


ドキュメント | Google Group | チュートリアル | インストール | 使用方法 | スライド | Quickstart | Open Bandit Dataset | 解説ブログ記事
Table of Contents
Open Bandit Datasetは, バンディットアルゴリズムやオフ方策評価にまつわる研究を促進するための大規模公開実データです. 本データセットは, 日本最大のファッションEコマース企業である株式会社ZOZOが提供しています. 同社が運営する大規模ファッションECサイトZOZOTOWNでは, いくつかの多腕バンディットアルゴリズムを用いてユーザにファッションアイテムを推薦しています. バンディットアルゴリズムによるファッションアイテム推薦の例は以下の図1の通りです. 各ユーザリクエストに対して, 3つのファッションアイテムが同時に推薦されることがわかります.

図1. ZOZOTOWNにおけるファッションアイテムの推薦の例
2019年11月下旬の7日間にわたるデータ収集実験において, 全アイテム(all)・男性用アイテム(men)・女性用アイテム(women)に対応する3つの「キャンペーン」でデータを収集しました. それぞれのキャンペーンでは, 各ユーザのインプレッションに対してランダム方策(Random)またはトンプソン抽出方策(Bernoulli Thompson Sampling; Bernoulli TS)のいずれかを確率的にランダムに選択して適用しています. 図2はOpen Bandit Datasetの記述統計を示しています.
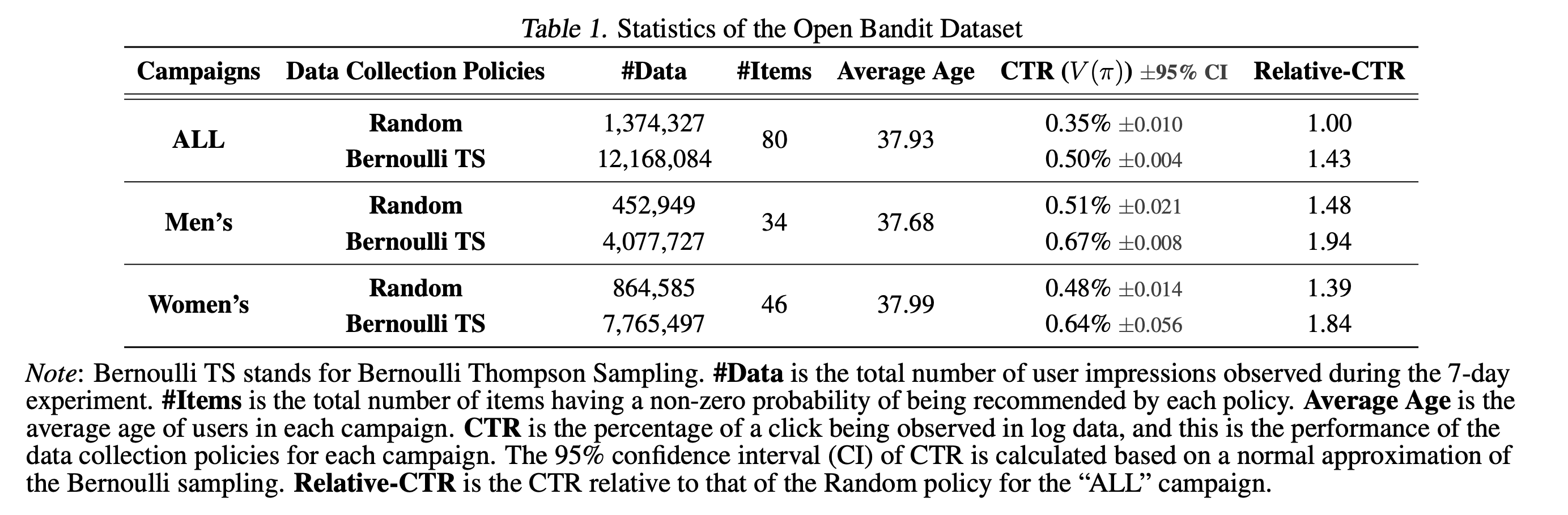
図2. Open Bandit Datasetのキャンペーンとデータ収集方策ごとの記述統計
実装例を実行するための少量版データは, ./obd/にあります. Open Bandit Datasetのフルサイズ版はhttps://research.zozo.com/data.htmlにあります. 動作確認等には少量版を, 研究用途にはフルサイズ版を活用してください.
Open Bandit Pipelineは, データセットの前処理・オフ方策学習・オフ方策推定量の評価を簡単に行うためのPythonパッケージです. Open Bandit Pipelineを活用することで, 研究者はオフ方策推定量 (OPE estimator) の実装に集中して現実的で再現性のある方法で他の手法との性能比較を行うことができるようになります. オフ方策評価(Off-Policy Evaluation)については, こちらのブログ記事をご確認ください.

図3. Open Bandit Pipelineの構成
Open Bandit Pipelineは, 以下の主要モジュールで構成されています.
- datasetモジュール: このモジュールは, Open Bandit Dataset用のデータ読み込みクラスとデータの前処理するための柔軟なインターフェースを提供します. また人工データを生成するクラスや多クラス分類データをバンディットデータに変換するためのクラスも実装しています.
- policyモジュール: このモジュールは, バンディットアルゴリズムのためのインターフェイスを提供します. 加えて, いくつかの標準なバンディットアルゴリズムを実装しています.
- opeモジュール: このモジュールは, いくつかの標準的なオフ方策推定量を実装しています. また新たにオフ方策推定量を実装するためのインターフェースも提供しています.
バンディットアルゴリズム (policy moduleに実装)
- Online
- Non-Contextual (Context-free)
- Random
- Epsilon Greedy
- Bernoulli Thompson Sampling
- Contextual (Linear)
- Linear Epsilon Greedy
- Linear Thompson Sampling
- Linear Upper Confidence Bound
- Contextual (Logistic)
- Logistic Epsilon Greedy
- Logistic Thompson Sampling
- Logistic Upper Confidence Bound
- Non-Contextual (Context-free)
- Offline (Off-Policy Learning)
- Inverse Probability Weighting (IPW) Learner
- Neural Network-based Policy Learner
オフ方策推定量 (ope moduleに実装)
- OPE of Online Bandit Algorithms
- OPE of Offline Bandit Algorithms
- OPE of Offline Slate Bandit Algorithms
- OPE of Offline Bandit Algorithms with Continuous Actions
Open Bandit Pipelineは, 上記のアルゴリズムやオフ方策推定量に加えて柔軟なインターフェースも提供しています. したがって研究者は, 独自のバンディットアルゴリズムや推定量を容易に実装することでそれらの性能を評価できます. さらにOpen Bandit Pipelineは, 実バンディットフィードバックデータを扱うためのインタフェースを含んでいます. したがって, エンジニアやデータサイエンティストなどの実践者は, 自社のデータセットをOpen Bandit Pipelineと組み合わせることで簡単にオフ方策評価を行うことができます.
Open Bandit Dataset及びOpen Bandit Pipelineでは, 以下の研究テーマに関する実験評価を行うことができます.
-
バンディットアルゴリズムの性能評価 (Evaluation of Bandit Algorithms):Open Bandit Datasetには, ランダム方策によって収集された大規模なログデータが含まれています. それを用いることで, 新しいオンラインバンディットアルゴリズムの性能を評価することが可能です.
-
オフ方策評価の正確さの評価 (Evaluation of Off-Policy Evaluation):Open Bandit Datasetは, 複数の方策を実システム上で同時に走らせることにより生成されたログデータで構成されています. またOpen Bandit Pipelineを用いることで, データ収集に用いられた方策を再現できます. そのため, オフ方策推定量の推定精度の評価を行うことができます.
以下の通り, pipを用いてOpen Bandit Pipelineをダウンロードできます.
pip install obpまた, 本リポジトリをcloneしてセットアップすることもできます.
git clone https://github.com/st-tech/zr-obp
cd zr-obp
python setup.py installPythonおよび利用パッケージのバージョンは以下の通りです。
[tool.poetry.dependencies]
python = ">=3.7.1,<3.10"
torch = "^1.9.0"
scikit-learn = "^0.24.2"
pandas = "^1.3.2"
numpy = "^1.21.2"
matplotlib = "^3.4.3"
tqdm = "^4.62.2"
scipy = "^1.7.1"
PyYAML = "^5.4.1"
seaborn = "^0.11.2"
pyieoe = "^0.1.1"
pingouin = "^0.4.0"
これらのパッケージのバージョンが異なると、使用方法や挙動が本書執筆時点と異なる場合があるので、注意してください。
ここでは, Open Bandit Pipelineの使用法を説明します. 具体例として, Open Bandit Datasetを用いて, トンプソン抽出方策の性能をオフライン評価する流れを実装します. 人工データや多クラス分類データを用いたオフ方策評価の実装法は, 英語版のREAMDEやexamples/quickstart/をご確認ください.
以下に示すように, 約10行のコードでオフ方策評価の流れを実装できます.
# Inverse Probability Weightingとランダム方策によって生成されたログデータを用いて, BernoulliTSの性能をオフラインで評価する
from obp.dataset import OpenBanditDataset
from obp.policy import BernoulliTS
from obp.ope import OffPolicyEvaluation, InverseProbabilityWeighting as IPW
# (1) データの読み込みと前処理
dataset = OpenBanditDataset(behavior_policy='random', campaign='all')
bandit_feedback = dataset.obtain_batch_bandit_feedback()
# (2) オフ方策学習
evaluation_policy = BernoulliTS(
n_actions=dataset.n_actions,
len_list=dataset.len_list,
is_zozotown_prior=True,
campaign="all",
random_state=12345
)
action_dist = evaluation_policy.compute_batch_action_dist(
n_sim=100000, n_rounds=bandit_feedback["n_rounds"]
)
# (3) オフ方策評価
ope = OffPolicyEvaluation(bandit_feedback=bandit_feedback, ope_estimators=[IPW()])
estimated_policy_value = ope.estimate_policy_values(action_dist=action_dist)
# ランダム方策に対するトンプソン抽出方策の性能の改善率(相対クリック率)
relative_policy_value_of_bernoulli_ts = estimated_policy_value['ipw'] / bandit_feedback['reward'].mean()
print(relative_policy_value_of_bernoulli_ts)
1.198126...以下, 重要な要素について説明します.
Open Bandit Pipelineには, Open Bandit Dataset用のデータ読み込みインターフェースを用意しています. これを用いることで, Open Bandit Datasetの読み込みや前処理を簡潔に行うことができます.
# 「全アイテムキャンペーン (all)」においてランダム方策が集めたログデータを読み込む.
# OpenBanditDatasetクラスにはデータを収集した方策とキャンペーンを指定する.
dataset = OpenBanditDataset(behavior_policy='random', campaign='all')
# オフ方策学習やオフ方策評価に用いるログデータを得る.
bandit_feedback = dataset.obtain_batch_bandit_feedback()
print(bandit_feedback.keys())
# dict_keys(['n_rounds', 'n_actions', 'action', 'position', 'reward', 'pscore', 'context', 'action_context'])obp.dataset.OpenBanditDataset クラスの pre_process メソッドに, 独自の特徴量エンジニアリングを実装することもできます. custom_dataset.pyには, 新しい特徴量エンジニアリングを実装する例を示しています. また, obp.dataset.BaseBanditDatasetクラスのインターフェースに従って新たなクラスを実装することで, 将来公開されるであろうOpen Bandit Dataset以外のバンディットデータセットや自社に特有のバンディットデータを扱うこともできます.
前処理の後は, 次のようにしてオフ方策学習を実行します.
# 評価対象のアルゴリズムを定義. ここでは, トンプソン抽出方策の性能をオフライン評価する.
# 研究者が独自に実装したバンディット方策を用いることもできる.
evaluation_policy = BernoulliTS(
n_actions=dataset.n_actions,
len_list=dataset.len_list,
is_zozotown_prior=True, # ZOZOTOWN上での挙動を再現
campaign="all",
random_state=12345
)
# シミュレーションを用いて、トンプソン抽出方策による行動選択確率を算出.
action_dist = evaluation_policy.compute_batch_action_dist(
n_sim=100000, n_rounds=bandit_feedback["n_rounds"]
)BernoulliTSのcompute_batch_action_distメソッドは, 与えられたベータ分布のパラメータに基づいた行動選択確率(action_dist)をシミュレーションによって算出します. またユーザは./obp/policy/base.pyに実装されているインターフェースに従うことで独自のバンディットアルゴリズムを実装し, その性能を評価することもできます.
最後のステップは, ログデータを用いてバンディットアルゴリズムの性能をオフライン評価するオフ方策評価です. Open Bandit Pipelineを使うことで, 次のようにオフ方策評価を実装できます.
# IPW推定量を用いてトンプソン抽出方策の性能をオフライン評価する.
# OffPolicyEvaluationクラスには, オフライン評価に用いるログバンディットデータと用いる推定量を渡す(複数設定可).
ope = OffPolicyEvaluation(bandit_feedback=bandit_feedback, ope_estimators=[IPW()])
estimated_policy_value = ope.estimate_policy_values(action_dist=action_dist)
print(estimated_policy_value)
{'ipw': 0.004553...} # 設定されたオフ方策推定量による性能の推定値を含んだ辞書.
# トンプソン抽出方策の性能の推定値とランダム方策の真の性能を比較する.
relative_policy_value_of_bernoulli_ts = estimated_policy_value['ipw'] / bandit_feedback['reward'].mean()
# オフ方策評価によって, トンプソン抽出方策の性能はランダム方策の性能を19.81%上回ると推定された.
print(relative_policy_value_of_bernoulli_ts)
1.198126...obp.ope.BaseOffPolicyEstimator クラスのインターフェースに従うことで, 独自のオフ方策推定量を実装することもできます. これにより新たなオフ方策推定量の推定精度を検証することが可能です.
また, obp.ope.OffPolicyEvaluationのope_estimatorsに複数のオフ方策推定量を設定することで, 複数の推定量による推定値を同時に得ることも可能です. bandit_feedback['reward'].mean() は観測された報酬の経験平均値(オン方策推定)であり, ランダム方策の真の性能を表します.
Open Bandit DatasetやOpen Bandit Pipelineを活用して論文やブログ記事等を執筆された場合, 以下の論文を引用していただくようお願いいたします.
Yuta Saito, Shunsuke Aihara, Megumi Matsutani, Yusuke Narita.
Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation
https://arxiv.org/abs/2008.07146
Bibtex:
@article{saito2020open,
title={Open Bandit Dataset and Pipeline: Towards Realistic and Reproducible Off-Policy Evaluation},
author={Saito, Yuta and Shunsuke, Aihara and Megumi, Matsutani and Yusuke, Narita},
journal={arXiv preprint arXiv:2008.07146},
year={2020}
}
本プロジェクトに関する最新情報は次のGoogle Groupにて随時お知らせしています. ぜひご登録ください: https://groups.google.com/g/open-bandit-project
Open Bandit Pipelineへのどんな貢献も歓迎いたします. プロジェクトに貢献するためのガイドラインは, CONTRIBUTING.mdを参照してください。
このプロジェクトはApache 2.0ライセンスを採用しています. 詳細は, LICENSEを参照してください.
論文やOpen Bandit Dataset, Open Bandit Pipelineに関するご質問は, 次のメールアドレス宛にお願いいたします: saito@hanjuku-kaso.com
論文
-
Alina Beygelzimer and John Langford. The offset tree for learning with partial labels. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery&Data Mining, 129–138, 2009.
-
Olivier Chapelle and Lihong Li. An empirical evaluation of thompson sampling. In Advances in Neural Information Processing Systems, 2249–2257, 2011.
-
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. Unbiased Offline Evaluation of Contextual-bandit-based News Article Recommendation Algorithms. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, 297–306, 2011.
-
Alex Strehl, John Langford, Lihong Li, and Sham M Kakade. Learning from Logged Implicit Exploration Data. In Advances in Neural Information Processing Systems, 2217–2225, 2010.
-
Doina Precup, Richard S. Sutton, and Satinder Singh. Eligibility Traces for Off-Policy Policy Evaluation. In Proceedings of the 17th International Conference on Machine Learning, 759–766. 2000.
-
Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. Doubly Robust Policy Evaluation and Optimization. Statistical Science, 29:485–511, 2014.
-
Adith Swaminathan and Thorsten Joachims. The Self-normalized Estimator for Counterfactual Learning. In Advances in Neural Information Processing Systems, 3231–3239, 2015.
-
Dhruv Kumar Mahajan, Rajeev Rastogi, Charu Tiwari, and Adway Mitra. LogUCB: An Explore-Exploit Algorithm for Comments Recommendation. In Proceedings of the 21st ACM international conference on Information and knowledge management, 6–15. 2012.
-
Lihong Li, Wei Chu, John Langford, Taesup Moon, and Xuanhui Wang. An Unbiased Offline Evaluation of Contextual Bandit Algorithms with Generalized Linear Models. In Journal of Machine Learning Research: Workshop and Conference Proceedings, volume 26, 19–36. 2012.
-
Yu-Xiang Wang, Alekh Agarwal, and Miroslav Dudik. Optimal and Adaptive Off-policy Evaluation in Contextual Bandits. In Proceedings of the 34th International Conference on Machine Learning, 3589–3597. 2017.
-
Mehrdad Farajtabar, Yinlam Chow, and Mohammad Ghavamzadeh. More Robust Doubly Robust Off-policy Evaluation. In Proceedings of the 35th International Conference on Machine Learning, 1447–1456. 2018.
-
Nathan Kallus and Masatoshi Uehara. Intrinsically Efficient, Stable, and Bounded Off-Policy Evaluation for Reinforcement Learning. In Advances in Neural Information Processing Systems. 2019.
-
Yi Su, Lequn Wang, Michele Santacatterina, and Thorsten Joachims. CAB: Continuous Adaptive Blending Estimator for Policy Evaluation and Learning. In Proceedings of the 36th International Conference on Machine Learning, 6005-6014, 2019.
-
Yi Su, Maria Dimakopoulou, Akshay Krishnamurthy, and Miroslav Dudík. Doubly Robust Off-policy Evaluation with Shrinkage. In Proceedings of the 37th International Conference on Machine Learning, 9167-9176, 2020.
-
Nathan Kallus and Angela Zhou. Policy Evaluation and Optimization with Continuous Treatments. In International Conference on Artificial Intelligence and Statistics, 1243–1251. PMLR, 2018.
-
Aman Agarwal, Soumya Basu, Tobias Schnabel, and Thorsten Joachims. Effective Evaluation using Logged Bandit Feedback from Multiple Loggers. In Proceedings of the 23rd ACM SIGKDD international conference on Knowledge discovery and data mining, 687–696, 2017.
-
Nathan Kallus, Yuta Saito, and Masatoshi Uehara. Optimal Off-Policy Evaluation from Multiple Logging Policies. In Proceedings of the 38th International Conference on Machine Learning, 5247-5256, 2021.
-
Shuai Li, Yasin Abbasi-Yadkori, Branislav Kveton, S Muthukrishnan, Vishwa Vinay, and Zheng Wen. Offline Evaluation of Ranking Policies with Click Models. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery&Data Mining, 1685–1694, 2018.
-
James McInerney, Brian Brost, Praveen Chandar, Rishabh Mehrotra, and Benjamin Carterette. Counterfactual Evaluation of Slate Recommendations with Sequential Reward Interactions. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery&Data Mining, 1779–1788, 2020.
-
Yusuke Narita, Shota Yasui, and Kohei Yata. Debiased Off-Policy Evaluation for Recommendation Systems. In Proceedings of the Fifteenth ACM Conference on Recommender Systems, 372-379, 2021.
-
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open Graph Benchmark: Datasets for Machine Learning on Graphs. In Advances in Neural Information Processing Systems. 2020.
-
Noveen Sachdeva, Yi Su, and Thorsten Joachims. Off-policy Bandits with Deficient Support. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 965-975, 2021.
-
Yi Su, Pavithra Srinath, and Akshay Krishnamurthy. Adaptive Estimator Selection for Off-Policy Evaluation. In Proceedings of the 38th International Conference on Machine Learning, 9196-9205, 2021.
-
Haruka Kiyohara, Yuta Saito, Tatsuya Matsuhiro, Yusuke Narita, Nobuyuki Shimizu, Yasuo Yamamoto. Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 487-497, 2022.
-
Yuta Saito and Thorsten Joachims. Off-Policy Evaluation for Large Action Spaces via Embeddings. In Proceedings of the 39th International Conference on Machine Learning, 2022.