Object-Contextual Representations for Semantic Segmentation
Official Repo
Code Snippet
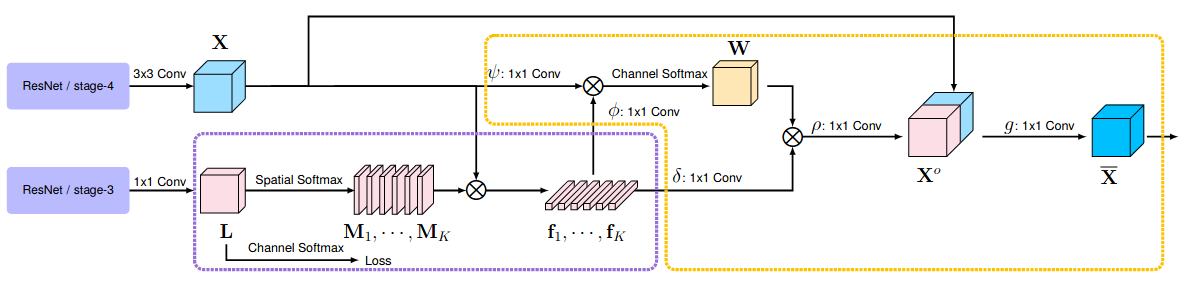
In this paper, we address the problem of semantic segmentation and focus on the context aggregation strategy for robust segmentation. Our motivation is that the label of a pixel is the category of the object that the pixel belongs to. We present a simple yet effective approach, object-contextual representations, characterizing a pixel by exploiting the representation of the corresponding object class. First, we construct object regions based on a feature map supervised by the ground-truth segmentation, and then compute the object region representations. Second, we compute the representation similarity between each pixel and each object region, and augment the representation of each pixel with an object contextual representation, which is a weighted aggregation of all the object region representations according to their similarities with the pixel. We empirically demonstrate that the proposed approach achieves competitive performance on six challenging semantic segmentation benchmarks: Cityscapes, ADE20K, LIP, PASCAL VOC 2012, PASCAL-Context and COCO-Stuff. Notably, we achieved the \nth{2} place on the Cityscapes leader-board with a single model.
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| OCRNet |
HRNetV2p-W18-Small |
512x1024 |
40000 |
3.5 |
10.45 |
A100 |
76.61 |
78.01 |
config |
model | log |
| OCRNet |
HRNetV2p-W18 |
512x1024 |
40000 |
4.7 |
7.50 |
V100 |
77.72 |
79.49 |
config |
model | log |
| OCRNet |
HRNetV2p-W48 |
512x1024 |
40000 |
8 |
4.22 |
V100 |
80.58 |
81.79 |
config |
model | log |
| OCRNet |
HRNetV2p-W18-Small |
512x1024 |
80000 |
- |
- |
V100 |
77.16 |
78.66 |
config |
model | log |
| OCRNet |
HRNetV2p-W18 |
512x1024 |
80000 |
- |
- |
V100 |
78.57 |
80.46 |
config |
model | log |
| OCRNet |
HRNetV2p-W48 |
512x1024 |
80000 |
- |
- |
V100 |
80.70 |
81.87 |
config |
model | log |
| OCRNet |
HRNetV2p-W18-Small |
512x1024 |
160000 |
- |
- |
V100 |
78.45 |
79.97 |
config |
model | log |
| OCRNet |
HRNetV2p-W18 |
512x1024 |
160000 |
- |
- |
V100 |
79.47 |
80.91 |
config |
model | log |
| OCRNet |
HRNetV2p-W48 |
512x1024 |
160000 |
- |
- |
V100 |
81.35 |
82.70 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Batch Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| OCRNet |
R-101-D8 |
512x1024 |
8 |
40000 |
- |
- |
V100 |
80.09 |
- |
config |
model | log |
| OCRNet |
R-101-D8 |
512x1024 |
16 |
40000 |
8.8 |
3.02 |
V100 |
80.30 |
- |
config |
model | log |
| OCRNet |
R-101-D8 |
512x1024 |
16 |
80000 |
8.8 |
3.02 |
V100 |
80.81 |
- |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| OCRNet |
HRNetV2p-W18-Small |
512x512 |
80000 |
6.7 |
28.98 |
V100 |
35.06 |
35.80 |
config |
model | log |
| OCRNet |
HRNetV2p-W18 |
512x512 |
80000 |
7.9 |
18.93 |
V100 |
37.79 |
39.16 |
config |
model | log |
| OCRNet |
HRNetV2p-W48 |
512x512 |
80000 |
11.2 |
16.99 |
V100 |
43.00 |
44.30 |
config |
model | log |
| OCRNet |
HRNetV2p-W18-Small |
512x512 |
160000 |
- |
- |
V100 |
37.19 |
38.40 |
config |
model | log |
| OCRNet |
HRNetV2p-W18 |
512x512 |
160000 |
- |
- |
V100 |
39.32 |
40.80 |
config |
model | log |
| OCRNet |
HRNetV2p-W48 |
512x512 |
160000 |
- |
- |
V100 |
43.25 |
44.88 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| OCRNet |
HRNetV2p-W18-Small |
512x512 |
20000 |
3.5 |
31.55 |
V100 |
71.70 |
73.84 |
config |
model | log |
| OCRNet |
HRNetV2p-W18 |
512x512 |
20000 |
4.7 |
19.91 |
V100 |
74.75 |
77.11 |
config |
model | log |
| OCRNet |
HRNetV2p-W48 |
512x512 |
20000 |
8.1 |
17.83 |
V100 |
77.72 |
79.87 |
config |
model | log |
| OCRNet |
HRNetV2p-W18-Small |
512x512 |
40000 |
- |
- |
V100 |
72.76 |
74.60 |
config |
model | log |
| OCRNet |
HRNetV2p-W18 |
512x512 |
40000 |
- |
- |
V100 |
74.98 |
77.40 |
config |
model | log |
| OCRNet |
HRNetV2p-W48 |
512x512 |
40000 |
- |
- |
V100 |
77.14 |
79.71 |
config |
model | log |
@article{YuanW18,
title={Ocnet: Object context network for scene parsing},
author={Yuhui Yuan and Jingdong Wang},
booktitle={arXiv preprint arXiv:1809.00916},
year={2018}
}
@article{YuanCW20,
title={Object-Contextual Representations for Semantic Segmentation},
author={Yuhui Yuan and Xilin Chen and Jingdong Wang},
booktitle={ECCV},
year={2020}
}