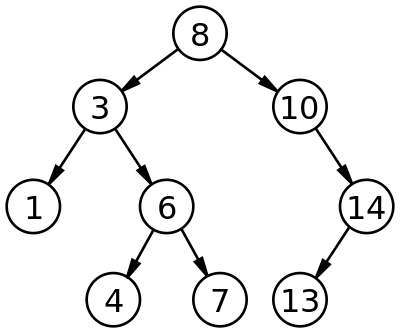
A tree is a widely used abstract data type (ADT)—or data structure implementing this ADT—that simulates a hierarchical tree structure, with a root value and subtrees of children with a parent node, represented as a set of linked nodes.
A tree data structure can be defined recursively (locally) as a collection of nodes (starting at a root node), where each node is a data structure consisting of a value, together with a list of references to nodes (the "children"), with the constraints that no reference is duplicated, and none points to the root.
Alternatively, a tree can be defined abstractly as a whole (globally) as an ordered tree, with a value assigned to each node. Both these perspectives are useful: while a tree can be analyzed mathematically as a whole, when actually represented as a data structure it is usually represented and worked with separately by node (rather than as a list of nodes and an adjacency list of edges between nodes, as one may represent a digraph, for instance). For example, looking at a tree as a whole, one can talk about "the parent node" of a given node, but in general as a data structure a given node only contains the list of its children, but does not contain a reference to its parent (if any)
Terminoligy
- Root: The top node in a tree.
- Child: A node directly connected to another node when moving away from the Root.
- Parent: The converse notion of a child.
- Siblings: A group of nodes with the same parent.
- Descendant: A node reachable by repeated proceeding from parent to child.
- Ancestor: A node reachable by repeated proceeding from child to parent.
- Leaf: A node with no children.
A binary tree is a tree data structure in which each node has at most two children, which are referred to as the left child and the right child. A recursive definition using just set theory notions is that a (non-empty) binary tree is a triple (L, S, R), where L and R are binary trees or the empty set and S is a singleton set. Some authors allow the binary tree to be the empty set as well.
From a graph theory perspective, binary (and K-ary) trees as defined here are actually arborescences. A binary tree may thus be also called a bifurcating arborescence—a term which appears in some very old programming books, before the modern computer science terminology prevailed. It is also possible to interpret a binary tree as an undirected, rather than a directed graph, in which case a binary tree is an ordered, rooted tree. Some authors use rooted binary tree instead of binary tree to emphasize the fact that the tree is rooted, but as defined above, a binary tree is always rooted. A binary tree is a special case of an ordered K-ary tree, where k is 2.
In computing, binary trees are seldom used solely for their structure. Much more typical is to define a labeling function on the nodes, which associates some value to each node. Binary trees labelled this way are used to implement binary search trees and binary heaps, and are used for efficient searching and sorting. The designation of non-root nodes as left or right child even when there is only one child present matters in some of these applications, in particular it is significant in binary search trees. In mathematics, what is termed binary tree can vary significantly from author to author. Some use the definition commonly used in computer science, but others define it as every non-leaf having exactly two children and don't necessarily order (as left/right) the children either.

Binary Search Trees (BST), are a particular type of data structure. They allow fast lookup, addition and removal of items, and can be used to implement either dynamic sets of items, or lookup tables that allow finding an item by its key (e.g., finding the phone number of a person by name).
Binary search trees keep their keys in sorted order, so that lookup and other operations can use the principle of binary search: when looking for a key in a tree (or a place to insert a new key), they traverse the tree from root to leaf, making comparisons to keys stored in the nodes of the tree and deciding, based on the comparison, to continue searching in the left or right subtrees. On average, this means that each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportional to the logarithm of the number of items stored in the tree. This is much better than the linear time required to find items by key in an (unsorted) array, but slower than the corresponding operations on hash tables.
Searching
Searching a binary search tree for a specific key can be programmed recursively or iteratively.
Begin by examining the root node. If the tree is null, the key we are searching for does not exist in the tree. Otherwise, if the key equals that of the root, the search is successful and we return the node. If the key is less than that of the root, we search the left subtree. Similarly, if the key is greater than that of the root, we search the right subtree. This process is repeated until the key is found or the remaining subtree is null. If the searched key is not found after a null subtree is reached, then the key is not present in the tree. This is easily expressed as a recursive algorithm (implemented in Python):
1 def search_recursively(key, node):
2 if node is None or node.key == key:
3 return node
4 if key < node.key:
5 return search_recursively(key, node.left)
6 # key > node.key
7 return search_recursively(key, node.right)The same algorithm can be implemented iteratively:
1 def search_iteratively(key, node):
2 current_node = node
3 while current_node is not None:
4 if key == current_node.key:
5 return current_node
6 elif key < current_node.key:
7 current_node = current_node.left
8 else: # key > current_node.key:
9 current_node = current_node.right
10 return NoneHeap is a special case of balanced binary tree data structure where the root-node key is compared with its children and arranged accordingly.
If α has child node β then − key(α) ≥ key(β)
As the value of parent is greater than that of child, this property generates Max Heap. Based on this criteria, a heap can be of two types −
Max-Heap − Where the value of the root node is greater than or equal to either of its children.

Min-Heap − Where the value of the root node is less than or equal to either of its children.

The heap is one maximally efficient implementation of an abstract data type called a priority queue, and in fact priority queues are often referred to as "heaps", regardless of how they may be implemented.
Heaps are also crucial in several efficient graph algorithms such as Dijkstra's algorithm. In a heap, the highest (or lowest) priority element is always stored at the root. A heap is not a sorted structure and can be regarded as partially ordered. As visible from the heap-diagram, there is no particular relationship among nodes on any given level, even among the siblings. When a heap is a complete binary tree, it has a smallest possible height—a heap with N nodes always has log N height.
A heap is a useful data structure when you need to remove the object with the highest (or lowest) priority.
A simple sorting algorithm that repeatedly steps through the list to be sorted, compares each pair of adjacent items and swaps them if they are in the wrong order (ie if 4 is next to 1, they will be swapped. The pass through the list is repeated until no swaps are needed, which indicates that the list is sorted. The algorithm, which is a comparison sort, is named for the way smaller or larger elements "bubble" to the top of the list. Although the algorithm is simple, it is too slow and impractical for most problems even when compared to insertion sort. It can be practical if the input is usually in sorted order but may occasionally have some out-of-order elements nearly in position.
Insertion sort is a simple sorting algorithm that builds the final sorted array (or list) one item at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:
- Simple implementation
- Efficient for (quite) small data sets, much like other quadratic sorting algorithms
- More efficient in practice than most other simple quadratic (i.e., O(n2)) algorithms such as selection sort or bubble sort
- Adaptive, i.e., efficient for data sets that are already substantially sorted: the time complexity is O(nk) when each element in the input is no more than k places away from its sorted position
- Stable; i.e., does not change the relative order of elements with equal keys
- In-place; i.e., only requires a constant amount O(1) of additional memory space
- Online; i.e., can sort a list as it receives it
When people manually sort cards in a bridge hand, most use a method that is similar to insertion sort.
merge sort (also commonly spelled mergesort) is an efficient, general-purpose, comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the implementation preserves the input order of equal elements in the sorted output. Mergesort is a divide and conquer algorithm.
An example of merge sort. First divide the list into the smallest unit (1 element), then compare each element with the adjacent list to sort and merge the two adjacent lists. Finally all the elements are sorted and merged.
Quicksort (sometimes called partition-exchange sort) is an efficient sorting algorithm, serving as a systematic method for placing the elements of an array in order.
Quicksort is a comparison sort, meaning that it can sort items of any type for which a "less-than" relation (formally, a total order) is defined. In efficient implementations it is not a stable sort, meaning that the relative order of equal sort items is not preserved. Quicksort can operate in-place on an array, requiring small additional amounts of memory to perform the sorting.
Mathematical analysis of quicksort shows that, on average, the algorithm takes O(n log n) comparisons to sort n items. In the worst case, it makes O(n2) comparisons, though this behavior is rare.
Quicksort first divides a large array into two smaller sub-arrays: the low elements and the high elements. Quicksort can then recursively sort the sub-arrays.
The steps are:
- Pick an element, called a pivot, from the array.
- Partitioning: reorder the array so that all elements with values less than the pivot come before the pivot, while all elements with values greater than the pivot come after it (equal values can go either way). After this partitioning, the pivot is in its final position. This is called the partition operation.
- Recursively apply the above steps to the sub-array of elements with smaller values and separately to the sub-array of elements with greater values.
The base case of the recursion is arrays of size zero or one, which never need to be sorted.
The pivot selection and partitioning steps can be done in several different ways; the choice of specific implementation schemes greatly affects the algorithm's performance.
In computer science, selection sort is a sorting algorithm, specifically an in-place comparison sort. It has O(n2) time complexity, making it inefficient on large lists, and generally performs worse than the similar insertion sort. Selection sort is noted for its simplicity, and it has performance advantages over more complicated algorithms in certain situations, particularly where auxiliary memory is limited.
The algorithm divides the input list into two parts: the sublist of items already sorted, which is built up from left to right at the front (left) of the list, and the sublist of items remaining to be sorted that occupy the rest of the list. Initially, the sorted sublist is empty and the unsorted sublist is the entire input list. The algorithm proceeds by finding the smallest (or largest, depending on sorting order) element in the unsorted sublist, exchanging (swapping) it with the leftmost unsorted element (putting it in sorted order), and moving the sublist boundaries one element to the right.
Binary search: Finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array; if they are unequal, the half in which the target cannot lie is eliminated and the search continues on the remaining half until it is successful. If the search ends with the remaining half being empty, the target is not in the array.
Graph traversal means visiting every vertex and edge exactly once in a well-defined order. While using certain graph algorithms, you must ensure that each vertex of the graph is visited exactly once. The order in which the vertices are visited are important and may depend upon the algorithm or question that you are solving.
During a traversal, it is important that you track which vertices have been visited. The most common way of tracking vertices is to mark them.
BFS is the most commonly used approach to traverse a graph.
BFS is a traversing algorithm where you should start traversing from a selected node (source or starting node) and traverse the graph layerwise thus exploring the neighbour nodes (nodes which are directly connected to source node). You must then move towards the next-level neighbour nodes.
As the name BFS suggests, you are required to traverse the graph breadthwise as follows:
- First move horizontally and visit all the nodes of the current layer
- Move to the next layer
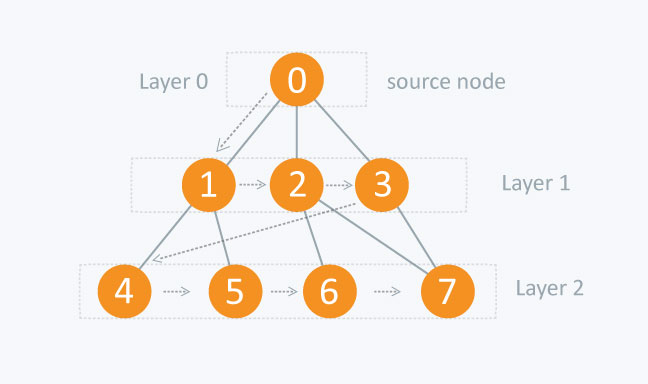
The distance between the nodes in layer 1 is comparitively lesser than the distance between the nodes in layer 2. Therefore, in BFS, you must traverse all the nodes in layer 1 before you move to the nodes in layer 2.
Traversing child nodes
A graph can contain cycles, which may bring you to the same node again while traversing the graph. To avoid processing of same node again, use a boolean array which marks the node after it is processed. While visiting the nodes in the layer of a graph, store them in a manner such that you can traverse the corresponding child nodes in a similar order.
In the earlier diagram, start traversing from 0 and visit its child nodes 1, 2, and 3. Store them in the order in which they are visited. This will allow you to visit the child nodes of 1 first (i.e. 4 and 5), then of 2 (i.e. 6 and 7), and then of 3 (i.e. 7) etc.
To make this process easy, use a queue to store the node and mark it as 'visited' until all its neighbours (vertices that are directly connected to it) are marked. The queue follows the First In First Out (FIFO) queuing method, and therefore, the neigbors of the node will be visited in the order in which they were inserted in the node i.e. the node that was inserted first will be visited first, and so on.
BFS (G, s) //Where G is the graph and s is the source node
let Q be queue.
Q.enqueue( s ) //Inserting s in queue until all its neighbour vertices are marked.
mark s as visited.
while ( Q is not empty)
//Removing that vertex from queue,whose neighbour will be visited now
v = Q.dequeue( )
//processing all the neighbours of v
for all neighbours w of v in Graph G
if w is not visited
Q.enqueue( w ) //Stores w in Q to further visit its neighbour
mark w as visited.
The DFS algorithm is a recursive algorithm that uses the idea of backtracking. It involves exhaustive searches of all the nodes by going ahead, if possible, else by backtracking.
Here, the word backtrack means that when you are moving forward and there are no more nodes along the current path, you move backwards on the same path to find nodes to traverse. All the nodes will be visited on the current path till all the unvisited nodes have been traversed after which the next path will be selected.
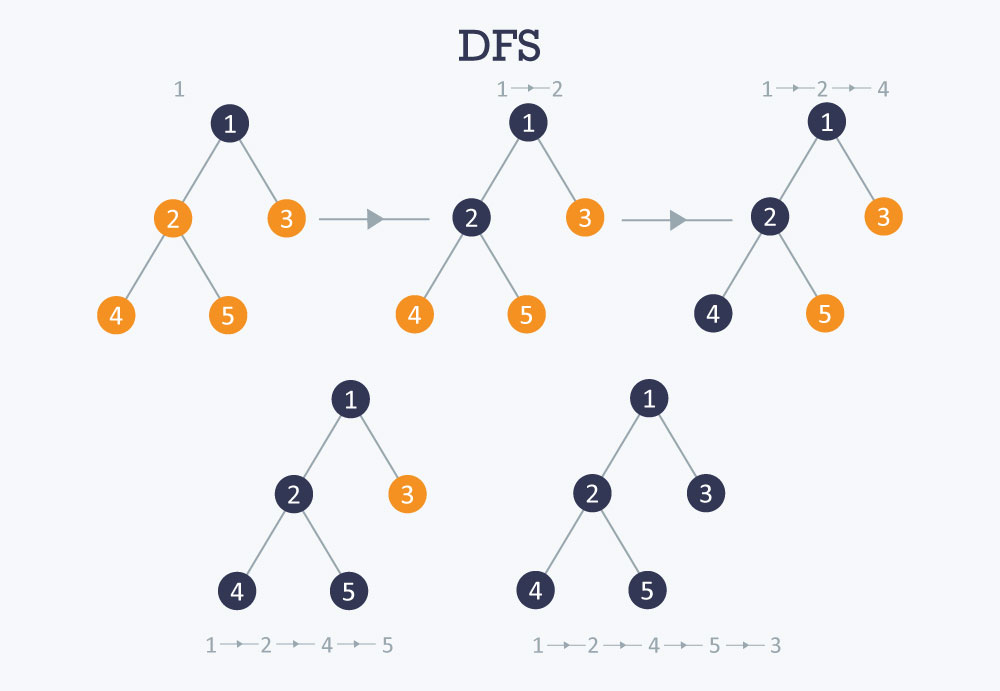
This recursive nature of DFS can be implemented using stacks. The basic idea is as follows:
- Pick a starting node and push all its adjacent nodes into a stack.
- Pop a node from stack to select the next node to visit and push all its adjacent nodes into a stack.
- Repeat this process until the stack is empty. However, ensure that the nodes that are visited are marked. This will prevent you from visiting the same node more than once. If you do not mark the nodes that are visited and you visit the same node more than once, you may end up in an infinite loop.
// iterative
DFS-iterative (G, s): //Where G is graph and s is source vertex
let S be stack
S.push( s ) //Inserting s in stack
mark s as visited.
while ( S is not empty):
//Pop a vertex from stack to visit next
v = S.top( )
S.pop( )
//Push all the neighbours of v in stack that are not visited
for all neighbours w of v in Graph G:
if w is not visited :
S.push( w )
mark w as visited
// recursive
DFS-recursive(G, s):
mark s as visited
for all neighbours w of s in Graph G:
if w is not visited:
DFS-recursive(G, w)
https://en.wikipedia.org/wiki/Big_O_notation

Big O notation is the language we use for articulating how long an algorithm takes to run. It's how we compare the efficiency of different approaches to a problem.
With big O notation we express the runtime in terms of how quickly it grows relative to the input, as the input gets arbitrarily large.
- how quickly the runtime grows—Some external factors affect the time it takes for a function to run: the speed of the processor, what else the computer is running, etc. So it's hard to make strong statements about the exact runtime of an algorithm. Instead we use big O notation to express how quickly its runtime grows.
- relative to the input—Since we're not looking at an exact number, we need to phrase our runtime growth in terms of something. We use the size of the input. So we can say things like the runtime grows "on the order of the size of the input" (O(n)O(n)) or "on the order of the square of the size of the input" (O(n^2)O(n2)).
- as the input gets arbitrarily large—Our algorithm may have steps that seem expensive when nn is small but are eclipsed eventually by other steps as nn gets huge. For big O analysis, we care most about the stuff that grows fastest as the input grows, because everything else is quickly eclipsed as nn gets very large. If you know what an asymptote is, you might see why "big O analysis" is sometimes called "asymptotic analysis."
Note: Often this "worst case" stipulation is implied.

This function runs in O(1) time (or "constant time") relative to its input. The input arraycould be 1 item or 1,000 items, but this function would still just require one "step."
function printFirstItem(arrayOfItems) {
console.log(arrayOfItems[0]);
}This function runs in O(n) time (or "linear time"), where n is the number of items in the array. If the array has 10 items, we have to print 10 times. If it has 1,000 items, we have to print 1,000 times.
function printAllItems(arrayOfItems) {
arrayOfItems.forEach(function (item) {
console.log(item);
});
}Here we're nesting two loops. If our array has n items, our outer loop runs n times and our inner loop runs n times for each iteration of the outer loop, giving us n^2 total prints. Thus this function runs in O(n^2) time (or "quadratic time"). If the array has 10 items, we have to print 100 times. If it has 1,000 items, we have to print 1,000,000 times.
function printAllPossibleOrderedPairs(arrayOfItems) {
arrayOfItems.forEach(function (firstItem) {
arrayOfItems.forEach(function (secondItem) {
console.log(firstItem, secondItem);
});
});
}When you're calculating the big O complexity of something, you just throw out the constants. So the below is O(2n), which we just call O(n).
function printAllItemsTwice(theArray) {
theArray.forEach(function (item) {
// O(n)
console.log(item);
});
// once more, with feeling
theArray.forEach(function (item) {
// O(n)
console.log(item);
});
// O(n) + O(n) = O(n^2)
// = O(n)
}A common example of a logarithms is the Binary search:
Binary search is a technique used to search sorted data sets. It works by selecting the middle element of the data set, and compares it against a target value. If the values match it will return success. If the target value is higher than the value of the probe element it will take the upper half of the data set and perform the same operation against it. Likewise, if the target value is lower than the value of the probe element it will perform the operation against the lower half. It will continue to halve the data set with each iteration until the value has been found or until it can no longer split the data set.
This type of algorithm is described as O(log N). The iterative halving of data sets described in the binary search example produces a growth curve that peaks at the beginning and slowly flattens out as the size of the data sets increase e.g. an input data set containing 10 items takes one second to complete, a data set containing 100 items takes two seconds, and a data set containing 1000 items will take three seconds. Doubling the size of the input data set has little effect on its growth as after a single iteration of the algorithm the data set will be halved and therefore on a par with an input data set half the size. This makes algorithms like binary search extremely efficient when dealing with large data sets.
https://www.sitepoint.com/5-typical-javascript-interview-exercises/
When it comes to inheritance, JavaScript only has one construct: objects. Each object has a private property (referred to as [[Prototype]] ) which holds a link to another object called its prototype. That prototype object has a prototype of its own, and so on until an object is reached with null as its prototype. By definition, null has no prototype, and acts as the final link in this prototype chain.
Nearly all objects in JavaScript are instances of Object which sits on the top of a prototype chain.
While this is often considered to be one of JavaScript's weaknesses, the prototypal inheritance model is in fact more powerful than the classic model. It is, for example, fairly trivial to build a classic model on top of a prototypal model.
Class Inheritance: A class is like a blueprint — a description of the object to be created. Classes inherit from classes and create subclass relationships: hierarchical class taxonomies.
Instances are typically instantiated via constructor functions with the *new*keyword. Class inheritance may or may not use the class keyword from ES6. Classes as you may know them from languages like Java don’t technically exist in JavaScript. Constructor functions are used, instead. The ES6 class keyword desugars to a constructor function:
class Foo {}
typeof Foo // 'function'
In JavaScript, class inheritance is implemented on top of prototypal inheritance, but that does not mean that it does the same thing:
JavaScript’s class inheritance uses the prototype chain to wire the child Constructor.prototype to the parent Constructor.prototype for delegation. Usually, the super() constructor is also called. Those steps form single-ancestor parent/child hierarchies and create the tightest coupling available in OO design.
Prototypal Inheritance: A prototype is a working object instance. Objects inherit directly from other objects.
Instances may be composed from many different source objects, allowing for easy selective inheritance and a flat [[Prototype]] delegation hierarchy. In other words, class taxonomies are not an automatic side-effect of prototypal OO: a critical distinction.
Instances are typically instantiated via factory functions, object literals, or Object.create().
JavaScript has lexical scoping with function scope. In other words, even though JavaScript looks like it should have block scope because it uses curly braces { }, a new scope is created only when you create a new function.
Lexical scoping (sometimes known as static scoping ) is a convention used with many programming languages that sets the scope (range of functionality) of a variable so that it may only be called (referenced) from within the block of code in which it is defined.
var outerFunction = function () {
if (true) {
var x = 5;
//console.log(y); //line 1, ReferenceError: y not defined
}
var nestedFunction = function () {
if (true) {
var y = 7;
console.log(x); //line 2, x will still be known prints 5
}
if (true) {
console.log(y); //line 3, prints 7
}
};
return nestedFunction;
};
var myFunction = outerFunction();
myFunction();In this example, the variable x is available everywhere inside of outerFunction(). Also, the variable y is available everywhere within the nestedFunction(), but neither are available outside of the function where they were defined. The reason for this can be explained by lexical scoping. The scope of variables is defined by their position in source code. In order to resolve variables, JavaScript starts at the innermost scope and searches outwards until it finds the variable it was looking for. Lexical scoping is nice, because we can easily figure out what the value of a variable will be by looking at the code; whereas in dynamic scoping, the meaning of a variable can change at runtime, making it more difficult.
A closure is a special kind of object that combines two things: a function, and the environment in which that function was created. The environment consists of any local variables that were in-scope at the time that the closure was created.
A closure is an inner function that has access to the outer (enclosing) function’s variables—scope chain.
The closure has three scope chains: it has access to its own scope (variables defined between its curly brackets), it has access to the outer function’s variables, and it has access to the global variables.
The inner function has access not only to the outer function’s variables, but also to the outer function’s parameters. Note that the inner function cannot call the outer function’s arguments object, however, even though it can call the outer function’s parameters directly.
A closure is created by adding a function inside another function.
A closure is the combination of a function and the lexical environment within which that function was declared.
function init() {
var name = "Mozilla"; // name is a local variable created by init
function displayName() {
// displayName() is the inner function, a closure
alert(name); // use variable declared in the parent function
}
displayName();
}
init();https://www.sitepoint.com/event-bubbling-javascript/
Event bubbling relates to the order in which event handlers are called when one element is nested inside a second element, and both elements have registered a listener for the same event (a click, for example). But event bubbling is only one piece of the puzzle. It is often mentioned in conjunction with event capturing and event propagation.
What is the Event Propagation?
Let’s start with event propagation. This is the blanket term for both event bubbling and event capturing. A click on an image does not only generate a click event for the corresponding IMG element, but also for the parent A, for the grandfather LI and so on, going all the way up through all the element’s ancestors, before terminating at the window object.
In DOM terminology, the image is the event target, the innermost element over which the click originated. The event target, plus its ancestors, from its parent up through to the window object, form a branch in the DOM tree. For example, in the image gallery, this branch will be composed of the nodes: IMG, A, LI, UL, BODY, HTML, document, window.
This branch is important because it is the path along which the events propagate (or flow). This propagation is the process of calling all the listeners for the given event type, attached to the nodes on the branch. Each listener will be called with an event object that gathers information relevant to the event.
Remember that several listeners can be registered on a node for the same event type. When the propagation reaches one such node, listeners are invoked in the order of their registration.
The propagation is bidirectional, from the window to the event target and back. This propagation can be divided into three phases:
- From the window to the event target parent: this is the capture phase
- The event target itself: this is the target phase
- From the event target parent back to the window: the bubble phase
The Event Capture Phase
In this phase only the capturer listeners are called, namely, those listeners that were registered using a value of true for the third parameter of addEventListener:
el.addEventListener('click', listener, true)
If this parameter is omitted, its default value is false and the listener is not a capturer.
So, during this phase, only the capturers found on the path from the window to the event target parent are called.
The Event Target Phase
In this phase all the listeners registered on the event target will be invoked, regardless of the value of their capture flag.
The Event Bubbling Phase
During the event bubbling phase only the non-capturers will be called. That is, only the listeners registered with a value of false for the third parameter of addEventListener():
el.addEventListener('click', listener, false) // listener doesn't capture
el.addEventListener('click', listener) // listener doesn't captureNote that while all events flow down to the event target with the capture phase, focus, blur, load and some others, don’t bubble up. That is, their travel stops after the target phase.

stopPropagationstops the event from bubbling up the event chain.preventDefaultprevents the default action the browser makes on that event.
With stopPropagation only the buttons click handler is called and the divs click handler never fires.
Where as if you just preventDefault only the browsers default action is stopped but the div's click handler still fires.
Use .bind() when you want that function to later be called with a certain context, useful in events.
Use .call() or .apply() when you want to invoke the function immediately, and modify the context.
call &apply call the function immediately, whereas bind returns a function that, when later executed, will have the correct context set for calling the original function. This way you can maintain context in async callbacks and events.
Example:
function MyObject(element) {
this.elm = element;
element.addEventListener("click", this.onClick.bind(this), false);
}
MyObject.prototype.onClick = function (e) {
var t = this; //do something with [t]...
//without bind the context of this function wouldn't be a MyObject
//instance as you would normally expect.
};A simple, naive implementation of bind would be like:
Function.prototype.bind = function (ctx) {
var fn = this;
return function () {
fn.apply(ctx, arguments);
};
};Bind()
The bind() method creates a new function that, when called, has its this keyword set to the provided value, with a given sequence of arguments preceding any provided when the new function is called.
Apply()
The apply() method calls a function with a given this value, and arguments provided as an array (or an array-like object).
Call()
The call() method calls a function with a given this value and arguments provided individually.
Call vs. Apply
The difference is that apply lets you invoke the function with arguments as an array; callrequires the parameters be listed explicitly. A useful mnemonic is *"*A** for array and C for **c**omma."
Pseudo syntax:
theFunction.apply(valueForThis, arrayOfArgs)
theFunction.call(valueForThis, arg1, arg2, ...)
Sample code:
function theFunction(name, profession) {
console.log("My name is " + name + " and I am a " + profession + ".");
}
theFunction("John", "fireman");
theFunction.apply(undefined, ["Susan", "school teacher"]);
theFunction.call(undefined, "Claude", "mathematician");
theFunction.call(undefined, ...["Matthew", "physicist"]); // used with the spread operator
// Output:
// My name is John and I am a fireman.
// My name is Susan and I am a school teacher.
// My name is Claude and I am a mathematician.
// My name is Matthew and I am a physicist.Variable and function hoisting
Hoisting is a JavaScript mechanism where variables and function declarations are moved to the top of their scope before code execution.
Function declarations and variable declarations are always moved (“hoisted”) invisibly to the top of their containing scope by the JavaScript interpreter. Function parameters and language-defined names are, obviously, already there. This means that code like this:
function foo() {
bar();
var x = 1;
}is actually interpreted like this:
function foo() {
var x;
bar();
x = 1;
}Currying is a way of constructing functions that allows partial application of a function’s arguments. What this means is that you can pass all of the arguments a function is expecting and get the result, or pass a subset of those arguments and get a function back that’s waiting for the rest of the arguments.
var greetCurried = function (greeting) {
return function (name) {
console.log(greeting + ", " + name);
};
};The only problem is the syntax. As you build these curried functions up, you need to keep nesting returned functions, and call them with new functions that require multiple sets of parentheses, each containing its own isolated argument. It can get messy.
To address that problem, one approach is to create a quick and dirty currying function that will take the name of an existing function that was written without all the nested returns. A currying function would need to pull out the list of arguments for that function, and use those to return a curried version of the original function:
var curryIt = function (uncurried) {
var parameters = Array.prototype.slice.call(arguments, 1);
return function () {
return uncurried.apply(
this,
parameters.concat(Array.prototype.slice.call(arguments, 0))
);
};
};To use this, we pass it the name of a function that takes any number of arguments, along with as many of the arguments as we want to pre-populate. What we get back is a function that’s waiting for the remaining arguments:
var greeter = function (greeting, separator, emphasis, name) {
console.log(greeting + separator + name + emphasis);
};
var greetHello = curryIt(greeter, "Hello", ", ", ".");
greetHello("Heidi"); //"Hello, Heidi."
greetHello("Eddie"); //"Hello, Eddie."Practical Applications
function converter(toUnit, factor, offset, input) {
offset = offset || 0;
return [((offset + input) * factor).toFixed(2), toUnit].join(" ");
}
var milesToKm = converter.curry("km", 1.60936, undefined);
var poundsToKg = converter.curry("kg", 0.4546, undefined);
var farenheitToCelsius = converter.curry("degrees C", 0.5556, -32);
milesToKm(10); // returns "16.09 km"
poundsToKg(2.5); // returns "1.14 kg"
farenheitToCelsius(98); // returns "36.67 degrees C"This relies on a curry extension of Function, although as you can see it only uses apply (nothing too fancy):
Function.prototype.curry = function () {
if (arguments.length < 1) {
return this; //nothing to curry with - return function
}
var __method = this;
var args = toArray(arguments);
return function () {
return __method.apply(this, args.concat([].slice.apply(null, arguments)));
};
};Var
The most important thing to know about the var keyword is that it is function scoped. Scope refers to how a computer keeps track of all the variables in a program, specifically the environment in which each variable is accessible. Typically we talk about scope as either being global and therefore available everywhere or local and reserved for a specific block of code.
When using var our local scope is within a function. This means that a variable with the same name can be used in two separate functions as each has their own local scope. In fact, we can use the same variable three times if we also include it in the global scope.
The function-based nature of var also leads to JavaScript behavior such as hoisting, where variable and function declarations are “hoisted” to the top of the scope before assignments.
Hoisting
Hoisting is a behavior in JavaScript where variable and function declarations are “hoisted” to the top of their scope before code execution. This can result in confusing behaviour, such as the ability to call variables and functions before you wrote them.
Let
The let statement declares a local variable in a block scope. It is similar to var, in that we can optionally initialise the variable.
The main difference between let and var is that variable declared with let is block scoped and variables declared with var is function scoped.
Const
The const declaration creates a read-only reference to a value. It does not mean the value it holds is immutable, just that the variable identifier cannot be reassigned. For instance, in the case where the content is an object, this means the object's contents (e.g., its parameters) can be altered.
Constants are block-scoped, much like variables defined using the let statement. The value of a constant cannot change through re-assignment, and it can't be redeclared.
Temporal Dead Zone:
let bindings are created at the top of the (block) scope containing the declaration, commonly referred to as "hoisting". Unlike variables declared with var, which will start with the value undefined, let variables are not initialized until their definition is evaluated. Accessing the variable before the initialization results in a ReferenceError. The variable is in a "temporal dead zone" from the start of the block until the initialization is processed.
function do_something() {
console.log(bar); // undefined
console.log(foo); // ReferenceError
var bar = 1;
let foo = 2;
}An arrow function expression has a shorter syntax than a function expression and does not have its own this, arguments, super, or new.target. These function expressions are best suited for non-method functions, and they cannot be used as constructors.
There is one subtle difference in behavior between ordinary functionfunctions and arrow functions. Arrow functions do not have their own this value. The value of this inside an arrow function is always inherited from the enclosing scope. In contrast function functions receive a this value automatically, whether they want one or not.
Generators are functions which can be exited and later re-entered. Their context (variable bindings) will be saved across re-entrances.
Generator functions are a feature introduced in ES6 that allows a function to generate many values over time by returning an object which can be iterated over… an iterable with a
.next()method that returns objects
Generators in JavaScript -- especially when combined with Promises -- are a very powerful tool for asynchronous programming as they mitigate -- if not entirely eliminate -- the problems with callbacks, such as Callback Hell and Inversion of Control.
This pattern is what async functions are built on top of...
Calling a generator function does not execute its body immediately; an iterator object for the function is returned instead. When the iterator's next() method is called, the generator function's body is executed until the first yield expression, which specifies the value to be returned from the iterator or, with yield*, delegates to another generator function. The next() method returns an object with a value property containing the yielded value and a done property which indicates whether the generator has yielded its last value as a boolean. Calling the next() method with an argument will resume the generator function execution, replacing the yield expression where execution was paused with the argument from next().
A return statement in a generator, when executed, will make the generator finished (i.e the done property of the object returned by it will be set to true). If a value is returned, it will be set as the value property of the object returned by the generator. Much like a return statement, an error thrown inside the generator will make the generator finished -- unless caught within the generator's body. When a generator is finished, subsequent next calls will not execute any of that generator's code, they will just return an object of this form: {value: undefined, done: true}.
Example: Return statement in a generator
function* yieldAndReturn() {
yield "Y";
return "R";
yield "unreachable";
}
var gen = yieldAndReturn();
console.log(gen.next()); // { value: "Y", done: false }
console.log(gen.next()); // { value: "R", done: true }
console.log(gen.next()); // { value: undefined, done: true }The Map object holds key-value pairs. Any value (both objects and primitive values) may be used as either a key or a value. A Map object can iterate its elements in insertion order - a for..of loop will return an array of [key, value] for each iteration.
Objects are similar to Maps in that both let you set keys to values, retrieve those values, delete keys, and detect whether something is stored at a key. Because of this, Objects have been used as Maps historically; however, there are important differences between Objects and Maps that make using a Map better.
An Object has a prototype, so there are default keys in the map. However, this can be bypassed using map = Object.create(null). The keys of an Object are Strings, where they can be any value for a Map. You can get the size of a Map easily while you have to manually keep track of size for an Object.
Use maps over objects when keys are unknown until run time, and when all keys are the same type and all values are the same type.
Use objects when there is logic that operates on individual elements.
Virtual DOM is any kind of representation of a real DOM
When we change something in our Virtual DOM Tree, we get a new Virtual Tree. An algorithm then compares these two trees (old and new), finds differences and makes only necessary small changes to real DOM so it reflects it's virtual counterpart. So instead of updating the DOM when your application state changes, you simply create a virtual tree, which looks like the DOM state that you want. Virtual DOM will then figure out how to make the DOM look like this efficiently without recreating all of the DOM nodes.
Virtual DOM allows you to update a view whenever state changes by creating a full virtual tree of the view and then patching the DOM efficiently to look exactly as you described it. This results in keeping manual DOM manipulation and previous state tracking out of your application code, promoting clean and maintainable rendering logic for web applications.
Why Virtual DOM?
DOM manipulation is the heart of the modern, interactive web. Unfortunately, it is also a lot slower than most JavaScript operations. This slowness is made worse by the fact that most JavaScript frameworks update the DOM much more than they have to.
For example: let's say that you have a list that contains ten items. You check off the first item. Most JavaScript frameworks would rebuild the entire list. That's ten times more work than necessary! Only one item changed, but the remaining nine get rebuilt exactly how they were before.
Rebuilding a list is no big deal to a web browser, but modern websites can use huge amounts of DOM manipulation. Inefficient updating has become a serious problem.
Manipulating the DOM is slow. Manipulating the virtual DOM is much faster, because nothing gets drawn onscreen. Think of manipulating the virtual DOM as editing a blueprint, as opposed to moving rooms in an actual house.
How it helps
In React, when you render a JSX element, every single virtual DOM object gets updated. This sounds incredibly inefficient, but the cost is insignificant because the virtual DOM can update so quickly.
Once the virtual DOM has updated, then React compares the virtual DOM with a virtual DOM snapshot that was taken right before the update.
By comparing the new virtual DOM with a pre-update version, React figures out exactly which virtual DOM objects have changed. This process is called "diffing."
Once React knows which virtual DOM objects have changed, then React updates those objects, and only those objects, on the real DOM. In our example from earlier, React would be smart enough to rebuild your one checked-off list-item, and leave the rest of your list alone.
This makes a big difference! React can update only the necessary parts of the DOM. React's reputation for performance comes largely from this innovation.
In summary, here's what happens when you try to update the DOM in React:
- The entire virtual DOM gets updated.
- The virtual DOM gets compared to what it looked like before you updated it. React figures out which objects have changed.
- The changed objects, and the changed objects only, get updated on the real DOM.
- Changes on the real DOM cause the screen to change.
Shadow DOM is used to encapsulate a DOM subtree from the rest of the page. Useful if you are making plug and play widgets. This encapsulation means your document stylesheet can’t accidentally apply to encapsulated subtree. Your JavaScript can’t accidentally modify parts inside shadow Dom; your IDs wont overlap and so on.
Following code will change the buttons text to Japanese. But interestingly host.innerText will still give us Hello, world! because the DOM subtree under the shadow root is encapsulated. HTML5 input type range , Video , Audio etc all uses shadow DOM.
<button>Hello, world!</button>
<script>
var host = document.querySelector("button");
var root = host.createShadowRoot();
root.textContent = "こんにちは、影の世界!";
</script>The await operator is used to wait for a Promise. It can only be used inside an async function.
The await expression causes async function execution to pause until a Promise is resolved, that is fulfilled or rejected, and to resume execution of the async function after fulfillment. When resumed, the value of the await expression is that of the fulfilled Promise.
If the Promise is rejected, the await expression throws the rejected value.
If the value of the expression following the await operator is not a Promise, it's converted to a resolved Promise.
Example:
If a Promise is passed to an await expression, it waits for the Promise to be fulfilled and returns the fulfilled value.
function resolveAfter2Seconds(x) {
return new Promise((resolve) => {
setTimeout(() => {
resolve(x);
}, 2000);
});
}
async function f1() {
var x = await resolveAfter2Seconds(10);
console.log(x); // 10
}
f1();If the value is not a Promise, it converts the value to a resolved Promise, and waits for it.
async function f2() {
var y = await 20;
console.log(y); // 20
}
f2();If the Promise is rejected, the rejected value is thrown.
async function f3() {
try {
var z = await Promise.reject(30);
} catch (e) {
console.log(e); // 30
}
}
f3();Web Workers is a simple means for web content to run scripts in background threads. The worker thread can perform tasks without interfering with the user interface. Once created, a worker can send messages to the JavaScript code that created it by posting messages to an event handler specified by that code (and vice versa).
A worker is an object created using a constructor (e.g. Worker()) that runs a named JavaScript file — this file contains the code that will run in the worker thread; workers run in another global context that is different from the current window.
Data is sent between workers and the main thread via a system of messages — both sides send their messages using the postMessage() method, and respond to messages via the onmessage event handler (the message is contained within the Message event's data attribute.) The data is copied rather than shared.
Workers may, in turn, spawn new workers, as long as those workers are hosted within the same origin as the parent page.
Dedicated workers
Dedicated workers can be created like this:
var myWorker = new Worker("worker.js");Once created, you can send messages to and from the worker via postMessage() and listen on the on message event handler.
When you want to send a message to the worker, you post messages to it like this (in the context of main.js):
first.onchange = function () {
myWorker.postMessage([first.value, second.value]);
console.log("Message posted to worker");
};
second.onchange = function () {
myWorker.postMessage([first.value, second.value]);
console.log("Message posted to worker");
};So here we have two <input/> elements represented by the variables first and second; when the value of either is changed, myWorker.postMessage([first.value,second.value]) is used to send the value inside to the worker, as an array. You can send pretty much anything you like in the message.
In the worker, we can respond when the message is received by writing an event handler block like this (in the context of worker.js):
onmessage = function (e) {
console.log("Message received from main script");
var workerResult = "Result: " + e.data[0] * e.data[1];
console.log("Posting message back to main script");
postMessage(workerResult);
};The onmessage handler allows us to run some code whenever a message is received, with the message itself being available in the message event's data attribute. Here we simply multiply together the two numbers then use postMessage() again, to post the result back to the main thread.
Back in the main thread, we use onmessage again, to respond to the message sent back from the worker:
myWorker.onmessage = function (e) {
result.textContent = e.data;
console.log("Message received from worker");
};Here we grab the message event data and set it as the textContent of the result paragraph, so the user can see the result of the calculation.
Notice that onmessage and postMessage() need to be hung off the Workerobject when used in the main script thread, but not when used in the worker. This is because, inside the worker, the worker is effectively the global scope.
Note: When a message is passed between the main thread and worker, it is copied, not shared.
If you need to immediately terminate a running worker from the main thread, you can do so by calling the worker's terminate method:
myWorker.terminate();The worker thread is killed immediately without an opportunity to complete its operations or clean up after itself.
In the worker thread, workers may close themselves by calling their own close method:
close();Example:
example.html: (the main page):
var myWorker = new Worker("my_task.js");
myWorker.onmessage = function (oEvent) {
console.log("Worker said : " + oEvent.data);
};
myWorker.postMessage("ali");my_task.js (the worker):
postMessage("I'm working before postMessage('ali').");
onmessage = function (oEvent) {
postMessage("Hi " + oEvent.data);
};For more information, see: MDN - Using Web Workers
ServiceWorkers essentially act as proxy servers that sit between web applications, and the browser and network (when available). They are intended to (amongst other things) enable the creation of effective offline experiences, intercepting network requests and taking appropriate action based on whether the network is available and updated assets reside on the server. They will also allow access to push notifications and background sync APIs.
A service worker is run in a worker context: it therefore has no DOM access, and runs on a different thread to the main JavaScript that powers your app, so it is not blocking. It is designed to be fully async. Service workers only run over HTTPS, for security reasons. Having modified network requests, wide open to man in the middle attacks would be really bad.
- Throttle: the original function be called at most once per specified period.
- Debounce: the original function be called after the caller stops calling the decorated function after a specified period.
Throttle implementation:
function throttled(delay, fn) {
let lastCall = 0;
return function (...args) {
const now = new Date().getTime();
if (now - lastCall < delay) return;
lastCall = now;
return fn(...args);
};
}Debounce implementation:
function debounce(fn, interval) {
let timeoutToken;
return function (...args) {
clearTimeout(timeoutToken);
timeoutToken = setTimeout(() => {
timeoutToken = null;
fn.apply(this, args);
}, interval);
};
}When you hit an web url in browser, first the HTML content is downloaded and browser starts parsing the HTML. During HTML parsing if it encounters a script block, HTML parsing halts. It makes a call to fetch the script (if external ) and then executes the script, before resuming HTML parsing.
If we use async, HTML parsing doesn’t stop whilst file is fetched, but once it’s fetched, HTML parsing stops to execute the script.
If we use defer browser downloads the JS during HTML parsing, and executes the JS only when HTML parsing is done.
Javascript uses a pass by value strategy for primitives but uses pass by reference for objects including arrays (AKA call by sharing).
Pass by reference is when variables passed in to functions are given the direct memory address. This allows the function to manipulate the object or primitive as it exists outside the scope of the function.
Pass by value means that when you pass that variable into a function its the equivalent of creating a new var and making a copy of the passed in var. They’re not necessarily the same exact variable in the same exact memory address but rather copies. Modifying the copy does not affect the original.
Stack methods
Array.prototype.pop() Removes the last element from an array and returns that element.
Array.prototype.push() Adds one or more elements to the end of an array and returns the new length of the array.
Queue Methods
Array.prototype.unshift() Adds one or more elements to the front of an array and returns the new length of the array.
Array.prototype.pop() Removes the last element from an array and returns that element.
Misc
Array.prototype.reverse() Reverses the order of the elements of an array in place — the first becomes the last, and the last becomes the first.
Array.prototype.splice() Adds and/or removes elements from an array.
Array.prototype.slice() Extracts a section of an array and returns a new array.
Memoization is an optimisation technique used primarily to speed up computer programs by storing the results of expensive function calls and returning the cached result when the same inputs occur again.
A memoized function "remembers" the results corresponding to some set of specific inputs. Subsequent calls with remembered inputs return the remembered result rather than recalculating it, thus eliminating the primary cost of a call with given parameters from all but the first call made to the function with those parameters. The set of remembered associations may be a fixed-size set controlled by a replacement algorithm or a fixed set, depending on the nature of the function and its use. A function can only be memoized if it is referentially transparent; that is, only if calling the function has exactly the same effect as replacing that function call with its return value.
Memoization is a way to lower a function's time cost in exchange for space cost; that is, memoized functions become optimised for speed in exchange for a higher use of computer memory space. The time/space "cost" of algorithms has a specific name in computing: computational complexity. All functions have a computational complexity in time (i.e. they take time to execute) and in space.
https://www.scaler.com/topics/design-patterns/decorator-design-pattern/
Decorators are a structural design pattern that aim to promote code re-use. Similar to Mixins, they can be considered another viable alternative to object sub-classing.
Classically, Decorators offered the ability to add behaviour to existing classes in a system dynamically. The idea was that the decoration itself wasn't essential to the base functionality of the class, otherwise it would be baked into the superclass itself.
They can be used to modify existing systems where we wish to add additional features to objects without the need to heavily modify the underlying code using them. A common reason why developers use them is their applications may contain features requiring a large quantity of distinct types of object. Imagine having to define hundreds of different object constructors for say, a JavaScript game.
The Decorator pattern isn't heavily tied to how objects are created but instead focuses on the problem of extending their functionality. Rather than just relying on prototypal inheritance, we work with a single base object and progressively add decorator objects which provide the additional capabilities. The idea is that rather than sub-classing, we add (decorate) properties or methods to a base object so it's a little more streamlined.
// The constructor to decorate
function MacBook() {
this.cost = function () {
return 997;
};
this.screenSize = function () {
return 11.6;
};
}
// Decorator 1
function memory(macbook) {
var v = macbook.cost();
macbook.cost = function () {
return v + 75;
};
}
// Decorator 2
function engraving(macbook) {
var v = macbook.cost();
macbook.cost = function () {
return v + 200;
};
}
// Decorator 3
function insurance(macbook) {
var v = macbook.cost();
macbook.cost = function () {
return v + 250;
};
}
var mb = new MacBook();
memory(mb);
engraving(mb);
insurance(mb);
console.log(mb.cost()); // Outputs: 1522
console.log(mb.screenSize()); // Outputs: 11.6The Factory pattern is another creational pattern concerned with the notion of creating objects. Where it differs from the other patterns in its category is that it doesn't explicitly require us to use a constructor. Instead, a Factory can provide a generic interface for creating objects, where we can specify the type of factory object we wish to be created.
Imagine that we have a UI factory where we are asked to create a type of UI component. Rather than creating this component directly using the new operator or via another creational constructor, we ask a Factory object for a new component instead. We inform the Factory what type of object is required (e.g "Button", "Panel") and it instantiates this, returning it to us for use.
When To Use The Factory Pattern
The Factory pattern can be especially useful when applied to the following situations:
- When our object or component setup involves a high level of complexity
- When we need to easily generate different instances of objects depending on the environment we are in
- When we're working with many small objects or components that share the same properties
- When composing objects with instances of other objects that need only satisfy an API contract (aka, duck typing) to work. This is useful for decoupling.
When Not To Use The Factory Pattern
When applied to the wrong type of problem, this pattern can introduce an unnecessarily great deal of complexity to an application. Unless providing an interface for object creation is a design goal for the library or framework we are writing, I would suggest sticking to explicit constructors to avoid the unnecessary overhead.
Due to the fact that the process of object creation is effectively abstracted behind an interface, this can also introduce problems with unit testing depending on just how complex this process might be.
The Singleton pattern is thus known because it restricts instantiation of a class to a single object. Classically, the Singleton pattern can be implemented by creating a class with a method that creates a new instance of the class if one doesn't exist. In the event of an instance already existing, it simply returns a reference to that object.
Singletons differ from static classes (or objects) as we can delay their initialization, generally because they require some information that may not be available during initialization time. They don't provide a way for code that is unaware of a previous reference to them to easily retrieve them. This is because it is neither the object or "class" that's returned by a Singleton, it's a structure. Think of how closured variables aren't actually closures - the function scope that provides the closure is the closure.
In JavaScript, Singletons serve as a shared resource namespace which isolate implementation code from the global namespace so as to provide a single point of access for functions.
Pros:
- Better memory usage
- Low latency
- Needs initialisation once
Cons:
- They are generally used as a global instance, why is that so bad? Because you hide the dependencies of your application in your code, instead of exposing them through the interfaces. Making something global to avoid passing it around is a code smell.
- They violate the single responsibility principle: by virtue of the fact that they control their own creation and lifecycle.
- They inherently cause code to be tightly coupled. This makes faking them out under test rather difficult in many cases.
- They carry state around for the lifetime of the application. Another hit to testing since you can end up with a situation where tests need to be ordered which is a big no no for unit tests. Why? Because each unit test should be independent from the other.
Example:
export default class Singleton {
static instance;
constructor(){
if(instance) return instance;
this.state = "duke";
this.instance = this;
}
}
Now:
let first = new Singleton();
let second = new Singleton();
console.log(first===second); //output: trueThe Module pattern was originally defined as a way to provide both private and public encapsulation for classes in conventional software engineering.
In JavaScript, the Module pattern is used to further emulate the concept of classes in such a way that we're able to include both public/private methods and variables inside a single object, thus shielding particular parts from the global scope. What this results in is a reduction in the likelihood of our function names conflicting with other functions defined in additional scripts on the page.
Privacy
The Module pattern encapsulates "privacy", state and organization using closures. It provides a way of wrapping a mix of public and private methods and variables, protecting pieces from leaking into the global scope and accidentally colliding with another developer's interface. With this pattern, only a public API is returned, keeping everything else within the closure private.
This gives us a clean solution for shielding logic doing the heavy lifting whilst only exposing an interface we wish other parts of our application to use. The pattern utilizes an immediately-invoked function expression (IIFE - see the section on namespacing patterns for more on this) where an object is returned.
It should be noted that there isn't really an explicitly true sense of "privacy" inside JavaScript because unlike some traditional languages, it doesn't have access modifiers. Variables can't technically be declared as being public nor private and so we use function scope to simulate this concept. Within the Module pattern, variables or methods declared are only available inside the module itself thanks to closure. Variables or methods defined within the returning object however are available to everyone.
When we put up a facade, we present an outward appearance to the world which may conceal a very different reality. This was the inspiration for the name behind the Facade pattern. This pattern provides a convenient higher-level interface to a larger body of code, hiding its true underlying complexity. Think of it as simplifying the API being presented to other developers, something which almost always improves usability.
Facades are a structural pattern which can often be seen in JavaScript libraries like jQuery where, although an implementation may support methods with a wide range of behaviors, only a "facade" or limited abstraction of these methods is presented to the public for use.
This allows us to interact with the Facade directly rather than the subsystem behind the scenes. Whenever we use jQuery's $(el).css() or $(el).animate() methods, we're actually using a Facade - the simpler public interface that avoids us having to manually call the many internal methods in jQuery core required to get some behavior working. This also avoids the need to manually interact with DOM APIs and maintain state variables.
The jQuery core methods should be considered intermediate abstractions. The more immediate burden to developers is the DOM API and facades are what make the jQuery library so easy to use.
To build on what we've learned, the Facade pattern both simplifies the interface of a class and it also decouples the class from the code that utilizes it. This gives us the ability to indirectly interact with subsystems in a way that can sometimes be less prone to error than accessing the subsystem directly. A Facade's advantages include ease of use and often a small size-footprint in implementing the pattern.
The Observer is a design pattern where an object (known as a subject) maintains a list of objects depending on it (observers), automatically notifying them of any changes to state.
When a subject needs to notify observers about something interesting happening, it broadcasts a notification to the observers (which can include specific data related to the topic of the notification).
When we no longer wish for a particular observer to be notified of changes by the subject they are registered with, the subject can remove them from the list of observers.
It's often useful to refer back to published definitions of design patterns that are language agnostic to get a broader sense of their usage and advantages over time. The definition of the Observer pattern provided in the GoF book, Design Patterns: Elements of Reusable Object-Oriented Software, is:
One or more observers are interested in the state of a subject and register their interest with the subject by attaching themselves. When something changes in our subject that the observer may be interested in, a notify message is sent which calls the update method in each observer. When the observer is no longer interested in the subject's state, they can simply detach themselves.
Strategy - defines a family of algorithms, encapsulates each, and makes them interchangeable. Strategy lets the algorithm vary independently form clients that use it.
This pattern seems to be very similar to Factory, Command and others. The main difference is that it is one to many pattern (one object can have many strategies). Also this pattern is used to define algorithms. It may be used for:
- Using optimal sorting algorithm for different types of data
- Using different algorithms to count product discount based on user type
- Using different algorithms to convert an image/file to different format
When to use it When you have a part of your Class that's subject to change frequently or perhaps you have many related subclasses which only differ in behavior it's often a good time to consider using a Strategy pattern.
Another benefit of the Strategy pattern is that it can hide complex logic or data that the client doesn't need to know about.
Example:
class Greeter {
constructor(strategy) {
this.strategy = strategy;
}
greet() {
return this.strategy();
}
}
// Since a function encapsulates an algorithm, it makes a perfect
// candidate for a Strategy.
var politeGreetingStrategy = function () {
console.log("Hello.");
};
var friendlyGreetingStrategy = function () {
console.log("Hey!");
};
var boredGreetingStrategy = function () {
console.log("sup.");
};
// Let's use these strategies!
var politeGreeter = new Greeter(politeGreetingStrategy);
var friendlyGreeter = new Greeter(friendlyGreetingStrategy);
var boredGreeter = new Greeter(boredGreetingStrategy);
politeGreeter.greet(); //=> Hello.
friendlyGreeter.greet(); //=> Hey!
boredGreeter.greet(); //=> sup.IoC and DIP are high level design principles which should be used while designing application classes. These are principles, so they only recommend certain best practices but do not provide any specific implementation details. Dependency Injection (DI) is a pattern and IoC container is a framework.

IoC is a design principle which recommends inversion of different kinds of controls in object oriented design to achieve loose coupling between the application classes. Here, the control means any additional responsibilities a class has other than its main responsibility, such as control over the flow of an application, control over the dependent object creation and binding (Remember SRP-Single Responsibility Principle). If you want to do TDD (Test Driven Development) then you must use IoC principle without which TDD is not possible.
DIP principle also helps in achieving loose coupling between the classes. It is highly recommended to use DIP and IoC together in order to achieve loose coupling.
DIP suggests that high-level modules should not depend on low level modules. Both should depend on abstraction.
Dependency Injection (DI) is a design pattern used to implement IoC where it allows creation of dependent objects outside of a class and provides those objects to a class through different ways. Using DI, we move the creation and binding of the dependent objects outside of the class that depends on it.
Dependency Injection pattern involves 3 types of classes.
- Client Class: The client class (dependent class) is a class which depends on the service class
- Service Class: The service class (dependency) is a class that provides service to the client class.
- Injector Class: The injector class injects service class object into the client class.
Types of Dependency Injection:
- Constructor Injection: In the constructor injection, injector supplies service (dependency) through the client class constructor.
- Property Injection: In property injection (aka Setter Injection), injector supplies dependency through a public property of the client class.
- Method Injection: In this type of injection, client class implements an interface which declares method(s) to supply dependency and the injector uses this interface to supply dependency to the client class.
Dependency injection is effective in these situations:
- You need to inject configuration data into one or more components.
- You need to inject the same dependency into multiple components.
- You need to inject different implementations of the same dependency.
- You need to inject the same implementation in different configurations.
- You need some of the services provided by the container.
Dependency injection is not effective if:
- You will never need a different implementation.
- You will never need a different configuration.
If you know you will never change the implementation or configuration of some dependency, there is no benefit in using dependency injection.
IoC Container (a.k.a. DI Container) is a framework for implementing automatic dependency injection. It manages object creating and its life time and also injects dependencies to the class.
IoC container creates an object of the specified class and also injects all the dependency objects through constructor, property or method at run time and disposes it at the appropriate time. This is done so that we don't have to create and manage objects manually.
All the containers must provide easy support for the following DI lifecycle.
- Register: The container must know which dependency to instantiate when it encounters a particular type. This process is called registration. Basically, it must include some way to register type-mapping.
- Resolve: When using IoC container, we don't need to create objects manually. Container does it for us. This is called resolution. Container must include some methods to resolve the specified type; container creates an object of specified type, injects required dependencies if any and returns it.
- Dispose: Container must manage the lifetime of dependent objects. Most IoC containers include different lifetime managers to manage an object's lifecycle and dispose of it.
Prefer composition over inheritance as it is easy to modify later, but do not use a compose-always approach.
Composition is simply when a class is composed of other classes; or to say it another way, an instance of an object has references to instances of other objects.
Inheritance is when a class inherits methods and properties from another class.
To favor composition over inheritance is a design principle that gives the design higher flexibility. It is more natural to build business-domain classes out of various components than trying to find commonality between them and creating a family tree. For example, a gas pedal and a wheel share very few common traits, yet are both vital components in a car. What they can do and how they can be used to benefit the car is easily defined. Composition also provides a more stable business domain in the long term as it is less prone to the quirks of the family members. In other words, it is better to compose what an object can do (HAS-A) than extend what it is (IS-A).
Initial design is simplified by identifying system object behaviors in separate interfaces instead of creating a hierarchical relationship to distribute behaviors among business-domain classes via inheritance. This approach more easily accommodates future requirements changes that would otherwise require a complete restructuring of business-domain classes in the inheritance model. Additionally, it avoids problems often associated with relatively minor changes to an inheritance-based model that includes several generations of classes.
The Flexible Box Module, usually referred to as flexbox, was designed as a one-dimensional layout model, and as a method that could offer space distribution between items in an interface and powerful alignment capabilities.
When we describe flexbox as being one dimensional we are describing the fact that flexbox deals with layout in one dimension at a time — either as a row or as a column. This can be contrasted with the two-dimensional model of CSS Grid Layout, which controls columns and rows together.
When working with flexbox you need to think in terms of two axes — the main axis and the cross axis. The main axis is defined by the flex-direction property, and the cross axis runs perpendicular to it. Everything we do with flexbox refers back to these axes, so it is worth understanding how they work from the outset.
The main axis is defined by flex-direction, which has four possible values:
rowrow-reversecolumncolumn-reverse
Should you choose row or row-reverse, your main axis will run along the row in the inline direction.
Choose column or column-reverse and your main axis will run from the top of the page to the bottom — in the block direction.
The cross axis runs perpendicular to the main axis, therefore if your flex-direction(main axis) is set to row or row-reverse the cross axis runs down the columns.
If your main axis is column or column-reverse then the cross axis runs along the rows.
Understanding which axis is which is important when we start to look at aligning and justifying flex items; flexbox features properties that align and justify content along one axis or the other.
The transform CSS property lets you rotate, scale, skew, or translate a given element. This is achieved by modifying the coordinate space of the CSS visual formatting model.
transform: matrix(1, 2, 3, 4, 5, 6);
transform: translate(120px, 50%);
transform: scale(2, 0.5);
transform: rotate(0.5turn);
transform: skew(30deg, 20deg);
transform: scale(0.5) translate(-100%, -100%);Being accessible is about making your website, with all of its data and functions, available for anyone, no matter how they have to use your website. — Katie Cunningham, Accessibility Handbook (O’Reilly)
For a beginner-friendly overview of accessibility, the Google Web Fundamentals guide is an excellent starting point. They explain the Acessibility Tree particularly well.
If you want to dive into a more hands-on learning plan with recommended activities, see Julie Grundy's Accessibility Learning Plan for Developers. Julie recommends resources and activities for:
- Writing semantic HTML
- Creating accessible styles
- Making images accessible
- Learning the methods for hiding content
- Building an accessible drop-down menu
- Building an accessible form
- Providing accessible error messages
- Accessibility testing
add(2, 5); // 7
add(2)(5); // 7Show Answer 💡
Basic function curry
function add(addend) {
return function (summand) {
return addend + summand;
};
}Generic function curry (supports both invocations)
// accepts partial list of arguments
function add(x, y) {
if (typeof y === "undefined") {
// partial
return function (y) {
return x + y;
};
}
return x + y;
}var text = "outside";
function logIt() {
console.log(text);
var text = "inside";
}
logIt();Show Answer 💡
In JavaScript, variables are "hoisted" to the top of the function. That is, unlike some other languages (such as C), a variable declared within a function is within scope throughout the function. So the compiler sees your function like this:
function logIt() {
var text;
console.log(text);
text = "inside";
} // <-- no semicolon after a function declarationWhen you declare text as a local variable inside logIt, it shadows the variable in the outer scope. And when a variable is declared, it is initialized to undefined. That's why undefined gets printed.
If you want to keep text in the outer scope, just leave off the var declaration inside the function.
var text = "outside";
function logIt() {
console.log(text); // logs 'outside' now
text = "inside";
}
logIt();Show Answer 💡
function fib(n) {
if (n <= 2) return 1;
let x = 0;
let y = 1;
for (var i = 0; i < n; i++) {
let tempY = y;
y = tempY + x;
x = tempY;
}
return y;
}Show Answer 💡
function flatten(array) {
return array.reduce((sum, el) => {
let flattenedArr = Array.isArray(el) ? flatten(el) : el;
return sum.concat(flattenedArr);
}, []);
}
flatten([1, 2, 3, 4, [5, [1, 2, 3, 4, 5, [4, 5]]]]);
// [ 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 4, 5 ]Show Answer 💡
function flatten(array) {
let clonedList = array.slice(0);
const flatList = [];
while (clonedList.length) {
const item = clonedList.shift();
if (item instanceof Array === true) {
clonedList = item.concat(clonedList);
} else {
flatList.push(item);
}
}
return flatList;
}
flatten([1, 2, 3, 4, [5, [1, 2, 3, 4, 5, [4, 5]]]]);
// [ 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 4, 5 ]Show Answer 💡
const MIN = 0;
const MAX = 1000;
function rand(min, max) {
return Math.random() * (max - min) + min;
}
class Node {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
}
function insert(root, key) {
const node = new Node(key);
if (!root) return node;
if (root.value > key && !root.left) {
root.left = node;
} else if (root.value < key && !root.right) {
root.right = node;
} else if (root.value > key) {
insert(root.left, key);
} else if (root.value < key) {
insert(root.right, key);
}
return root;
}
function getMaxNode(node) {
if (!node) return null;
if (!node.right) return node;
return getMaxNode(node.right);
}
function findSecondLargest(node) {
if (!node) return null;
// if the current node is the max, the second largest is the max
// node on the left tree.
if (node.left && !node.right) {
return getMaxNode(node.left);
}
// if the right child node is the max, the current node is the
// second largest.
if (node.right) {
if (!node.right.left && !node.right.right) {
return node;
}
}
// otherwise, move on to the right child.
return findSecondLargest(node.right);
}
// Build BST
let bst;
for (var i = 0; i < 10; i++) {
const randNo = rand(MIN, MAX);
bst = insert(bst, randNo);
}
console.log("largest", getMaxNode(bst).value);
console.log("second largest", findSecondLargest(bst).value);Given 2 identical DOM trees (but not equal) and one element of the first DOM tree, how would you find this element in the second DOM tree?
Example DOM:
<div id="root1">
<div>
<div></div>
</div>
<div>
<div id="node1"></div>
<div></div>
</div>
</div>
<div id="root2">
<div>
<div></div>
</div>
<div>
<div id="node2"></div>
<div></div>
</div>
</div>Show Answer 💡
/*
O O
/ \ / \
O O O O
/|\ /|\
O O O O O O
A B
/ \ / \
O O O O
/|\ /|\
x O O y O O
y = find(A, B, x);
*/
function getPath(rootNode, startingNode) {
const path = [];
let currentNode = startingNode;
while(currentNode !== rootNode) {
const parentNode = currentNode.parentElement;
const childIndex = Array.from(parentNode.children).indexOf(currentNode); // We only care about the index
path.push(childIndex);
currentNode = parentNode;
}
return path;
}
function findNode(rootNode, path) {
let currentNode = rootNode;
while (path.length) {
const childIndex = path[path.length - 1];
const childNode = currentNode.childen[childIndex]);
currentNode = childNode;
path.pop();
}
return currentNode;
}
function find(rootA, rootB, nodeX) {
const path = getPath(rootA, nodeX);
const nodeY = findNode(rootB, path);
return nodeY;
}Your implementation should fire the callback supplied as part of your subscription to be invoked with foo and bar as parameters. For example: emitter.emit('event_name', foo, bar);
Given an input array and another array that describes a new index for each element, mutate the input array so that each element ends up in their new index. Discuss the runtime of the algorithm and how you can be sure there won't be any infinite loops.
Show Answer 💡
let arr = ["a", "b", "c", "d", "e", "f"];
const indices = [2, 3, 4, 0, 5, 1];
//should return ["d", "f", "a", "b", "c", "e"]- O(n) space and O(n) time solution:
const indicesMap = indices.reduce((map, item, index) => {
map.set(item, index);
return map;
}, new Map());
arr = indices.map((val, index) => {
return arr[indicesMap.get(index)];
});
console.log(arr);- O(n2) (n*n) time solution:
arr = indices.map((val, index) => {
return arr[indices.indexOf(index)];
});Show Answer 💡
https://www.interviewcake.com/question/javascript/bst-checker
This question is designed to trick you. You MUST keep track of the min and max nodes. Do not evaluate only the children nodes in relation to the value of the parent node.
For more information please see: https://www.geeksforgeeks.org/a-program-to-check-if-a-binary-tree-is-bst-or-not/
Consider this BST:
3
/ \
2 5
/ \
1 4
Notice how the 4 is in the left sub tree (as a child of 2). It should actually be in the right subtree as a left hand child of 5.
The following solution is correct, but not efficient. It runs slowly since it traverses over some parts of the tree many times. A better solution looks at each node only once.
DO NOT USE THIS SOLUTION
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
function isValidBST(root, min = 0, max = 9999) {
if (!root) {
return true;
}
if (root.val >= max || root.val <= min) {
return false;
}
if (!!root.left && !isValidBST(root.left, min, root.val)) {
return false;
}
if (!!root.right && !isValidBST(root.right, root.val, max)) {
return false;
}
return true;
}The trick is to write a utility help function that traverses the tree keeping track of the narrowing min and max allowed values as it goes, looking at each node only once!
DO NOT USE THIS SOLUTION
This is a more efficient and correct solution:
var isValidBST = function (root, min, max) {
return isBSTUtil(root, min, max);
};
var isBSTUtil = function (root, min, max) {
if (!root) {
return true;
}
if (root.val < min || root.val > max) {
return false;
}
return (
isBSTUtil(root.left, min, root.val - 1) &&
isBSTUtil(root.right, root.val + 1, max)
);
};BUT the best solution is to do an in-order traversal of the given tree and store the result in a temp array. Then check if the array is sorted, if it is then the tree is a valid BST. This is the general idea, but we can improve upon it further but removing the temp array and just checking the previously visited node value. If the value is less than the previous value then tree is not bst.
Time Complexity: O(n)
In-order traversal
- Traverse the left subtree, i.e., call Inorder(left-subtree)
- Visit the root.
- Traverse the right subtree, i.e., call Inorder(right-subtree)
var isValidBST = function (root) {
if (!root) return true;
const stack = [];
let prev;
while (!!root || stack.length !== 0) {
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
if (!!prev && root.val <= prev.val) {
return false;
}
prev = root;
root = root.right;
}
return true;
};- Your function will have one input: the head of the list.
- Your function should return the new head of the list.
Here's a sample linked list node class:
function LinkedListNode(value) {
this.value = value;
this.next = null;
}Write a function kthToLastNode() that takes an integer k and the headNode of a singly-linked list, and returns the kth to last node in the list.
Show Answer 💡
The simplest approach is to check if the number is divisible by every integer less than itself.
const isPrime = (num) => {
for (let i = 2; i < num; i++) if (num % i === 0) return false;
return num > 1;
};A more efficient approach is to check if the number is divisible by every integer up to its square root.
If
n = a * bwherea <= b, a is always going to be less or equal to the square root ofn.
const isPrime = (num) => {
const limit = Math.sqrt(num);
for (let i = 2; i <= limit i++) if (num % i === 0) return false;
return num > 1;
};A slightly more efficient approach is also to avoid all even numbers since they are divisible by 2; hence can't be prime.
const isPrime = (num) => {
if (num % 2 === 0) return num === 2;
const limit = Math.sqrt(num);
for (let i = 3; i <= limit; i+=2)
if (num % i === 0) return false;
return num > 1;
};We can keep creating slightly more efficient versions by eliminating multiples of known primes.
For 2 & 3, it boils down to
6k + i. We can even write more efficient versions following the same pattern(p1 * p2 * ... * pn)k + i.
const isPrime = (num) => {
if (num % 2 === 0) return num === 2;
if (num % 3 === 0) return num === 3;
const limit = Math.sqrt(num);
for (let i = 5; i <= limit; i+=6)
if (num % i === 0 || num % (i + 2) === 0) return false;
return num > 1;
};Show Answer 💡
The simplest approach is to use the Set object which lets you store unique values of any type. In other words, Set will automatically remove duplicates for us.
const names = ["John", "Paul", "George", "Ringo", "John"];
let unique = [...new Set(names)];
console.log(unique); // 'John', 'Paul', 'George', 'Ringo'Another option is to use filter().
const names = ["John", "Paul", "George", "Ringo", "John"];
let x = (names) => names.filter((v, i) => names.indexOf(v) === i);
x(names); // 'John', 'Paul', 'George', 'Ringo'And finally we can use forEach().
const names = ["John", "Paul", "George", "Ringo", "John"];
function removeDups(names) {
let unique = {};
names.forEach(function (i) {
if (!unique[i]) {
unique[i] = true;
}
});
return Object.keys(unique);
}
removeDups(names); // // 'John', 'Paul', 'George', 'Ringo'Show Answer 💡
a = a + b;
b = a - b;
a = a - b;Show Answer 💡
Since strings in JavaScript are immutable, first convert the string into an array of characters, do the in-place reversal on that array, and re-join that array into a string before returning it. This isn't technically "in-place" and the array of characters will cost O(n) additional space, but it's a reasonable way to stay within the spirit of the challenge.
https://www.interviewcake.com/question/javascript/reverse-string-in-place
function reverseString(str) {
// Step 1. Use the split() method to return a new array
var splitString = str.split(""); // ["h", "e", "l", "l", "o"]
// Step 2. Use the reverse() method to reverse the new created array
var reverseArray = splitString.reverse(); // ["o", "l", "l", "e", "h"]
// Step 3. Use the join() method to join all elements of the array into a string
var joinArray = reverseArray.join(""); // "olleh"
//Step 4. Return the reversed string
return joinArray; // "olleh"
}
reverseString("hello");Show Answer 💡
Similar to the above, but take note of the space to denote a new word.
function reverseString(str) {
return str.split(" ").reverse().join(" ");
}
reverseString("Hello, World. My Name is Daniel Del Core");Show Answer 💡
function palindrome(str) {
// String clean up to support sentences etc
const cleanStr = str.toLowerCase();
const reverseStr = cleanStr.split("").reverse().join("");
return cleanStr === reverseStr;
}
palindrome("race car"); // TrueShow Answer 💡
function findLargestSum(arr) {
const [largest, secondLargest] = arr.reduce(
([largest, secondLargest], currentValue) => {
if (currentValue > largest) {
return [currentValue, largest];
}
if (currentValue > secondLargest) {
return [largest, currentValue];
}
return [largest, secondLargest];
},
[Number.MIN_VALUE, Number.MIN_VALUE]
);
return largest + secondLargest;
}
findLargestSum([7, 5, 3, -1, 4, 34, 8, 9, 6, 0]); // 43Show Answer 💡
Group the promises into batches of 50 (for example) and recursively execute each batch until completion or error. If an error occurs you could either retry, with that batch, or throw an error to the client as timeouts and other server errors are likely to occur.
Don't forget! If duplicate requests occur, you can simply memoize the function and safely return the same result to side-step the network request and improve performance.
There's no answer here - yet! Suggest one by creating a pull request 🙏