LinkedHashMap是一个可以保证元素插入顺序的hashmap,可以按照元素的插入顺序迭代元素。还可以按照访问顺序迭代元素,最近访问的元素移动到链表的尾部。
LinkedHashMap允许key和value都为null情况,非线程安全。
LinkedHashMap是利用hashmap和双向链表实现的。
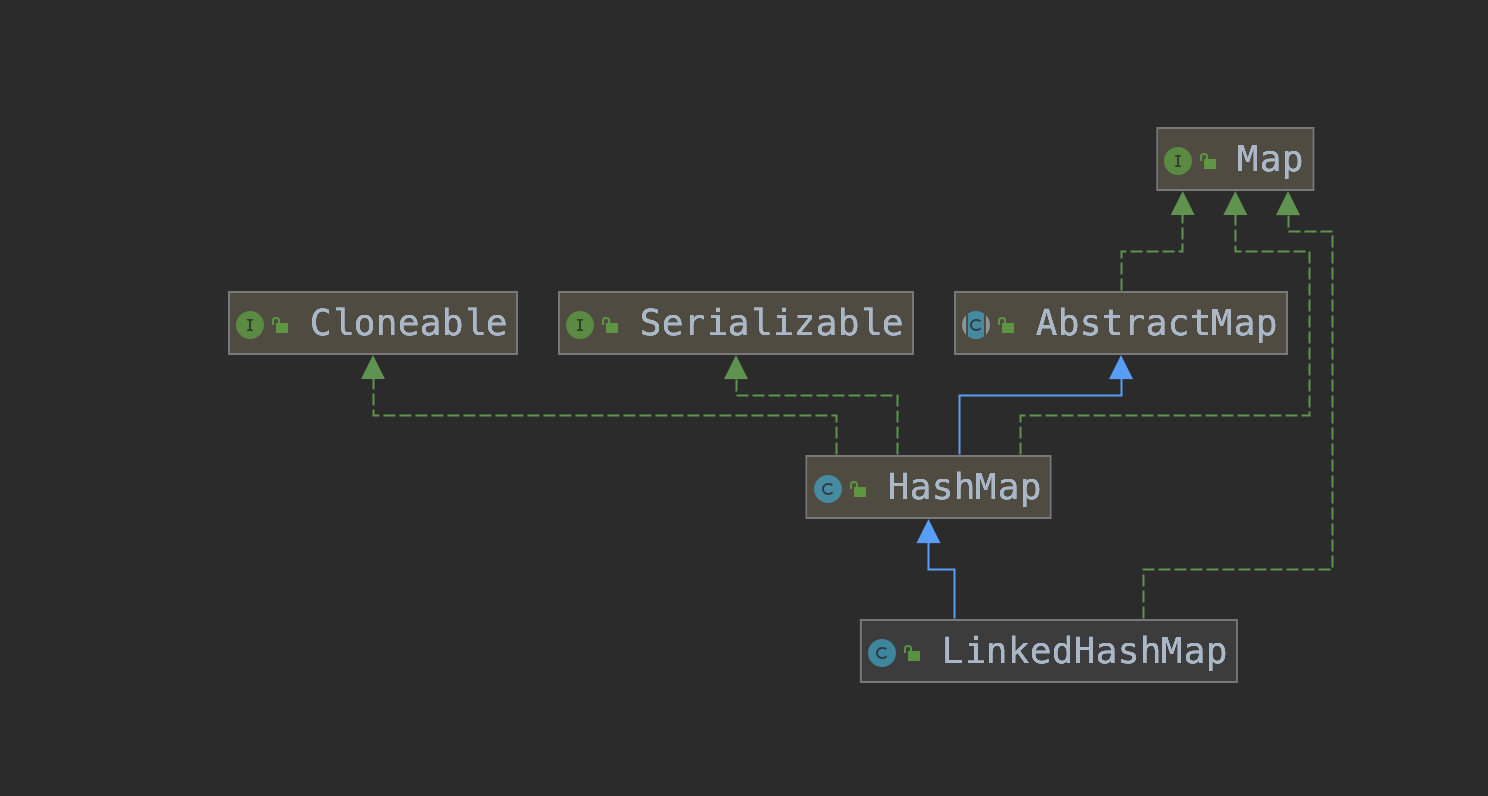
LinkedHashMap继承了HashMap,实现了Map接口。
源码也不是很复杂,下面就开始愉快的阅读之旅。
主要实现原理是利用双向链表将每个key、value结点连接起来,每个hashmap结点就是双向链表的结点的一部分,双向链表的结点还包括前驱结点和后继结点,用于维持链表顺序。下面的Entry<K,V>就双向链表的结点结构。
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}看源码你们可能困惑,LinkedHashMap没有put方法如何实现put功能的?LinkedHashMap继承了HashMap,但是没有覆写put方法,怎么实现链表的功能?这些问题的答案只能在hashmap源码中寻找了,看看hashmap源码putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果table=null或者tab.length=0,就进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 此处对应没有产生hash冲突的情况,直接使tab[i]等于一个新创建的Node结点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else { // 产生hash冲突
Node<K,V> e; K k;
// 第一个结点就是要找的结点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
// 到红黑树中查找
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// p.next = null表示没有找到,直接插入一个新结点
p.next = newNode(hash, key, value, null);
// 如果binCount大于等于7,就转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 更新结点值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 如果大于阈值,就进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}hashmap源码putVal方法每次新增结点是调用了newNode方法,LinkedHashMap就是覆写了newNode方法实现链表功能的。
// 新增一个结点,直接加到链表尾部
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// 将p结点链接到当前尾结点的后面
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}还可以看到,hashmap的putVal方法还调用了两个空方法,afterNodeAccess和afterNodeInsertion,LinkedHashMap同样覆写了这两个方法,用这两个方法就可以实现LRU,删除最近最少使用的结点。这就是多态的威力。
看懂了LinkedHashMap的put方法原理,其他功能就比较简单了,这里直接贴出所有注释。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
* 链表结点结构
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
private static final long serialVersionUID = 3801124242820219131L;
/**
* The head (eldest) of the doubly linked list.
* 头结点,是最先插入的结点
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
* 尾结点,是最后插入的结点
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
* accessOrder=true是访问顺序,accessOrder=false是插入顺序
* 访问顺序指的是,如果某个结点被访问,就将这个结点移动到链表尾部
* @serial
*/
final boolean accessOrder;
// internal utilities
// link at the end of list
// 将p结点链接到当前尾结点的后面
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
// apply src's links to dst
// 将src替换成dst结点
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
// b是src的前驱结点
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
// a是src的后继结点
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
// overrides of HashMap hook methods
// 回到初始化状态
void reinitialize() {
super.reinitialize();
head = tail = null;
}
// 新增一个结点,直接加到链表尾部
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
// 将p的下一结点替换成next结点
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
LinkedHashMap.Entry<K,V> t =
new LinkedHashMap.Entry<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
TreeNode<K,V> t = new TreeNode<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
// 删除e结点
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
// 在一个结点插入后可以进行的操作,可以移除最近最少使用的结点
// 覆写removeEldestEntry,就可以实现LRU
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 将e结点移动到链表尾部
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
// b=null说明p就是首结点,此时将p的下一结点设置为首结点
if (b == null)
head = a;
else
// 相当于将p结点删除
b.after = a;
// a!=null,将b和a链接起来
if (a != null)
a.before = b;
else
// a=null,b就是最后一个结点
last = b;
// last=null说明p是唯一的结点,即是首结点也是尾结点
if (last == null)
head = p;
else {
// last!=null,将p插入到last的后面
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
/**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the specified initial capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
// 默认按照插入顺序访问
accessOrder = false;
}
/**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the specified initial capacity and a default load factor (0.75).
*
* @param initialCapacity the initial capacity
* @throws IllegalArgumentException if the initial capacity is negative
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
/**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
/**
* Constructs an insertion-ordered <tt>LinkedHashMap</tt> instance with
* the same mappings as the specified map. The <tt>LinkedHashMap</tt>
* instance is created with a default load factor (0.75) and an initial
* capacity sufficient to hold the mappings in the specified map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
/**
* Returns <tt>true</tt> if this map maps one or more keys to the
* specified value.
*
* @param value value whose presence in this map is to be tested
* @return <tt>true</tt> if this map maps one or more keys to the
* specified value
*/
public boolean containsValue(Object value) {
// 挨个遍历
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*/
public V get(Object key) {
Node<K,V> e;
// 如果e=null,就返回null,不存在这个key
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
/**
* {@inheritDoc}
*/
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
/**
* {@inheritDoc}
*/
public void clear() {
super.clear();
head = tail = null;
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new LinkedKeySet();
keySet = ks;
}
return ks;
}
final class LinkedKeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<K> iterator() {
return new LinkedKeyIterator();
}
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super K> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
public Collection<V> values() {
Collection<V> vs = values;
if (vs == null) {
vs = new LinkedValues();
values = vs;
}
return vs;
}
final class LinkedValues extends AbstractCollection<V> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<V> iterator() {
return new LinkedValueIterator();
}
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator<V> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED);
}
public final void forEach(Consumer<? super V> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator<Map.Entry<K,V>> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
// Map overrides
public void forEach(BiConsumer<? super K, ? super V> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
if (function == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
e.value = function.apply(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
// Iterators
abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount;
LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator<K> {
public final K next() { return nextNode().getKey(); }
}
final class LinkedValueIterator extends LinkedHashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
}