LinkedHashSet是一个能记录插入顺序的hashset,继承自HashSet,主要调用HashSet下面这个构造方法。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}LinkedHashSet使用LinkedHashMap实现的,LinkedHashMap又继承自HashMap,如果你看过我写的LinkedHashMap源码分析和HashSet源码分析,理解LinkedHashSet就非常容易了。
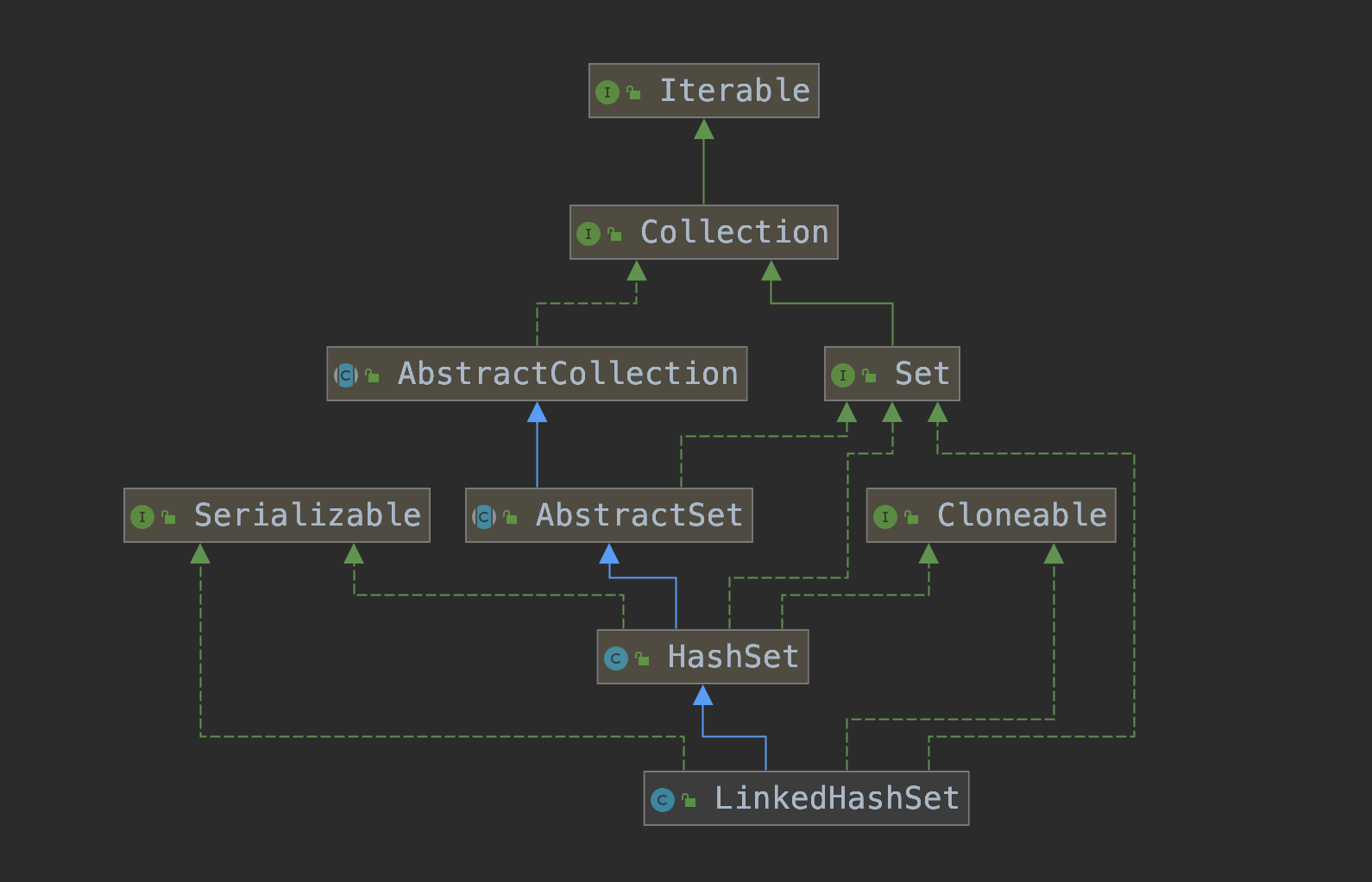
LinkedHashSet是基于双向链表和HashMap实现的,HashMap的key就是LinkedHashSet就是不重复的集合,HashMap的Value指向同一个Object实例。
一共没多少源码
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
@Override
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}LinkedHashSet的构造方法都调用了HashSet同一个构造方法,
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}LinkedHashSet是基于LinkedHashMap实现的,就是调用HashMap,看一下他的add方法吧
他的add方法就是hashset的add方法
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}LinkedHashMap没有覆写put方法,所以还是调用HashMap的put方法,HashMap的put方法又调用了putVal方法,putVal新增结点调用了newNode方法,LinkedHashMap覆写了newNode方法,在newNode方法中实现了链表功能。