January 2021
tl;dr: Train inception-style, inference 3x3 only. Very deployment-friendly.
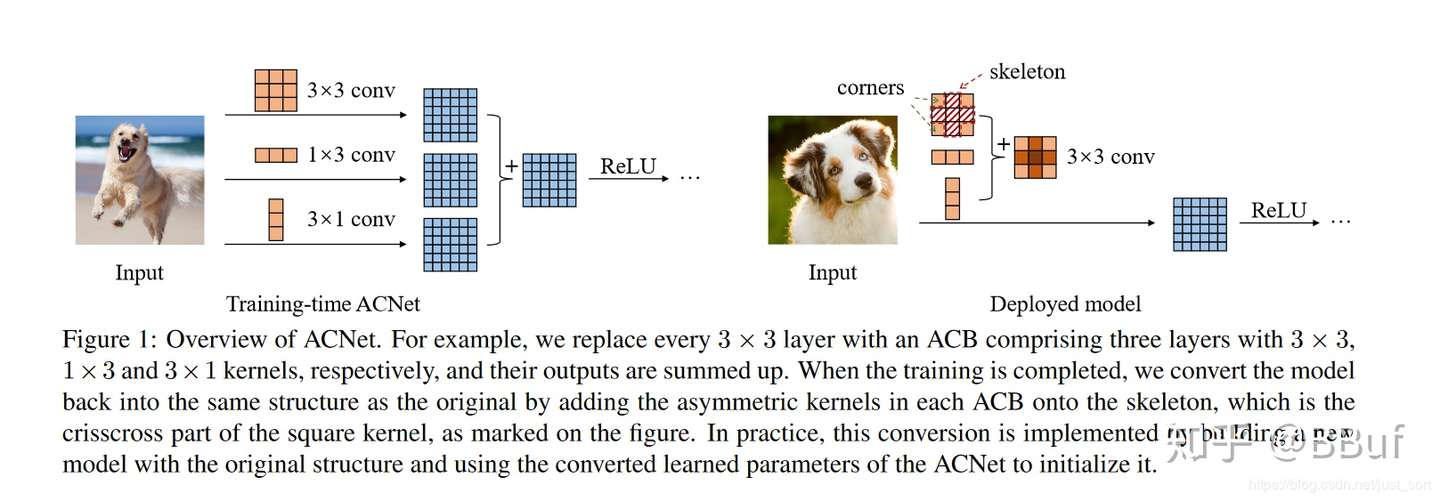
From the authors of ACNet.
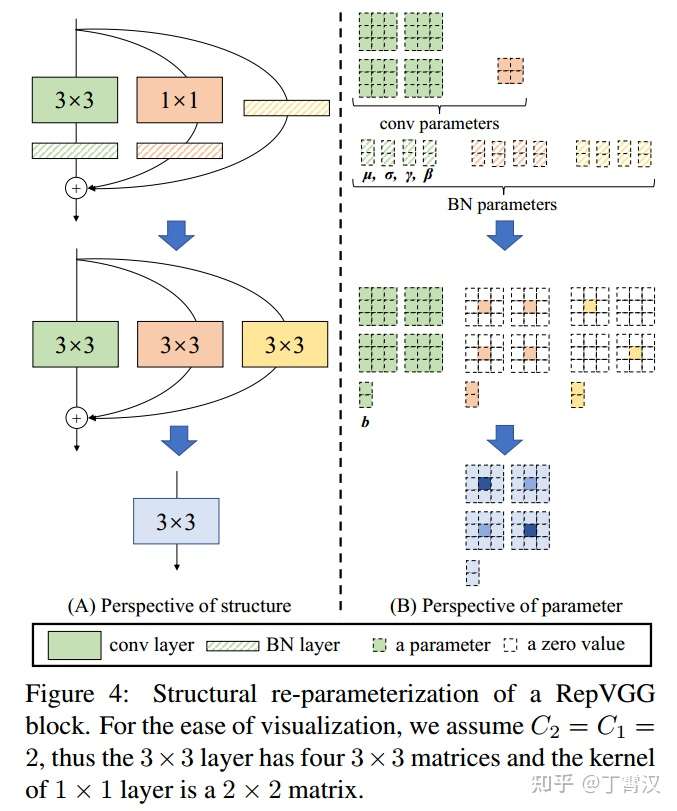
The paper introduces a simple algebraic transformation to re-parameterization technique to transform a multi-branch topology into a stack of 3x3 conv and ReLUs.
Depthwise conv and channel shuffle increase the memory access cost and lack support of various devices. The amount of FLOPs does not accurately reflect the actual speed.
The structural reparameterization reminds me of the inflated 3D conv I3D initiated from 2d convs.
This seems to be an architecture very friendly to be deployed on embedded device.
- Training has three branches: 3x3, 1x1 and shortcut
- Reparam:
- identity branch can be regarded as a degraded 1x1 conv
- 1x1 can be further regarded as a degraded 3x3 conv
- all 3 branches can be consolidated into a single 3x3 kernel.
- First layer of every stage is 3x3 conv with stride=2. No maxpooling in RepVGG architecture.
-
Nvidia cuDNN and Intel MKL (math kernel lib) have accelerations for 3x3 kernels (usually to 4/9 of the original cost) through the Winograd algorithm.
-
ResNet architecture limits the flexibility
- Limits the tensor shapes due to skip connection
- Limits channel pruning
-
RepVgg is a special type of ACNet.