This repo is now archived.
From a bunch of documents to an easy-to-use search engine for emails, websites, social media posts or just about anything.
For more in-depth projects, you can easily customize the interface to easily make new document-specific custom formats for searching and exploring. To deploy to your newsroom, just add your own standalone ElasticSearch server; Stevedore's frontend framework is all-frontend.
Download this repo and run docker-compose, then visit localhost:9293. You'll see a Stevedore search engine, pre-populated with some of Hillary Clinton and Jeb Bush's emails. (Clinton's released under FOIA by the State Dept., Bush's released publicly by the State of Florida.)
If you drop some files you want to search in the user-files folder, Stevedore will index them for search. (If those files are emails or PDFs, you'll also want to change the data-type for user-files in document_sets.json to pdf or email.)
This "quickstart" doesn't expose all of the features of Stevedore -- you'd have to go through the full installation for that -- but it's pretty close.
Do you have all the documents in a folder (or a zip archive) somewhere? Then you're ready to go. Just download the last release then double-click to run it.
Be sure to have Java 8 installed.
Stevedore can make two types of search engines:
- Local search engine that only your computer can access.
- Production search engine that other computers can access. If you choose this option, you need to have a separate ElasticSearch server to host the search index and an Amazon S3 bucket to host the frontend.

- Run the command-line app with arguments for (the location of your app)
bundle exec ruby uploader/stevedore.rb --index=foss-test --host=http://12.3.45.67:80 s3://int-data-dumps/foss-test-data
If you're using the Docker-Compose version mentioned above, the "host" is localhost:9201.
If you want to set up Stevedore in a production-like environment -- that is, if you want to other people to use it, you probably don't want to run it on your computer with docker-compose.
Instead, you'll want to create an
- an Elasticsearch server running somewhere, probably in the cloud.
- an Amazon S3 bucket for your files to go to. (If you have sensitive documents, you could deploy Stevedore's files to a local HTTP server, so the sensitive documents don't go into the cloud.)
- Either a webserver, like nginx, to serve the frontend files (i.e. the contents of this repo) or just put this repo's files on S3 somewhere. (To be clear: Stevedore does not need a webserver to serve the frontend, it's entirely static.)
Stevedore has no security of its own, besides the security of your Amazon S3 bucket and your ElasticSearch server's policies. Anyone who can access the S3 bucket and the ElasticSearch server can use your search engine, so be sure to set your access policies correctly. How to set these up securely is outside the scope of this document. (Unless someone else wants to write instructions and submit a pull request.)
Each template must contain four distinct files. Inheritance isn't possible now (just cp the file) but I hope to add that in the future.
- a "detail view" template for seeing an entire, single document inside the app
- a "list view" template for seeing a single document in a list of returned search results matching a query
- a "search box" containing all the relevant fields to be searched. Design is important here.
- a "query builder" JavaScript function to transform the search box into a valid ElasticSearch query.
Optionally, you can include custom CSS too.
- Pick a name for your template type. This is the path under
templates. So, maybe,templates/blogpost/if you're creating a template to search blogposts. - Create the files themselves as
templates/<template_name>/<template_type>.<extension>, e.g.templates/blogpost/list_view.template - Write template files for detail_view, list_view and search_form. Copy/paste will be your friend (until there's a DSL for creating these) to make styles easy, as well as making sure the
detail_viewmodal works well. - Write a query_builder. This is a JavaScript file that manages transforming your
search_form's HTML into a Backbone object representing a search (e.g. so pagination works, etc.) in thelikeActuallyCreatemethod and transforming that object into an ElasticSearch query (toQuery). The examples provided will be your guide. - The query_builder is also involved in serializing/deserializing the query fields into a URL (and saved search format). All you have to do is specify the fields, in an array, in a sensical-ish order in the
fieldOrdermethod. - Your query_builder's
likeActuallyCreatemethod should, referring to the search template, populate the search Backbone object from the values of the form fields in the search from (which should be now rendered onto the page, but which ought to cope with null values.) - Your query_builder's
toQuerymethod will require some ElasticSearch knowledge. Follow the examples. :)
The availability of templating relies on Stevedore's objects each containing, at a bare minimum, an id field that is persistent across reindexing, a source_url field to the original document and an analyzed.body field that contains the full text.
You may have documents that need to be searchable in Stevedore, but need to be indexed in a different way. You have two options here: customize the uploader, or go it alone and create your own upload script.
Creating your own upload script is relatively easy. Using whatever method you prefer, shove your data into ElasticSearch, being sure to include an id field, a source_url field and an 'analyzed.body' field. Stevedore will infer the existence of your database directly from ElasticSearch, with no action from you necessary (you may still want to add metadata in document_sets.json).
Information on how to customize the uploader is TK.
Stevedore consists of two main pieces:
- an ingestion GUI and script to process your documents -- emails, powerpoints, whatever -- and send them to ElasticSearch.
- a website frontend/framework for actually searching ElasticSearch. If you choose to deploy this frontend to the web, you can easily write custom templates for searching with custom fields.
The ingestion script is in another repo: stevedore-uploader uploader/upload.rb and most of the logic is in lib/stevedore_uploader.rb. The guts of the extraction are Apache Tika, which is super awesome software, by the way. The ingestion GUI is a work in progress, but it lives in the uploader/ folder in this repo, along with config.ru.
The frontend framework is all JavaScript and HTML. No backend (besides vanilla ElasticSearch). You run it (in development) by running rackup in the root of this project. In production, put the root of this project somewhere where it gets served on the web -- like Amazon S3 or Nginx. (The files? search.html, index.html, app/, lib/ and templates/)
The app/ folder contains the framework: a set of common components (frames, sort of) that render project-specific templates (in templates/) to handle variation in search app UIs. The common interface includes a place for search forms, a list view and detail view -- as well as an index page (index.html) for listing all your search engines. lib/ is supporting libraries like JQuery.
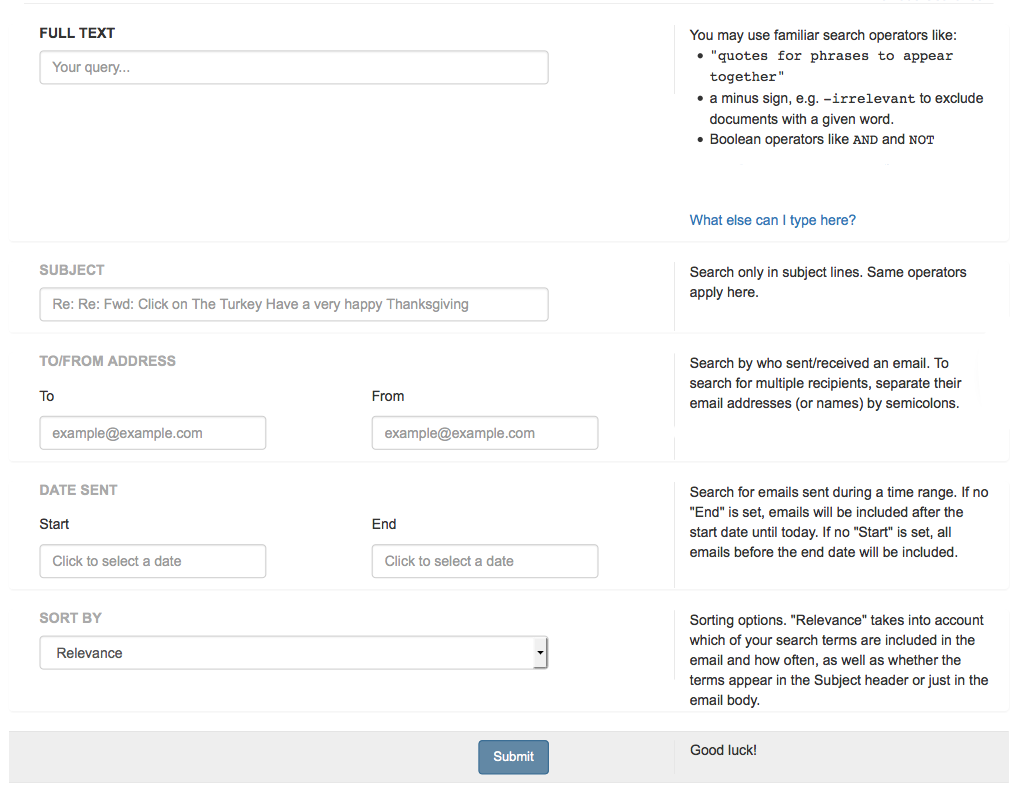
The results list looks like this:

And detail pages, for each result, look like this:

Here's the workflow we've envisioned for this:
Sometimes we're a bit blindsided by a document dump. This tool has two goals: To easily stand up a generic, workable search tool quickly; and to, when necessary, tweak the tool for highlight project-specific fields or priorities. A generic email-search template is not sufficient: in one case, the focus may be on searching emails by who they're addressed to, so the To: search field should be foregrounded; in another, the focus may be on searching the Subject: fields, and so that ought to be foregrounded. Copying, pasting and modifying the HTML of a template seems to be the easiest way to do this -- in an environment where a person who's minimally aware of this app config can do it.
Another, separate design goal is to use the URL as a config store: my-stevedore-site.my-company.local/jeb searches Jeb Bush emails on production, whatevertheappurlis.my-stevedore-site.my-company.local/hrc searches Hillary Clinton emails on production; 127.0.0.1:8080/jeb searches Jeb Bush emails using the local search app.
- clone the repo
- Be sure to have JRuby 1.7 or 9.0.0.0 installed (e.g. with rbenv)
bundle installbundle exec rackup(orNGINXVERSION=1 bundle exec rackupif you want to simulate running under NGINX; or just runnginx)- edit
templates/(orapp/) code
bundle install
warble jar # to build the stevedore.jar file
docker run -e AWS_ACCESS_KEY_ID=AKIAwhatever -e AWS_SECRET_ACCESS_KEY='asdfasdf' -p 8080:8080 -p 9200:9200 -v /path/to/stevedore:/jar -t java:8 java -jar /jar/stevedore.jar
Check out the GitHub issues or these Theoretically Asked Questions:
☕ Java. ☕
(And the fact that we're packaging JRuby, ElasticSearch, etc.)
Because it's running Elasticsearch from inside the same Java process as the app itself. It's probably faster if you set up your own separate Elasticsearch server.
Great question! Those are all great tools made by great people, but they solve a different problem than Stevedore. What problem does Stevedore aim to solve? I don't like doing 'training' for software. I think it's pathological and teaches dependency instead of self-sufficiency. Training for how to use Stevedore's search engines (as opposed to the uploader) should be as simple as Go to this URL, and then type in that box. Stevedore is designed to make easy-to-use search engines.
Yeah, we use this code all the time at The New York Times. Reporters use the Stevedore frontend to search emails from politicians, scraped websites and all sorts of other document sets.
You can help by:
- Reporting a bug.
- Adding or editing documentation.
- Contributing code via a Pull Request from ideas, e.g. your templates, if they're general use.
- Fixing bugs in the issues section.
- Telling your friends if Stevedore might be useful to them.
- Helping other people in the issues section if you know how to fix the problem their experiencing.