Bad performance of stock model on Windows compared to Linux #62387
Comments
|
It seems that on your Windows server you don't have CUDA installed correctly?
|
Correct. The NVIDIA driver seems not to be installed on Windows or too old. Not sure if that could influence CPU-only performance testing though. |
|
Can you try: model = models.resnet18()
device = torch.device("cpu")
model.to(device)This should force the model to use CPU only. |
|
I have rerun updated test snippet on both machines and obtained the very same results. |
|
I guess performance difference stems from a fact that a lot of AVX2 accelerated codepaths are not enabled for Visual C++ compiler, for example see |
For windows you're also testing using |
Is that for a reason? |
I believe at some point intrinsics used in that codebase were not supported by VC++, testing if this still holds true in #62491 |
|
So this is still an issue. |
|
I have tried to reproduce this issue and found this issue only occured on NUMA machine. and it looks like omp does not support NUMA machine well on Windows. My hardware: Windows: Microsoft Windows Server 2022 Datacenter
On my Core I7 - 9750H notebook(32 GB RAM), only one socket. |
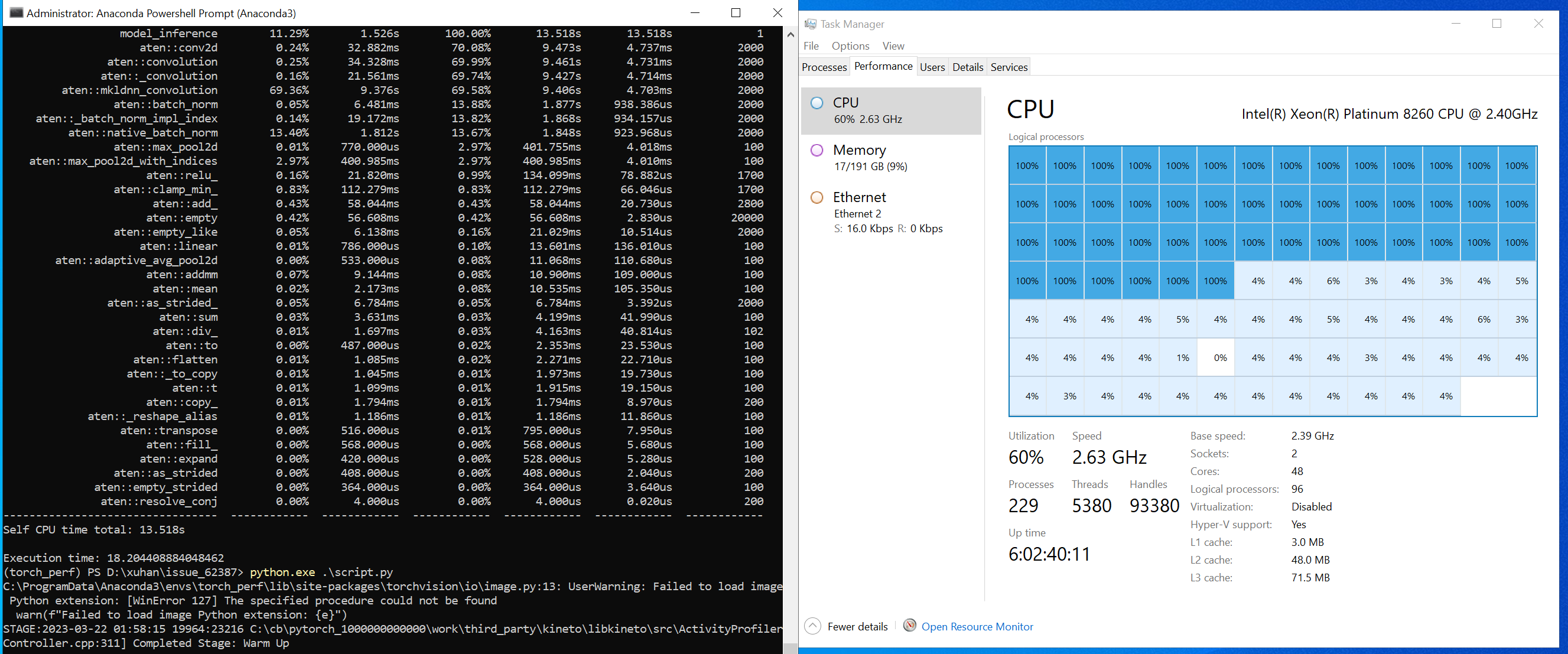
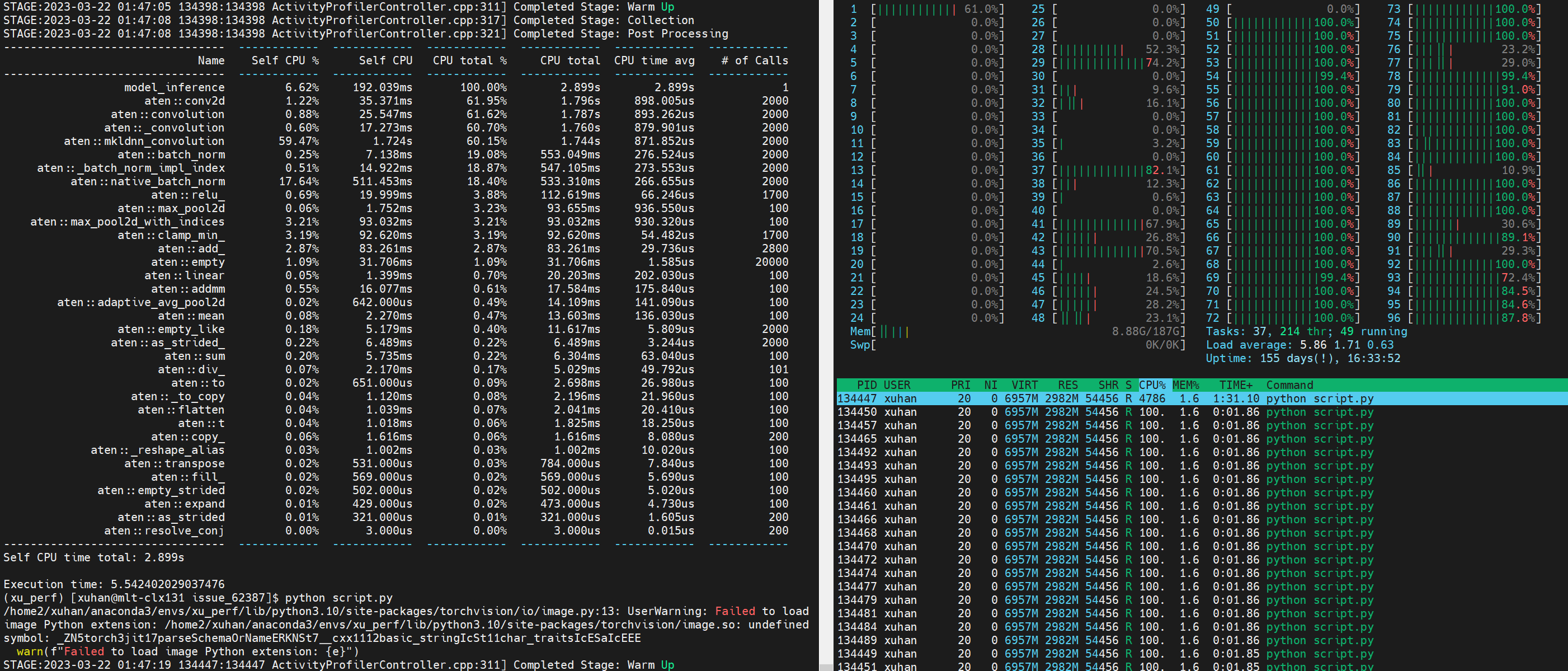
|
In order to double confirm the NUMA impaction on performance gap. I disabled one socket of the server. OS: Linux:
Windows:
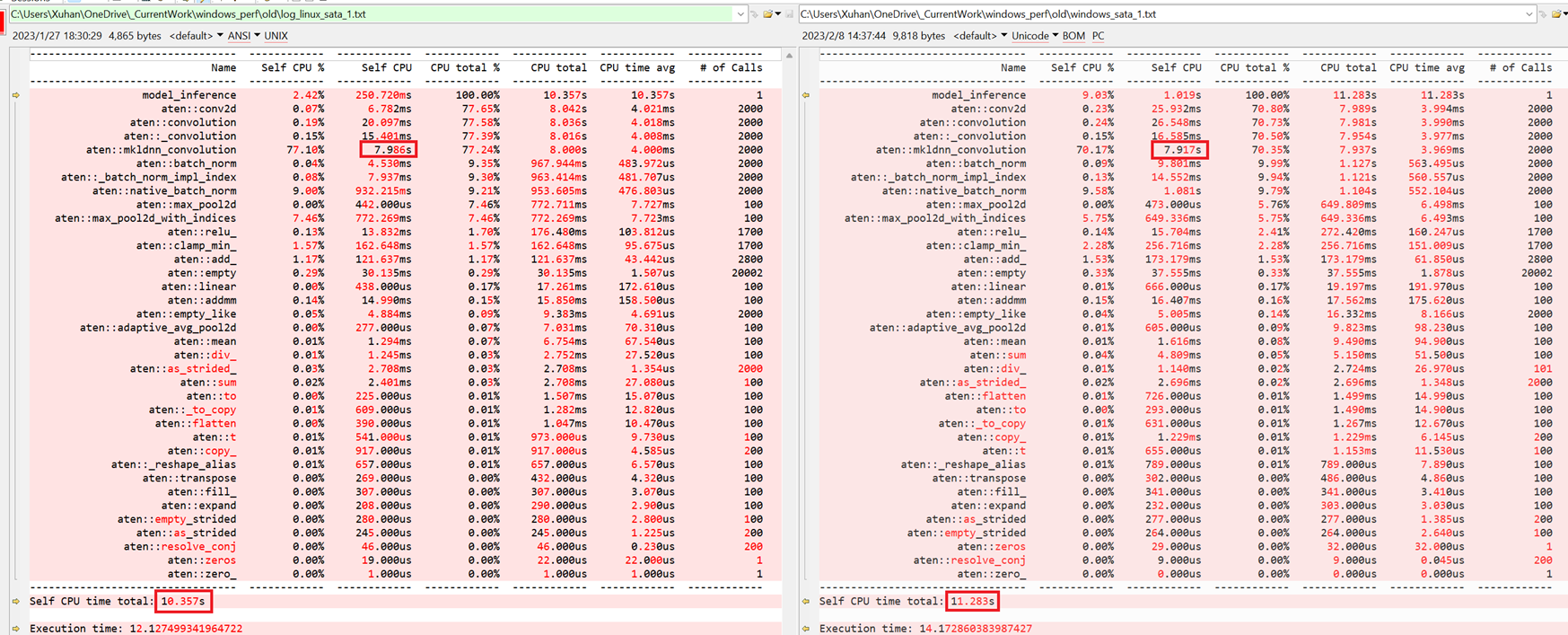
Correct the last post, NUMA is not major reason aten::mkldnn_convolution much slower on Windows than Linux. |
|
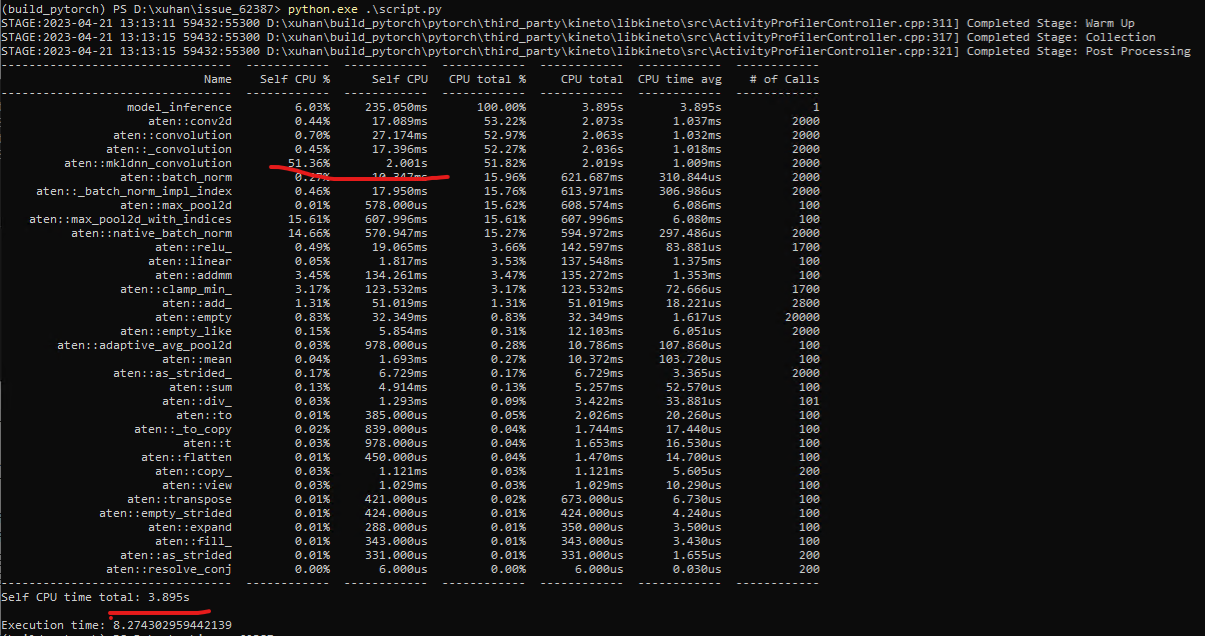
Focus on the aten::mkldnn_convolution, I collected the oneDNN verbose log follow the steps: https://github.com/oneapi-src/oneDNN/blob/master/doc/performance_considerations/verbose.md#enable-onednn_verbose Linux: Windows: Breakdown logs show that, each prim_kind and shapes on Windows are slower than on Linux. |
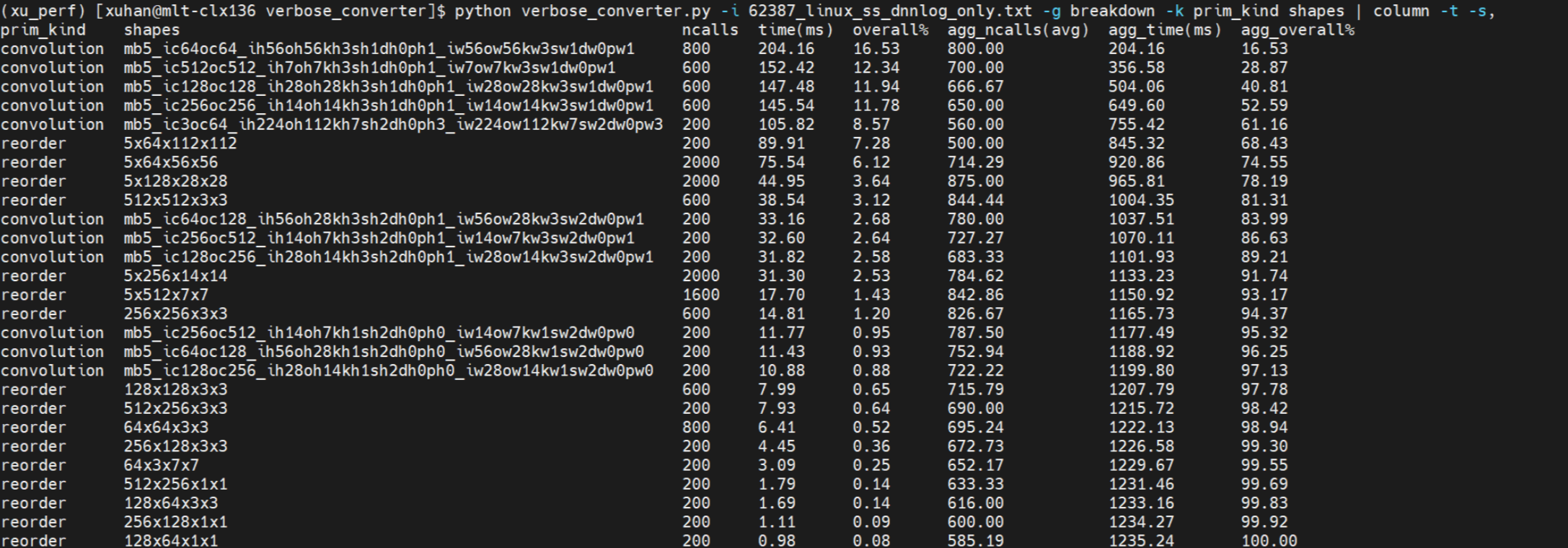
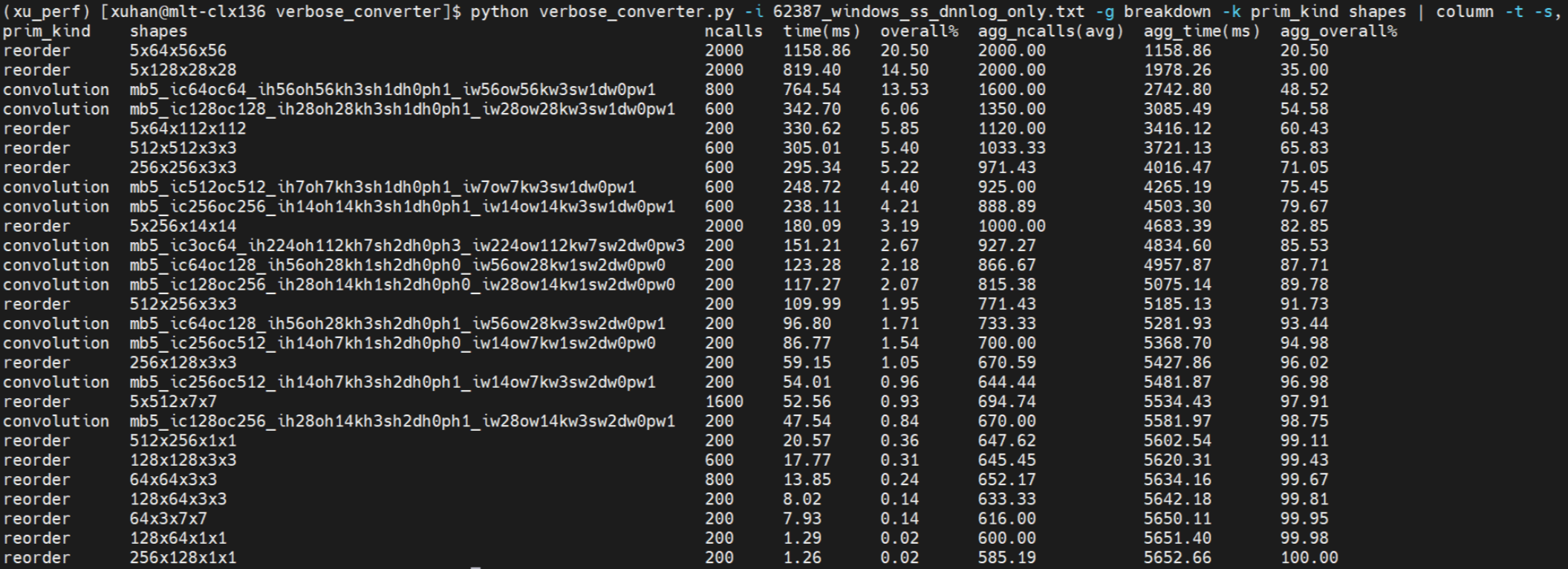
|
Continued. From the breakdown logs. We can find that, pytorch do everything on Windows are slower than on Linux. I guess Windows's memory performance maybe worse than Linux's. In order to poorf my guess, I wrote a simple benchmark to measure it. bench_malloc
Bench_malloc is open source, and can build via cmake on both Windows and Linux. You can clone and measure it on your machine. Another bench_malloc data on single socket Xeon server. |

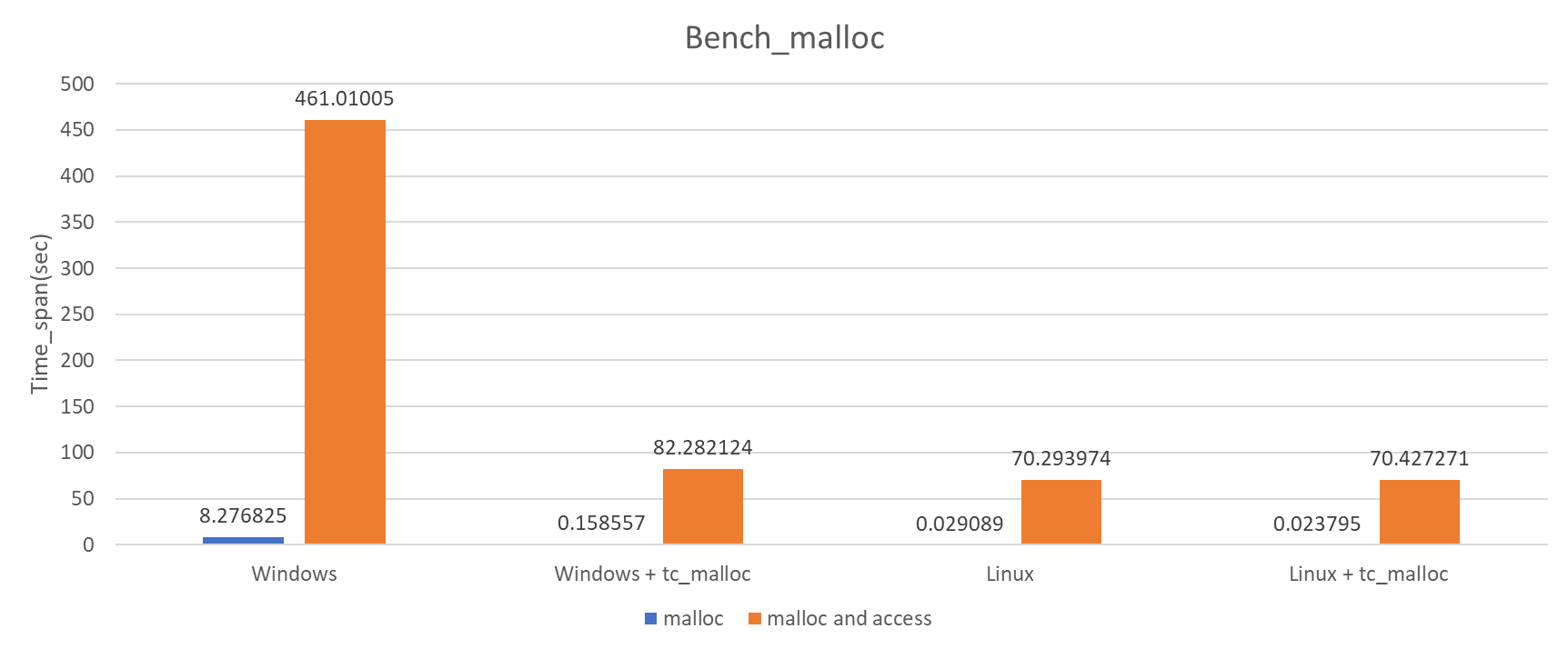
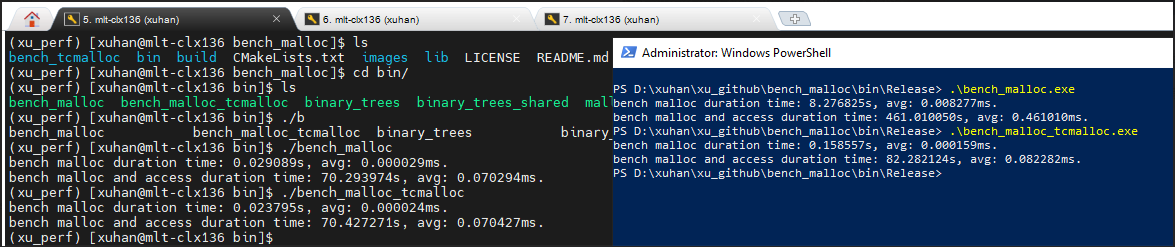
|
Continued. From bench_malloc result, Windows system malloc is bad performance. But tc_malloc is much better performance than system malloc. whether we can replace the system malloc to tc_malloc to improve performance? I made a POC to replace pytorch C10 alloc_cpu/free_cpu to tc_malloc. example PR: https://github.com/xuhancn/pytorch/pull/2/files After malloc replacement, the performance data shows as below: To embedded tc_malloc I forked & modified offical tc_malloc code. My forked repo: https://github.com/xuhancn/gperftools
|

|
Is this somewhat mitigated by reusing a memory cache? I assume the effect is less pronounced |
|
I tried to intgrate mimalloc into pytorch, and found mimalloc performance can't competing to tc_malloc. @peterjc123 |
@xuhancn Does setting those environment variables help? See also microsoft/mimalloc#633 (comment) |
|
I made a summary of malloc libraries.
|

I think envirment variable optimition is not friendly to end users. Let's considering tc_malloc firstly. |
|
#102534 (comment) mimalloc enabled. |
#118980 Enabled SIMD by this PR. |
🐛 Bug
We have got two identical two-socket servers on Intel Xeon E5-2650v4 with 256 GB RAM, one running Ubuntu and the other running Windows Server 2012. There is a severe degradation of a model perfomance when using Windows compared to Linux (about 2-4 times).
To Reproduce
Steps to reproduce the behavior:
Output on the Linux server
Output on the Windows server
Expected behavior
Execution times should well match with some tolerance maybe.
Environment
Output of collect_env.py on the Linux server
Output of collect_env.py on the Windows server
Additional context
Both servers are equipped with two Intel Xeon E5-2650v4 (which gives 48 threads total) with 256 GB RAM and are idle.
cc @VitalyFedyunin @ngimel @heitorschueroff @fmassa @vfdev-5 @pmeier @peterjc123 @mszhanyi @skyline75489 @nbcsm
The text was updated successfully, but these errors were encountered: