Add support for incremental parsers #507
Comments
|
I'm assuming you want support for parsing from an index other then 0, yes? |
|
No actually, just support for modifying the location that is reported in the location() object. The parser I am writing, parses a chunk of data at a time (i.e. node streams) and parses as much as it can. so given the following document <root> and suppose it comes in in two chunks 1: 2: during the first parse it would parse <root> but the next parse it would parse During the second parse I want it to reflect the location in the original document not the chunk it has been presented. |
|
Sorry, just trying to understand what you want here 😄 Basically you want the location data to reflect whats passed via the options rather then from the starting index used by the internal parser functions? Wouldn't this return incorrect location data for what was parsed in the first parse (i.e "te" from "text")? Since your parsing chunks of data at a time, wouldn't it be more optimal to just return the range: function range() {
return [ peg$savedPos, peg$currPos ];
/* or */
//return { start: peg$savedPos, end: peg$currPos };
} |
|
The parser never has access to the whole document at once, only one chunk at a time, since it doesn't have access to the whole document, the location() function as it stands does not give very relevant information. in the preceding example the first chunk, would have the correct location info, the second chunk would be very incorrect. the string "te" would be prepended to the second chunk and would be recocognized as the full string "text". Without changes to the location function, the start of string "text" would be recognized as offset 0, line 1, column 1, instead of the correct values of offset 13, line 2 column 8 This would also be useful if say you only wanted to parse part of a document. |
Like I asked above, basically you want the location data to reflect whats passed via the options rather then from the starting index used by the internal parser functions, which as you showed above, can be achieved by overwriting peg$posDetailsCache and peg$computeLocation. Currently the parser's generated by PEG.js don't keep their state between different parsing sessions, so there is no way to do what you want automatically, so manually overwriting peg$posDetailsCache and peg$computeLocation is the only way.
This can be a different issue depending on the source input given to the generated parser:
|
|
Have decided to implement this before v1, but will need to think of a concrete direction to take based on the OP's request and my post above. |
|
This basically isn't possible. Unfortunately the current maintainer is researching impossible promises instead of fixing easy things users actually need. The way a packrat parser works is the parsing equivalent of A* - it caches its old matching attempts. The reason it's able to match so liberally is that it has all the forward stems, which prior to caching seemed performance unrealistic. That's also why it's so fast. The problem is, in order to do incremental parsing, you'd either need a copy of the old cache, which is typically thousands to hundreds of thousands of times the size of the document, or to keep the forward piece of the old document and just re-parse it. This issue should be closed as not possible. This isn't how packrats work. (Also, they're fast enough that I can't think of a reason this would be necessary or desirable. I can usually parse ~10 meg documents in under a single screen frame.) Most likely it's faster to re-parse from scratch than it would be to load the old stems from disk Just track your location in the first parse and re-seek there in the second, with a unique XPath. XML has no deletion. It's guaranteed that the stream position you were at is still there. |
|
There is something called an incremental packrat parser, and there are even openly available javascript implementations by the Ohm people But if you get down to the nitty gritty and look, you'll realize that they're about as related as a hashmap and a vector (because one's a sparse array and one's a dense array, and the only things they really share are words in the title) |
I don't think so. Yes, there are grammars for which incremental parsing will give nothing, but there are also those for which it can be done. The problem is to divide these classes and report it at the compile stage so as not to generate non-working code |
|
You know this software better than I do, and I could be wrong, and if you're certain I'll shut up, but Do you really believe that |
|
Like, the |
I had some ideas in the past, but as project is dead I never implemented them... It's just a challenge, but at this point I don't need that functionality, but to do something nobody needs -- boring |
|
This project isn't dead. It has 200,000 downloads a week. It just needs a maintainer who cares. I'd love to resurrect this and start fixing the problems. I'll just go through the existing worklog, cherry pick, add tests, and release. I'm fixing my peg grammars with bash scripts. There's no reason this project should die. It's the best JS parser out there. |
|
I understand. Maybe the best option to make a fork and develop it according to your requirements |
|
I did that three years ago. No, I'm not going to fork a library in order to take it away from its current maintainers, and bring it back to life. That's not what forks are, or how they work. My explicit goal is to remove the team that spent three years making As I understand it, that team is ryuu. This is an extremely important library that is heavily used by many packages system-wide. It's time for someone to bring it back to a healthy status. Forking it will not achieve that goal. My goal is to fork There are six different issues in this repo that say "I've given up on peg because it hasn't released in years," or "because it hasn't released since David left." Nobody cares about my fork. If I forked it, nothing would be saved. I'm going to save the real thing now, if David lets me. I'm sorry that you want me to let the real thing die, but I'm not willing to do that. I also don't know why you'd want that. Your PRs are dying with At any rate, I wasn't asking for advice. I already told David what I want, and I still want it even if you want me to pull a Ryuu, and start over in a different repo that nobody can see or will ever care about, and continue leaving the users stranded. My goal isn't to save myself. My goal is to save the library. It's time for the current developers to let someone with library experience step in and create a healthy develop and release process, and save the library. Your opinion of my desire is noted. I still want David to let me undo the three years of damage that have been done since he left, by a group who accepted the responsibility of maintenance, then never actually did it. The current maintainer has literally never maintained the library a single time, and every single promise he made to David back in 2017 to acquire this repo is faulted. It was time to let go in 2018 I want David to let me fix this. Peg is the best parser around Its own developers (you) are saying "I gave up on this project, it's dead" Why you also want me to not save it and work on my own private fork, when all the developers have given up on the project as a dead project, is beyond me I'm sorry you've given up on I have not. |
I just leaved they in my fork. They don't died completely, you still can resurrect them. I'm just not interested in doing that.
I have been fitting the implementation of ranges for 5 years to all the changing formatting requirements, added 3 new features during evolving initial PR (delimiters, variable boundaries, function boundaries), but it was so not even seen by anyone in the community. This suggests that there is actually no community. In fact, outside in my face was said that I am not a community and my opinion doesn't matter, though there were no others. So I think "the community" will quite cost without your sacrifice :(
Only fork, IMHO. Sad, but true. Maybe an example of io.js will teach something.
Why private? Make a public fork, do good things and community (if it exist) will found you |
I'm here to save the library, not make a new one. Please stop asking me for this now. I've been clear that the answer is no. .
I know. If I'm made maintainer, ranges will go in using your code in 2020. These problems come from the lack of a maintainer. Forking won't fix them; it'll make them worse. .
There used to be. There can be again. I started filing tickets less than 24 hours ago and I've already had conversations with nine people. Quit being fatalist. This is easily fixable. All that needs to happen is the keys need to be put in the hands of an experienced maintainer who has a focus on releases. .
I'm not making a sacrifice here. .
I saw that for the first time yesterday night, when I started reading through the issue tracker. (I'm going to read the whole thing, open and closed.) I also saw #209. I am sympathetic to both positions here. On the one hand, this is a feature that really ought to go in, that a lot of people want, that other libraries support, and that the underlying tools are ready to support. On the other hand, the conversation wasn't actually finished. If I was allowed to be maintainer, here's what I would do:
.
Hi, you've pushed that opinion four times now, and I've said no every time. Stop telling me your opinion of my goal. My goal isn't changing. .
Because I did it three years ago, when this was still a healthy library, and the changes I was making were things @dmajda had said no to. So I figured I'd fix it locally, and when the community fixed it properly, I'd convert my grammar. Three years later, the developers have given up on this project as dead, but are also trying their very hardest to get me to not fix that even after I've clearly told them to stop, which is bewildering and inappropriate. If you make any more comments about my needing to make a fork, I will simply cease to respond. I have no interest in your hope of keeping The answer is a hard no. If you want Everything you merged into Ryuu has also started three other PEG compilers since he took over maintenance This library only died because
Hi, I'm one of the old developers, and I'm angry If you're not willing to help save this library, at least stop telling me not to. This library needs to be maintained. It's a critical piece of infrastructure. A fork isn't maintenance. A fork doesn't solve any of the problems. .
Yes, |
|
I 'm not trying to dissuade you. If you do, I will only be happy and may even complete some of my experiments and bring them to mergeble state. Just looking in the past, somehow I can't believe. Criticality is strongly exaggerated. If it were as you say, someone would have already made a fork and developed it. Or this library developed rather than frozen in development for 5 years. |
That would be fantastic. Many of your PRs seem really powerful to me, and with some added testing, it seems to me like they should be merged .
The current maintainer alone has made three or four distinct forks (pegx, epeg, meg; arguably pegjs-dev, since he did that on his own before he was a maintainer) as well as an openpeg fork. At this point I would argue that In my last 48 hours, I've talked to about ten people in here. Half of them have forks. polkovnikov-ph has an entire meta-peg that puts pegs into other pegs. I have two forks myself, one which doesn't show in the fork list - the contrarian one I've maintained for years, and the new one I made the other day, before I learned Two of my friends who have not, as far as I can tell, ever been in this issue tracker have forks That people have kept working on .
This library was in fact actively developed until May 2017, when the maintainer change happened. That day was the day the library froze. That's why I believe a new maintainer change can un-freeze it. |
|
I would say that until then there had been code shuffling, but no new features implemented. Maybe a couple of bugs fixed, and that, they had to be fought back. Actual development froze much earlier than @dmajda left |
|
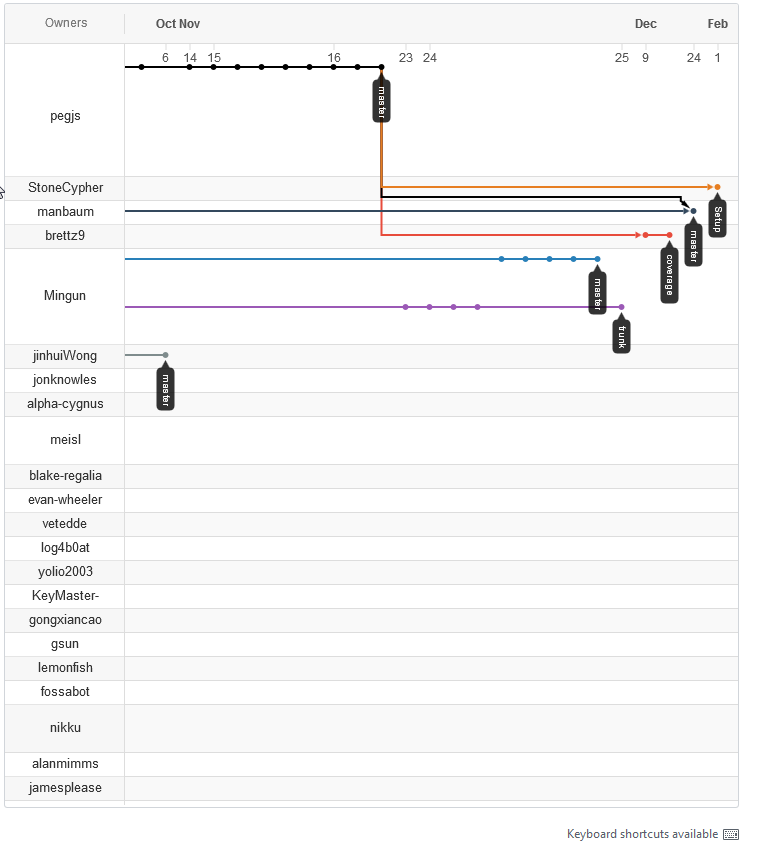
You know what I see there? I see a library that's been unmaintained for three years and still has six active forks over the last couple months. Anyway, look, paint the line wherever you want in the sand. Maybe there's a better place to draw it; I haven't gone on an archaeological dig. The point is, it's still a line in the sand. Let's just use our feet to fuck the sand up now.
This is the best parser out there after half a decade of inactivity. Do you realize how great it would become if it became an open source accessable project? Let's make a clean Lots of these are super difficult, sure But lots of them aren't. I get ES6 module support from a one-line bash script. That's silly and easily fixed |
|
Forwards movement doesn't have to be perfect; it just has to be non-trivial Help me get David onboard? Please |
|
Like seriously. Imagine what would happen if And then what if the next week, es module support came out And what if the following week, the webpage got a major update And what if the following week, we released simple typescript support Those are all things I've already done. Those are all like two hour jobs. That's a relaxed and easy cadence But it's so different than what users are used to that it would make clear that something has changed I am quite confident that this library has the user community and defect base to get to meaningful sub-monthly releases, and I am quite confident that I could make that happen |
|
I've got my own fork as well, a single file, zero dependency implementation based on the original academic paper. I had originally tried using the 0.10.0 codebase, but even that was too bloated for my tastes. My feeling is that anyone to whom this is mission critical has already forked because dealing with "open source" drama is more draining than spending a couple weekends learning and implementing a solution to one's specific needs. Seriously, the paper is an easy read and in <100 hours I was able to get a parser that was 4x faster and 100x smaller. There's always the fundamental tradeoff between wanting to use an existing solution and having a perfect match for your own problem. Parser communities are in a difficult valley where once someone has learned enough to use a parsing tool effectively its just a small amount of additional work to write their own entire parser. The biggest opportunity cost of open source is spiritual. Namaste 🙏 P.S. Don't get me wrong, I'm really enjoying these threads, it's great entertainment! I just don't expect much productive value from GH or JS communities these days. |
|
It's an understandable viewpoint. Given the current status of things, I'm hoping I can get people to say "well, let an attempt happen and let's see" |
|
@StoneCypher I like your energy that you seem to want to put into this lib and I agree with your general ideas (and I already would have after the first time you wrote them - no need to say the same thing five times 😁). I also don't like a fork very much, but that means we are dependent on exactly one person - futagoza. What if he doesn't respond? Then we are stuck, nothing we can do about that. dmajda already said he has no rights anymore, so nothing he can do either. Here is the thing I don't agree with: "in a different repo that nobody can see or will ever care about" because that has a simple solution: open a new issue in all caps saying something like "PROJECT DEAD - CONTINUED HERE" and then write all the necessary information there. I would be the first person to switch my project over, and I am sure many others would. And this would not be the first project this happened to, I have already followed a few other projects down that route. No big deal, just switch. As a user, I don't really care where I get my code from as long as it's a place people care about. So I would give @futagoza a couple more weeks to see if he responds and what his opinion is. If there is no sign of life and no response, go ahead and recreate this project properly. |
|
Actually, I just saw that @michel-kraemer is also a member of pegjs, so maybe there even more hope 😀 |
|
@michael-brade - Forks don't work. I'm going to be very direct: I do not want you to tell me to do something different again There are already four forks attempting to save this repo. You don't know what they are. You aren't looking for them when saying "fix it that way." It doesn't matter. A fork won't fix anything. Existing downstream consumers do not receive bugfixes in a fork. PRs are lost in a fork. Issues are lost in a fork. The answer is a hard no. @futagoza must stop blocking peg immediately. |
|
This library will not die because someone promised to be a maintainer, refused to maintain, and decided to keep it for themselves. Morally, @futagoza has no right to promise to be a maintainer, then destroy the library. |
How do you know that they are? Do you have any links? The only kind of active fork I see is meisl/pegjs, none of the others is active at all. And even the meisl fork doesn't look like it's an attempt to save this repo.
Maybe you didn't read my suggestion: if those forks did intend to save this repo, then they did it wrong because they did not create an obvious issue telling the community where to go. I agree with everything you say until this marker has been created. Then the rules change.
Right. And how do you intend to enforce that? |
Because I went looking for bugfixes, years ago. .
Yes. However, if forks worked, I wouldn't have to give them; you'd have them too. This is my explanation of why I will not consider a fork, or entertain any further wasted time mollycoddling the fake maintainer .
Actually, they did. It was deleted. In one sense, you are right: they did it wrong, by creating a fork. Most people get libraries from I am being radically clear when I say "I do not want to have any further discussions about forks." Further attempts to discuss this will be ignored. .
It has been, several times. |
Ok, I have no way to check this. But assuming you are right, then it should be obvious to you that the person who deleted this issue has no intention to give up power over this repo. Under those circumstances, how is it that you think you can change anything without a fork? All I can say is I wish you luck. And that I will follow to wherever active development takes place. |
Because eventually futagoza will come back, and he'll have to make this decision again. Those were in 2018. It's 2020. He's started at least four entirely distinct PEG parsers since, one in a different base language, as well as two programming languages. Back then, he hadn't thrown away three years of work as not trustworthy. Now he has. Back then, he was only six months into it. That's still a "well give me a chance" timeline, barely. Now it's three years. Back then, he could still say he was committed to this, and that this was his focus. Things have changed. |
I am building a streaming XML parser and I had rough time getting location information due to the nature of the parser.
Here is what I did to make it work,
I added the following 2 sections to my initializer
Then after each parse (which consumes one item only) outside of the pegjs grammar, I update options.offset with the ending offset, and options.peg$posDetailsCache with an object like so [{line: 4, col: 5}]
it would be nice if the parser supported passing in the starting offset and the starting line number and column, to better support incremental parsing.
Related: #281 Allow an option to specify a start offset
The text was updated successfully, but these errors were encountered: