May 2023
tl;dr: Formulate object detection as a language modeling task.
The overall intuition is that if a neural network knows about where and what the objects are, we just need to teach it how to read them out (茶壶里往外倒饺子). Pix2seq formulates object detection as a language modeling task conditioned on the observed pixel inputs.
Classic object detection methods (including DETR) explicitly integrate prior knowledge about the object detection task, especially handcraft delicate network architecture and loss functions.
It has zero inductive bias/prior knowledge of object detection. True end-to-end, as compared to ViT and DETR. Prior knowledge helps with convergence (cf DETR and its successors), but may hurt performance ceiling.
The underlying methodology of Language modeling has been shown capable of modeling various sequential data. Pix2seq enriches this portfolio and shows that it works for even non-sequential data by turning a set of objects into a sequence of tokens. And the order does not matter with random ordering working best.
Follow-up work is pix2seq v2, Unified-IO and UniTab. The author also created the self-supervised learning scheme of SimCLR.
- Tokenization: Pix2seq propose a quantization and serialization scheme that converts bboxes and class labels into sequences of discrete tokens, unifying them into a common vocabulary. Each object is represented by five discrete tokens (ymin, xmin, ymax, xmax, c), with a shared vocabulary for all tokens. Coordinates are quantized to [1, n_bin], and thus vocab size is n_bin + n_class.
- For object detection, n_bin is chosen as 2000 (500 is enough per ablation), much smaller than NLP n_vocab, typically 32K or higher.
- Sequence construction
- Random ordering yields the best results, better than multiple hand-crafted, deterministic ordering strategy (order by area, distance to origin, etc).
- The authors hypothesizes that with deterministic ordering, the model is hard to recover from mistakes of missing objects made early on. --> This is also mentioned in Andrej's state of GPT talk, which can be mitigated by ToT (tree of thought), essentially building a system 2 with a lot of sampling from system 1.
- This sequence can be treated as one "dialect", a constructed object detection language.
- Architecture
- Encoder and decoder. Encoder part can still be a CNN-based network.
- Decoder generates target sequence, one token at a time, conditioned on the preceding tokens and the encoded image representation.
- This removes the complexity and customization in architecture of modern object detectors, e.g. bboxes proposal and regression, since tokens are generated from a single vocabulary, with a softmax.
- Seq augmentation
- model tends to finish without prediction all objects.
- One trick is to delay sampling of EOS (by likelihood offsetting)
- Seq augmentation appends noisy (synthetic) tokens after real tokens (with
noiseclass label), and the model is trained to learn to identify the noisy tokens. - Seq augmentation mainly effective during finetuning stage rather than pretraining.
- By delaying sampling EOS, model can use more tokens to "think". This is similar to System 2 as mentioned in Andrej's state of GPT talk.
- The model is asked to predict to. max length yield a fixed-sized list of objects. 100 objects per image, a sequence length of 500.
- Training is done with standard next-token prediction loss, with teacher-forcing procedure (open loop). During inference, it is closed loop and generates results autoregressively.
- Real-time performance: Can do early stopping to mitigate.
- Nucleus sampling, aka top p sampling is better than argmax sampling (when p=0, nucleus sampling degenerates to argmax).
- Visualization of decoder's cross attention map reveals that, the attention is very diverse when predicting the first coordinate token (ymin) but then quickly concentrates and fixates on the objects.
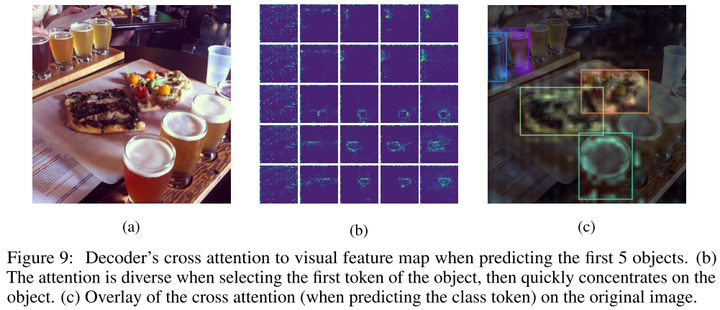
- There seems to be a list of follow-up work on pix2seq from Google Research, such as [Pix2seq v2: A Unified Sequence Interface for Vision Tasks)(https://arxiv.org/abs/2206.07669).