A weird edge case for bleu scoring. #1838
Comments
|
Just a clarification before diving in. Do you get a warning when you try these fringe cases? |
|
Yes, I receive the warning. |
|
Good. Let's go through the rational of why the outputs are as such: Firstly, note that un-smoothed BLEU has never been meant for sentence level evaluation, it is advisable to find the optimal smoothing method that your data require, please look at https://github.com/alvations/nltk/blob/develop/nltk/translate/bleu_score.py#L425 If user wants to skip the step to find the optimal smoothing, let's look at the examples you've listed. First scenario, when your n-gram order is larger than the overlap that exists between the reference and hypothesis, corpus/sentence BLEU will not work in this case. So the results of this cannot be taken into account: Next we have an example where there is 1 bigram and 2 unigram existing overlaps the reference and hypothesis. Seems like it gives a reasonable score. Going to the next example using From we see that it has the same 1 bigram and 2 unigram match but have a higher score. And this is because the we weigh the bigrams heavier than the unigrams and unigrams has 0 influence. Since there are lesser bigrams than unigrams, naturally the resulting BLEU is higher. The description of more matches = better BLEU score is intuitive but actually this is only part of the BLEU formulation reflected in the modified precision: If we move forward to the geometric logarithmic mean, we see the modified precision getting a little distorted: So from the first 3 examples you've given, the first is invalid (thus the warning), the 2nd and 3rd might not be easy to understand but they are mathematically sound: Note that I've skipped the brevity penalty step but trust me it's 1.0 since the length of the hypothesis is the same as the reference. Please test out for yourself too =) Moving on, to the 4th example, we use the same modified precision, then compute the geometric logarithmic mean step: So the usage of bigram BLEU is not valid too without the proper smoothing function. Perhaps, the warning didn't show up when you use the BLEU because the warning filter is set to default. I think it's a good idea to force this warning but it does irritate users when it appears too often in a fringe dataset. Last example is valid, since it returns the expect 0 for 0 matching unigram. In summary: |
|
Now going to the last 2 example. Actually, the first instance is an invalid use of BLEU, you should see this: Whenever the warning shows up at the nth ngram order (in this case, bigrams), it's usually an misuse of BLEU and it will only take into the account the weights of the n-1th order (in this case, the unigrams). So if we see the first example with the only weights for the unigram: The geometric logarithmic mean is rather mind-warping but the key is the sum of the weights to the n-gram orders must sum to 1.0 to fit the BLEU original idea. E.g. In general, whenever the warning pops up, it's an un-BLEU situation where BLEU will fail and there's no active research to patch this particular pain, other than researchers creating new "better" scores that has other achilles heel. In the case that the warning pops-up and user needs a quick-fix, the And if we use So the question then becomes:
If there's any active research and proven solution(s) to these sentence BLEU fringe cases, we'll be open to re-implementation of these solutions. But if it's hot-fixes that results in more wack-a-moles situation of BLEU, then I think the current BLEU version is stable enough with the warnings in-place =) |
|
@benleetownsend I hope the explanation makes sense and show that the current BLEU implementation with the various options is sufficient to overcome the examples you've given. My suggestion is to (i) avoid the weights hacking unless you use some information theoretic approaches to estimate them, (ii) use the |
|
Thankyou for your detailed response. I agree with everything you've said however I guess my underlying point is that to me the results when you back off to n-1 grams just seems wrong based on the literature I have seen. In this above case I would say that following the BLEU equation and returning 0 for this case is "undesirable" but unless i've missed something in the literature, the result of 0.5 for this is wrong. I would suggest either a clearer warning that states that the results are wrong (instead of undesirable) or setting the default "smoothing" mechanism to return If you disagree feel free to close this issue. I have resolved this in my project with a custom smoothing function containing the above functionality. Thanks again for your time. |
|
Short questions. Which dataset are you working on? And how often this happens? Also, smoothing is the way to go. |
|
Going back to why adding the When we add You could do this if you want the functionality of a smoothen BLEU: But we cannot add that in Returning a The BLEU formula is One reason why hacking the weights without empirical truth is a bad idea because the weights in BLEU is subjected to So if we walk down the BLEU calculations, with the usual 0.25 uniform weights, the BLEU score extremely small to 0. Using the Maybe it's not evident but returning the If we imagine the usage on a relatively good or almost perfect translation, here we see a counter example: The main reason why I've asked about the dataset and how often the problem is occurring is because you might not be anticipating the wave of other problems as the one above. Once we try to return Alternatively, if we return the backoff n-gram: In any case, when using sentence BLEU on really loose translation or short sentences, always smooth: |

|
@alvations Thanks for all the great code in NLTK. We've been using it to some extent when experimenting with dialogue-response modelling systems (or chat-bots) at True AI. I definitely see the point of warning the user about not using a smoothing function when any of the n-grams evaluates to 0. After having read up on the smoothing functions, we have now started using smoothing function 1 as default. However, I was still very surprised when I got the results with smoothing function inactivated in the cases when it didn't find any n-grams of a particular order. I got results that I did not expect looking at the equations in Chen et. al (which is one of the papers you mention in the documentation). The main equation, used to calculate the BLEU score (without smoothing) that you posted above (eq 2 in Chen et. al), and which you use in the code is: In conclusion you are using a different equation than what you advertise. You mention in the documentation that smoothing function 0 means that no smoothing is used, and that you use the base equations to calculate BLEU in that case. This is simply not true. You are not using the base equation, you are using a modified version to calculate p_m compared to what is mentioned in the paper. |
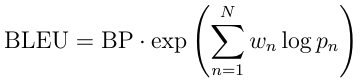
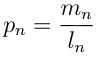
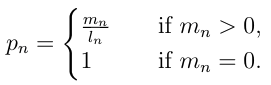
|
Ah ha, that's a gotcha between the original BLEU vs the Eqn (2) from Chen and Cherry (2014). Note that in the original BLEU (1992), the p_n needs to move from the decimal space to the logarithmic space, which leads to the the math domain error when p_n = 0:
So in that case, the "hacks" are put to overcome all the fringe cases. The But in the Chen and Cherry formulation, it's a product of the decimals with the inverse power of the N, i.e. Which would avoid the math domains errors without the log and exp space. But maybe it will also lead to another wave of errors, most probably coming from underflow issues or maybe not. As long as the unittest for BLEU checks out, I think an implementation of this would be an encouraged PR too ;P I guess the decision to go with the original log+exp formulation because we decided to go with the implementation that follows closer to the The decision to back-off Or would anyone vote for the NLTK implementation to use the Chen and Cherry (2014) formulation instead? But I see now why you would have more problems when using BLEU in dialog systems where the sentences/segments might be really short. |
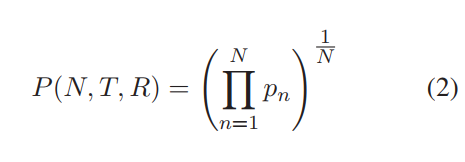
|
Actually, after the implementation of the BTW, for my personal use, I would always set the default smoothing to |
|
The two equations are actually identical from a mathematical point of view (apart from w_n). The difference is that one has to be careful about what to do when evaluating log(0). Here log(0) should be evaluated to -inf (or something similar if -inf isn't available in the library used to handle math). Evaluating it to 0 breaks the math as pointed out above. Evaluating it to 0, means that a particular sentence will get a better BLEU score if no n-grams were found of a particular order, than if just one n-gram was found, which is counter intuitive. Evaluating log(0) is never straight-forward. And need to be handled on a case-by-case basis. However, in this particular application the correct thing would definitely be to use -inf. |
|
Briefly looking at the code the correct way of fixing this would be to change what follows this else-statement to: or The warning could be preserved if you'd like. It could alternatively be merged with the |
|
@bamattsson Precisely, they are the same implementation and if the rework of using From the example in my previous comment, appending Which led to the failing unittest on https://nltk.ci.cloudbees.com/job/pull_request_tests/430/TOXENV=py35-jenkins,jdk=jdk8latestOnlineInstall/testReport/junit/nltk.translate/bleu_score/sentence_bleu/ and thus the failing checks on #1844. The fix is VERY dependent on what kind of dataset one is working on. This should NEVER be a problem in corpus BLEU because the assumption at corpus level has always been that there are at least 1 4-gram matches between the hypotheses and their references. So my suggestion is to rework your hotfix as a flag / argument /option that one would pass to sentence bleu. And if you would like, make the flag the default and still go back to the ngram backoff technique when turned off. There were many considerations taken to make the ngram backoff choice. Perhaps reading #1330 might help too. |
|
Actually, looking at the PR carefully. Is it right that the outputs of the test cases using the hotfix you're proposing gives the same output as |
|
Resolved in #1844 |
|
Thanks @alvations, @bamattsson, @benleetownsend |
Long discussion here: nltk/nltk#1838 Went with method 4 since that seems to be a favorite.
There is an unintuitive functionality of the bleu_score module.
The default
SmoothingFunction.method0skips any fractions that are equal to zero making bleu scores in these cases quite unintuitive. In my opinion this would be more intuitive to have the log(0) evaluate to -inf resulting in the overall bleu score in these cases evaluating to 0. This along with a clearer warning would make this much more intuitive.To clarify, as seen below it gives a higher bleu for a worse match when i believe it should receive a bleu score of 0.
The text was updated successfully, but these errors were encountered: