TypeError: Trainer.__init__() got an unexpected keyword argument 'gpus' #93
Comments
|
This repo hasn't been updated to Pytorch 2.0 yet. This problem is due to an earlier change in pytorch-lightning where the |
|
I tried with |
|
It is due to the pytorch-lightning version. If you update to the latest code and use the version in the requirements.txt ( |
|
Did this fix the error? |
|
No, but I removed( commented out ) some lines from the config file and now its is running without error, although my gpu runs out of memeory everytime I try to train the model, that's some different issue I guess. |
|
Are you on the latest commit? If there is a config in the repo that does not work out-of-the-box on the latest commit and with the provided requirements file, could you indicate which experiment config it is? |
|
To make sure, I am not running with my changes, I cloned the main branch ( latest commit ) again, and try to train with Actually, I was studying the SaShiMi model and trying to train with I tried ( in another clone ) the suggested This are my torch version |
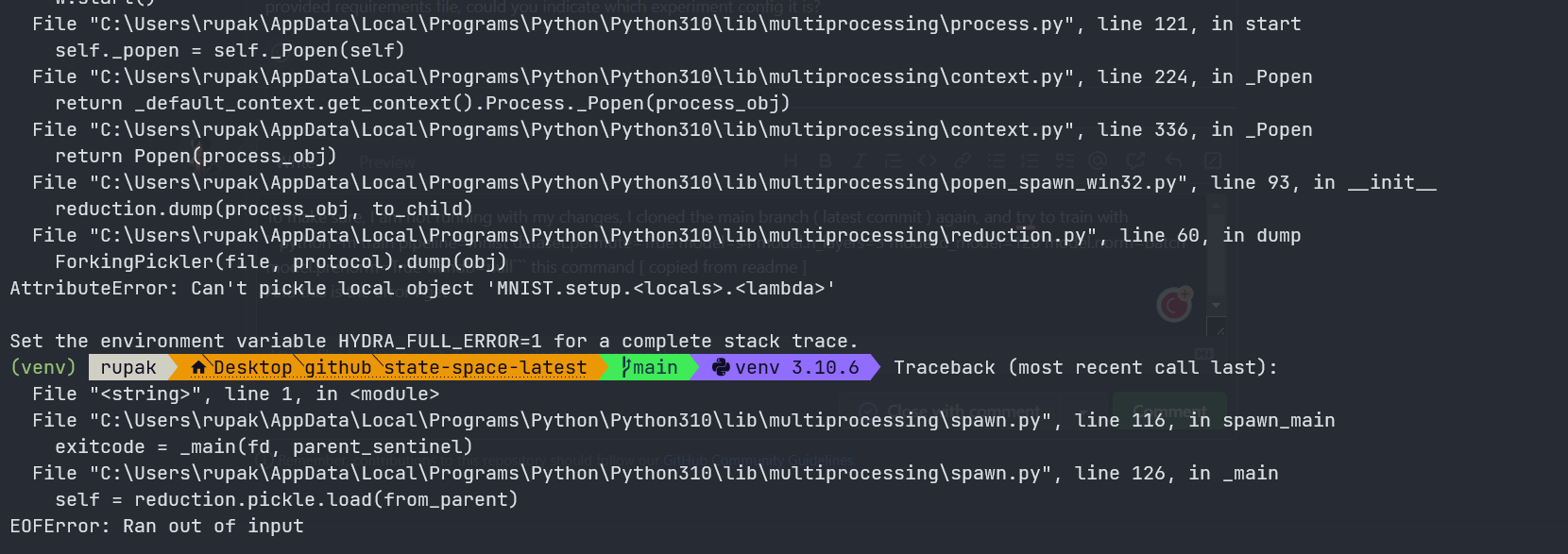

|
That is strange. What OS and GPU are you using? Your first error reminds me of something I saw when I tried running the repo locally on my Macbook, and I never figured out the issue. The second issue seems related to package versions. What version of pytorch-lightning are you on? |
|
I am using OS: Windows 11 and Ubuntu wsl |
|
Unfortunately I don't know the answer to this. My guess is that it's likely to be related to one of these packages + environment. I recently set up this repo in a new environment (standard Linux + CUDA + A100 GPU) and it works well. To isolate the problem I think it might be useful to try a minimal setup with Pytorch Lightning + wandb; these packages should have examples of a setting up a basic LightningTrainer for MNIST. I suspect you might run into the same issues. |
|
I fix it with "pip install pytorch-lightning==1.7.2" |
How to fix this ? I am getting this same issue from 2 different machine
The text was updated successfully, but these errors were encountered: