PYTHON-API: vim.eval breaks, if the string a:items contains invalid utf-8 characters
#3213
Comments
vim.eval breaks, if the string a:items contains invalid utf-8 charactersvim.eval breaks, if the string a:items contains invalid utf-8 characters
|
[...]
Is `vim.eval('a:items')` supposed to crash if the items in the argument passed
to it (`a:item`) contains invalid characters?
I believe that is the be expected, since it uses the argument as text,
thus if the text is invalid it won't work.
Is there any way around it?
try/catch perhaps?
…--
hundred-and-one symptoms of being an internet addict:
254. You wake up daily with your keyboard printed on your forehead.
/// Bram Moolenaar -- Bram@Moolenaar.net -- http://www.Moolenaar.net \\\
/// sponsor Vim, vote for features -- http://www.Vim.org/sponsor/ \\\
\\\ an exciting new programming language -- http://www.Zimbu.org ///
\\\ help me help AIDS victims -- http://ICCF-Holland.org ///
|
|
OT1H, IMO crashes ought not no happen. Best regards, |
to do exception handling. Maybe, I am missing something.. but I haven't see any other way of evaluating a The first option you mentioned would be ok.. but will probably not help too much, as I haven't seen any other way of evaluating a The I wonder why I have investigated the 3rd option, but outside VIM.. using perl-script.. but it tends to be error-prone. It would be great if |
|
Please don't fallback to latin1. I've seen too much of garbage caused by that. There are several ways to handle this:
|
|
BTW, I don't know what exact problem @alphaCTzo7G has encountered. The _identifier.py file is valid UTF-8 but not valid ASCII. Maybe you are using Python 2 or a default encoding other than UTF-8? |
|
@lilydjwg.. Interesting.. how are you determining that If it isn't then I am wondering what's your hypothesis behind why |
|
There are mutliple other python libraries that have shown similar effects (if characters from these files are present in Here are more examples..
I did another test from here: https://stackoverflow.com/a/41741313/4752883 using This returns invalid character only for the file in #1. misc.html at the location For #1 ( The So the 2 tests above seem to give conflicting reports. One hypothesis could be that Note: I got the |
|
just to provide some more details.. in case these are important.. I am on here's the output of VIM - Vi IMproved 8.1 (2018 May 17, compiled Jul 1 2018 10:45:10) |
|
To tell if a file is in valid UTF-8, you can just open it in Vim with You can get the file with cloning in both github and bitbucket: use the "raw" link on the page. You can try to echo a:items out within VimL to see what it's like. Also, try Python 3 if you aren't using it already. |
|
@lilydjwg .. thank you very much for your suggestions..I will go through them and test them. Also..I am most likely using |
|
@lilydjwg, you are right
I am indeed using Regarding your question of file encoding, I have |



|
@lilydjwg .. Is this what you meant?
I put However, it doesn't actually print out anything.. This fork of ctrlp-py-matcher does print out the incorrect characters: https://github.com/ludovicchabant/ctrlp-py-matcher/blob/2f6947480203b734b069e5d9f69ba440db6b4698/autoload/pymatcher.py#L22 And from this is seems to be the 204th character.. so I opened up the It even gets weirder.. I can't even do On line 211, I tried navigating to the last character and I was able to do that.. Then I tried to navigate to the last character using $ on the 212th line.. but couldn't do so.. even though there are characters left on the line.. I can't even navigate past the 65th character |


|
There is a corrupted character in your tags, and Vim has issues calculating the correct display width of the broken bytes. You can report issues to the tool that has generated this tags file. (It seems to me that the tool clips long strings by bytes instead of characters.) |
|
@lilydjwg .. actually not sure if its a problem with Universal ctags, (compiled a few days back.) there seems to be multiple issues here.. One was with the python-api.. I thought what I posted above was related but it seems the issue in this image is related to the terminal I use (Putty), but is also present in Kitty, MobaXterm, BitVise ssh client as well tmux/tmux#1409 (comment) If I try this in Gvim, or use a different terminal such as Gnome-terminal, or rxvt-unicode that has unicode support, this issue in the above image doesn't happen. So I will probably have to report these to them (Putty/Kitty etc).. Its not too much of a issue.. and probably a edge case, so maybe thats why they haven't bothered to fix it.
|
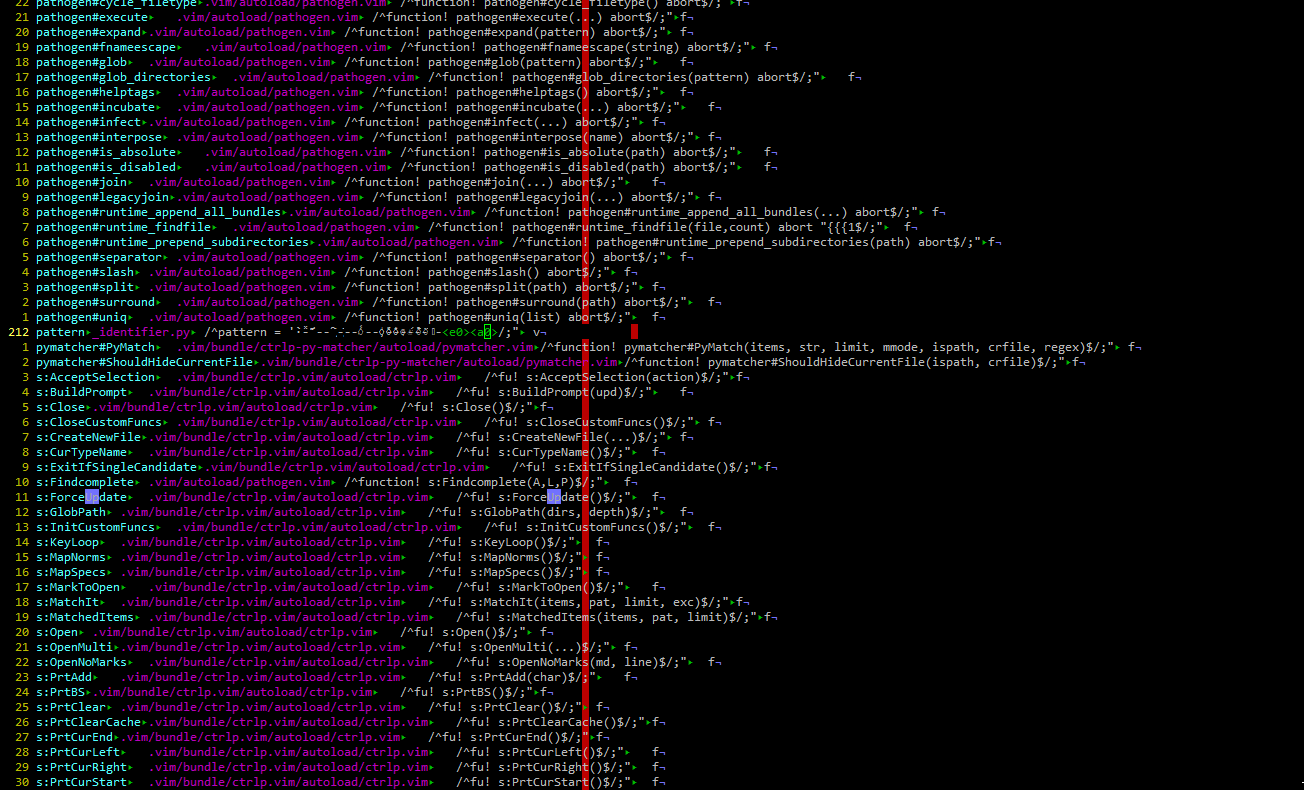
|
On Tue, Jul 24, 2018 at 4:17 AM alphaCTzo7G ***@***.***> wrote:
@lilydjwg <https://github.com/lilydjwg> .. actually not sure if its a
problem with Universal ctags, (compiled a few days back.) there seems to be
multiple issues here.. One was with the python-api..
I thought what I posted above was related but it seems the issue in this
image
[image: image]
<https://user-images.githubusercontent.com/29691914/43110872-305860be-8ea3-11e8-99b1-5c4a747bd40d.png>
is related to the terminal I use (Putty), but is also present in Kitty,
MobaXterm, BitVise ssh client as well tmux/tmux#1409 (comment)
<tmux/tmux#1409 (comment)>
If I try this in Gvim, or use a different terminal such as Gnome-terminal,
or rxvt-unicode that has unicode support, this issue in the above image
doesn't happen. So I will probably have to report these to them
(Putty/Kitty etc).. Its not too much of a issue.. and probably a edge case,
so maybe thats why they haven't bothered to fix it.
vim.eval still breaks for the 3 files I posted regardless of what
terminal I use or if I use Gvim..
`vim.bindeval` always uses `bytes` in place of `str` regardless of
`&encoding` and Python version, so you can always choose what you to do
with non-UTF-8 text. Though it is not without issues (or features which may
cause issues):
- For each container (list, dictionary) it will return not Python’s `list`
or `dict`, but a binding to the container. That may need to be converted
depending on where you pass that container.
- `bytes` is harder to use in Python 3 as they are no longer meant to be
text strings. You probably just not *can* choose in this case, but *must*
choose each time.
- Since Python is in external process in Neovim naturally Neovim does not
support `bindeval`. (And should it support each access would invoke IPC
which directly opposes the initial reason of `bindeval` existence - to make
certain code faster.)
… —
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#3213 (comment)>
--
--
You received this message from the "vim_dev" maillist.
Do not top-post! Type your reply below the text you are replying to.
For more information, visit http://www.vim.org/maillist.php
---
You received this message because you are subscribed to the Google Groups
"vim_dev" group.
To unsubscribe from this group and stop receiving emails from it, send an
email to ***@***.***
For more options, visit https://groups.google.com/d/optout.
|
@lilydjwg, actually you are right about bringing up the tags file. Thanks for pointing this out.. for some reason, I didn't expect that even though the While the picture I posted before regarding the location of the cursor is Here's some evidence. Note to isolate the problem, this is run a fresh Ubuntu With
With
|


|
just thought I would update this.. @b4n has created a PR here to Universal-ctags: universal-ctags/ctags#1807 and it seems that ctags no longer cutting at an arbitrary byte position.
I will investigate the other option that that others proposed here.. |
|
|
|
@k-takata .. Thanks I have seen that.. unfortunately, I won't know what the encoding is for any given file for a random library that could have thousands of files. This solution may work for Based on what @b4n mentioned here: universal-ctags/ctags#1805 (comment).. it seems the only way around this is to postprocess the tags file or if |
|
I suppose this is not a Vim issue, so this can be closed, right? |
Hi all,
I was trying to figure out why
ctrlp-py-matcheris not working when certainfiles are present in my repo.
I have this file in my folder:
https://github.com/pallets/jinja/blob/master/jinja2/_identifier.py
Now I try to use
ctrlp,ctrlp-py-matcherto navigate tags. I usectagsto generate the tags files.However, I found that even though the correct tags were being generated,
:CtrlPTagswasn't showing any tags.I have traced it down to the file above
https://github.com/pallets/jinja/blob/master/jinja2/_identifier.py
which contains UTF-8 header and possibly incorrect characters,
vim.evalin thectrlp-py-matcherfails.Heres the line which fails
https://github.com/FelikZ/ctrlp-py-matcher/blob/cf63fd546f1e80dd4db3db96afbeaad301d21f13/autoload/pymatcher.py#L7
Heres the output of
iconvrun on the file:Other people such as @ludovicchabant also found a similar problem and had to
work around it as shown in his fork of the
ctrlp-py-matcherrepo, and alsopost process the tags file(https://ludovic.chabant.com/devblog/2017/02/25/aaa-gamedev-with-vim/) :
https://github.com/ludovicchabant/ctrlp-py-matcher/blob/2f6947480203b734b069e5d9f69ba440db6b4698/autoload/pymatcher.py#L22
If I use something like
perl -i -pe 's/[^[:ascii:]]//g;', to remove anynon-ascii or non-utf-8 characters, then the tag file generated using
ctags -Rstarts working again.
Currently, I basically excluded the entire
pythonenv folder to prevent theseissues. I can ofcourse, do some post-processing of
tagsfile afterctagsgenerates the tags file and remove the BOM header or invalid characters,
but it seems a bit hacky.
The best way would be if
vim.eval('a:items')doesn't error out, even if itsargument contains
BOMheaders or invalidutf-8characters, or if thereexists another function other than
vim.evalwhich won't crash when the stringit contains has
BOMheaders.Is
vim.eval('a:items')supposed to crash if the items in the argument passedto it (
a:item) contains invalid characters?Is there any way around it?
The text was updated successfully, but these errors were encountered: