The OAAX Standard initiative is currently work in progress. Please join the conversation and help democratize edge AI at https://oaax.org.

This repository, and other linked repositories under the OAAX-standard organization, contain documentation and reference implementations, as well as contributed implementations, of the Open AI Accelerator eXchange (OAAX) Standard.
The Open AI Accelerator eXchange (OAAX) Standard intends to provide a easy-to-use, easy-to-expand, standardized method of adopting (edge) AI accelerators such as NPUs, GPUs, FPUs or the like -- we will call them XPUs" throughout -- into edge AI applications. An AI application or pipeline consists of several operations that take one specific form of data as input, and transform this data into a more meaningful format.
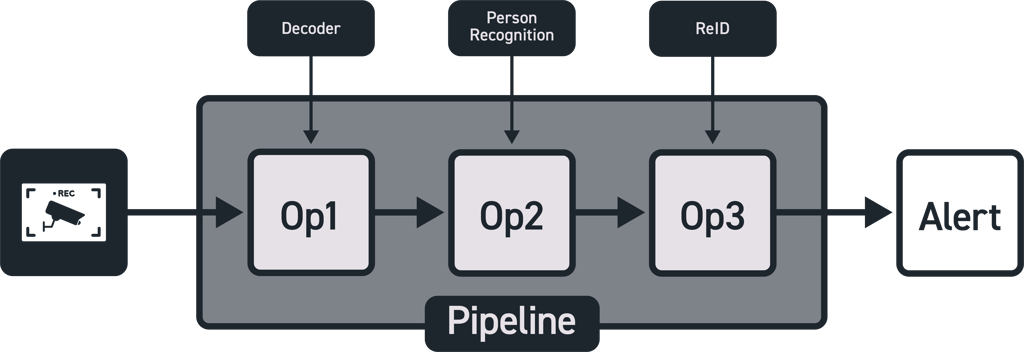
The OAAX standard is designed to make it easy to take a trained AI model and use it to run inference on any novel (
edge) AI accelerator instead of running it on a CPU, as demonstrated in the figure below.
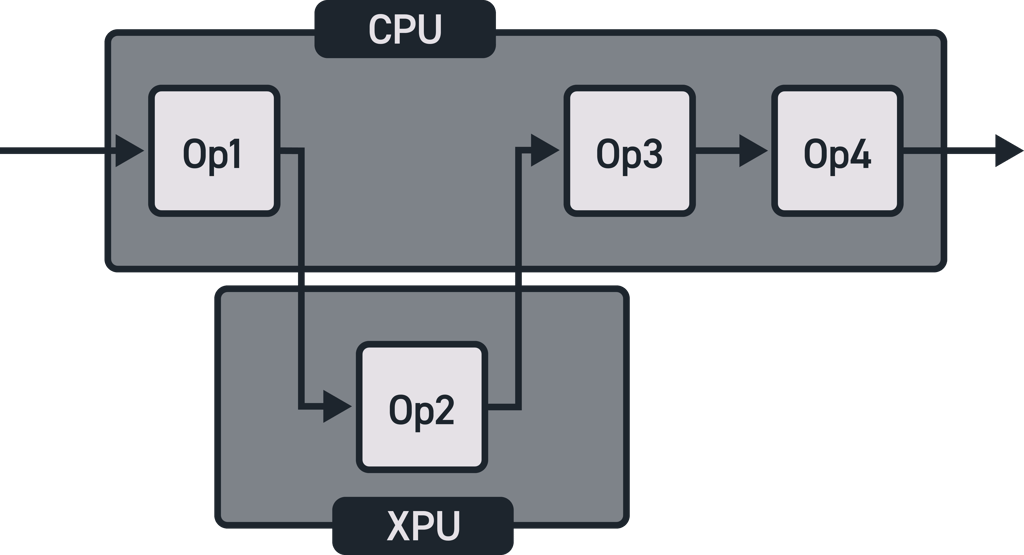
For AI solution developers the OAAX standard should make it easy to reap the benefits of the new chipsets that are
becoming available rapidly without having to worry about the target hardware when setting up and testing their initial
AI pipeline.
For those designing and bringing to the market new XPUs, OAAX Standard is aimed to lower the barriers of entry of
the hardware by providing a unified way in which -- when adhered to -- any developer can easily utilize the advantages
of the newly introduced XPU.
At a high-level, within the framework of OAAX, the deployment process of an AI model is conceptualized as a two-stage pipeline.
- The initial stage encompasses a series of steps and procedures necessary for transforming a trained AI model into an
optimized format or binary.
These steps may include, but are not limited to, validation, parsing, optimizations, and conversion.
This step is performed by what is called an OAAX toolchain. - The second stage entails the utilization of the produced XPU-specific model file, and executing it on a designated
hardware XPU.
This step is carried out by an OAAX runtime.
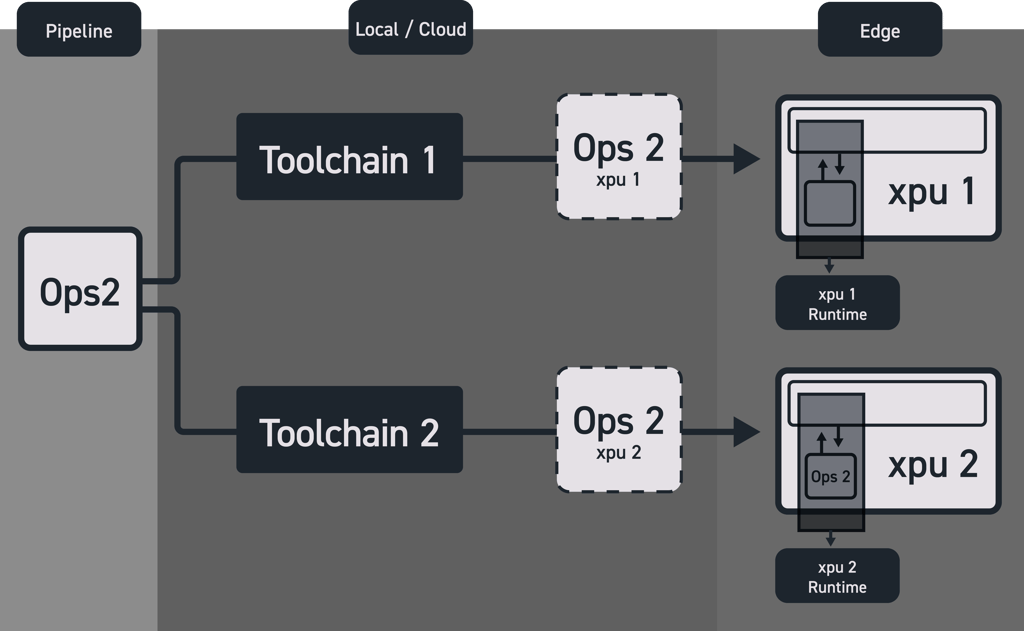
The two components, the OAAX toolchain and the OAAX runtime, of the OAAX standard shine when incorporated into a larger
ecosystem where a user can easily manage the deployment of an AI model on any XPU; effectively making it super easy to
swap two AI accelerators or combine two different AI accelerators in no time, by building a deployment pipeline that
automatically convert a model to all available XPU model formats as shown in the figure below.
This is the main goal of the OAAX standard.
-
For our initial introduction to OAAX Standard and its founding motivations, please see the founding white-paper.
-
For a more detailed information about the OAAX Standard, including a high-level specification, please see the position paper.
We provide a number of code examples to get started. Code examples are split between those geared towards OAAX users, i.e., developers who wish to use the OAAX standard to deploy their models on novel XPUs without doing any complex low-level work, and OAAX contributors, i.e., developers who wish to contribute to the OAAX ecosystem by providing toolchains, runtimes, reference implementations, or other tools useful within the OAAX ecosystem.
Note that the code example below illustrative and not stand-alone: The full source code of the working example can be found in the Illustrative example folder and it's associated README.
At a high level, from the perspective of trying to move a model from one target to another, the OAAX machinery consists of two steps. First, one uses one of the (contributed) model conversion toolchains (which are distributed as stand alone Docker images) to convert the model from ONNX format to a format that runs on the XPU:
# Docker run example of an OAAX conversion toolchain
docker run --name $toolchain_container_name -v "$output_directory:/app/run" oaax-toolchain "/app/run/model.onnx" "/app/run/build"
(look here for a working example including context).
The conversion results in a file that is executable on the XPU. Next the user uses the (contributed) runtime to run the artifact (i.e., to generate inferences). Runtimes are implemented as shared library files with the core inference execution call being:
// Signature of the "run inference" function:
int runtime_inference_execution(tensors_struct *input_tensors, tensors_struct *output_tensors);
(look here for a working example including context).
We provide a number of code examples that allow contributors to contribute OAAX toolchains and runtimes. A "getting started" description can be found here, whereas reference implementations can be found here.
For real-world applications showcasing the benefits of adopting an OAAX-compliant implementation, we are providing a set of examples in the examples repository.
In this section of the OAAX documentation, we describe the ways in which you can contribute to growing the OAAX standard, or be involved in maturing the standard.
The first way to contribute is by creating examples, implementations, or XPU specific OAAX toolchains or runtimes.
If you are an XPU manufacturer and are looking to add your XPU to OAAX, please refer to the illustrative example above, or the reference implementation.
There are many places to get started:
- If you are building example pipelines that utilize OAAX that you would like to share with the larger community, please start with the Using OAAX documentation.
- If you are looking whether a specific XPU supports OAAX standard, please see the contribution repository.
- If you are looking to validate and test your implementation, please refer to the examples repository where you can find lots of application examples that can incorporate any OAAX-compliant implementation.
OAAX Standard was started by Network Optix as an attempt to solve hardware / XPU incompatibility which was slowing market adoption of novel hardware breakthroughs. Thus, from its inception, OAAX has not been tied to individual hardware manufacturers: it is a user driven initiative trying to make adoption of any new accelerator designs into actual meaningful business applications as easy as possible.
We are currently actively seeking for member of the OAAX steering committee to further advance the specification of the standard in a number of focus groups (planned summer 2024). Please leave your contact details at oaax.org if you want to join the upcoming community efforts.