![]()
![]()
Hyp (as in "hypothesis") is in beta! We're still working out the kinks. Capiche?
Easily run, monitor, and understand A/B tests from your Rails app.
Hyp lets you A/B test any part of your Ruby on Rails application! Test email content, algorithms, server-rendered pages, or anything else you like.
Both ActiveRecord- and Mongoid-backed applications are supported.
- Basic usage
- Installation and configuration
- Get notified upon completion of an experiment
- Authorization
- Methodology
- Creating experiments and calculating sample sizes
- Documentation
- Testing
- Contributing
- License
Conditionally execute code based on the experiment variant a user belongs to:
experiment = Hyp::ExperimentRepo.find_by(name: 'My very first experiment')
variant = experiment.variant_for(user)
if variant.control?
# do existing behavior
else
# do new behavior
endUser assignments are consistent, so a given user will always belong to the same
variant for a given experiment. The assignments are based on a SHA256 hash of
both the user's and experiment's #ids.
Record user trials and conversions via Ruby:
# Eg, when user visits a page
experiment = Hyp::ExperimentRepo.find_by(name: 'My very first experiment')
experiment.record_trial(user)
# Eg, when user takes the action you're interested in
experiment.record_conversion(user)Calling #record_conversion will create a trial for that user if one doesn't
already exist. There is a unique database constraint limiting users to a single
trial per experiment.
You may find yourself repeatedly writing code very similar to that shown above, where you:
- Find an experiment by its name.
- Find the variant of that experiment for a given user.
- Maybe record a trial.
- Finally, execute one piece of code if the user is in the control variant, and another if they're in the treatment.
You can use Hyp::ExperimentRunner.run to do all of that:
Hyp::ExperimentRunner.run(
'My experiment',
user: user,
control: -> { # do control things },
treatment: -> { # do treatment things },
record_trial: true
)If no experiment with the provided name is found then the control block of code
will execute. This is nice because it means you don't need to have your
application's tests create experiments in order for them to pass.
Record a trial via JavaScript:
$.post(
'/hyp/experiment_user_trials',
{ experiment_name: 'My Very First Experiment', user_identifier: 1 },
function(data, status, _xhr) {
console.log("Status: %s\nData: %s", status, data);
}
);Record a conversion via JavaScript:
$.ajax({
url: '/hyp/experiment_user_trials/convert',
type: 'PATCH',
data: { experiment_name: 'My Very First Experiment', user_identifier: 1 },
success: function(data, status, _xhr) {
console.log("Status: %s\nData: %s", status, data);
}
});In order to record trials or conversions in emails you can use the Hyp::QueryParam
class to add special query params to the links or buttons in your emails.
These query params are Base64 encoded strings that contain the IDs of a given
experiment and user, as well as an event_type string specifying whether Hyp
should record a 'trial' or a 'conversion' when the URL is visited.
Call Hyp::Experiment#conversion_query_param(user) or
Hyp::Experiment#trial_query_param(user) to generate the Base64 encoded string.
Simply add one of these strings to your URL in a query param called :hyp, and
then in the corresponding controller call Hyp::QueryParam.record_event_for(params[:hyp]).
Eg in your email view:
hyp_query_param = @experiment.conversion_query_param(@user)
url = cats_url(hyp: hyp_query_param)
link_to 'Click me!', urlAnd in your CatsController:
def index
QueryParam.record_event_for(params[:hyp])
#...
endThis will record a conversion for @experiment and @user.
Visit the /hyp/experiments page to CRUD your experiments:
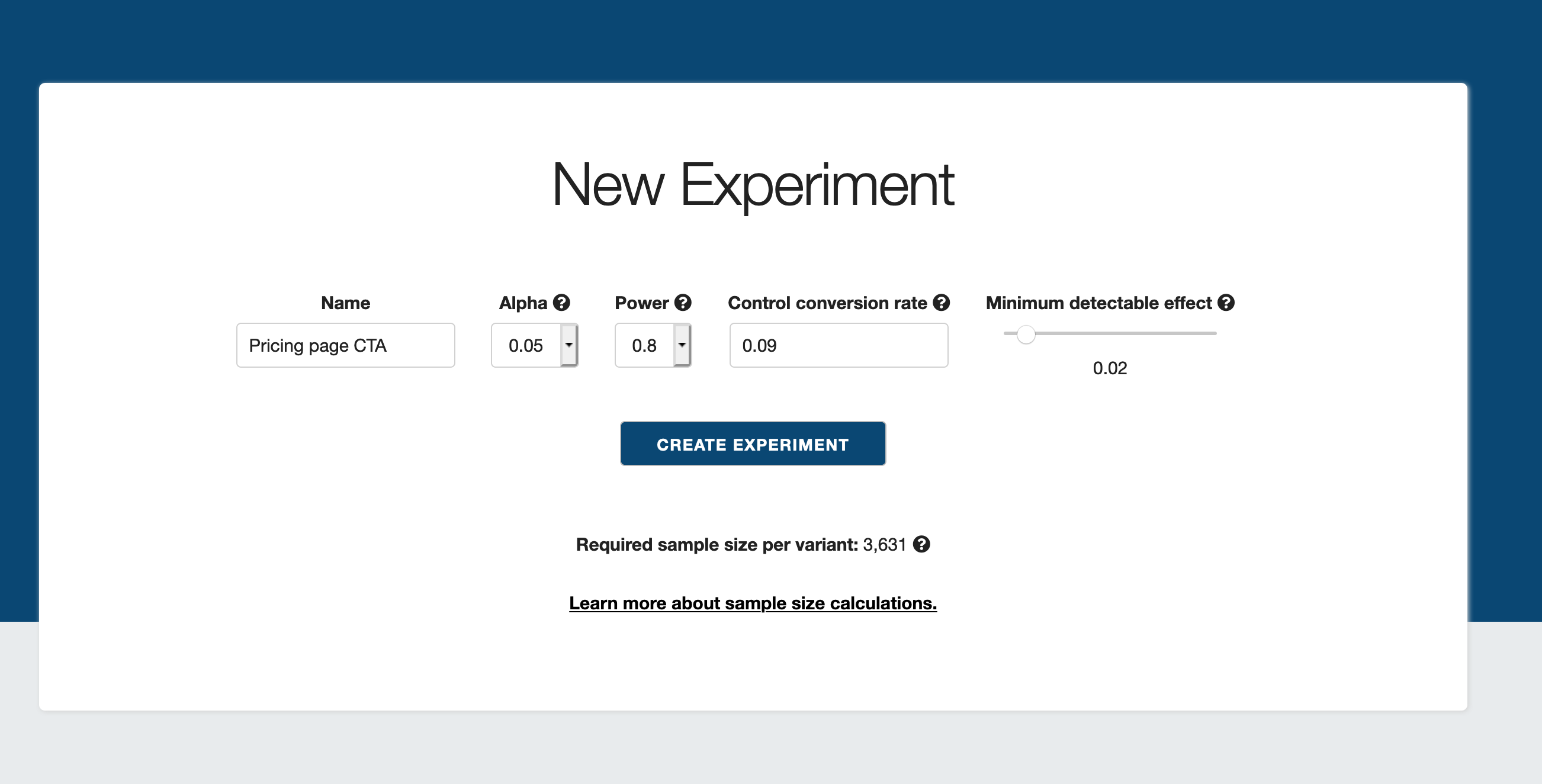
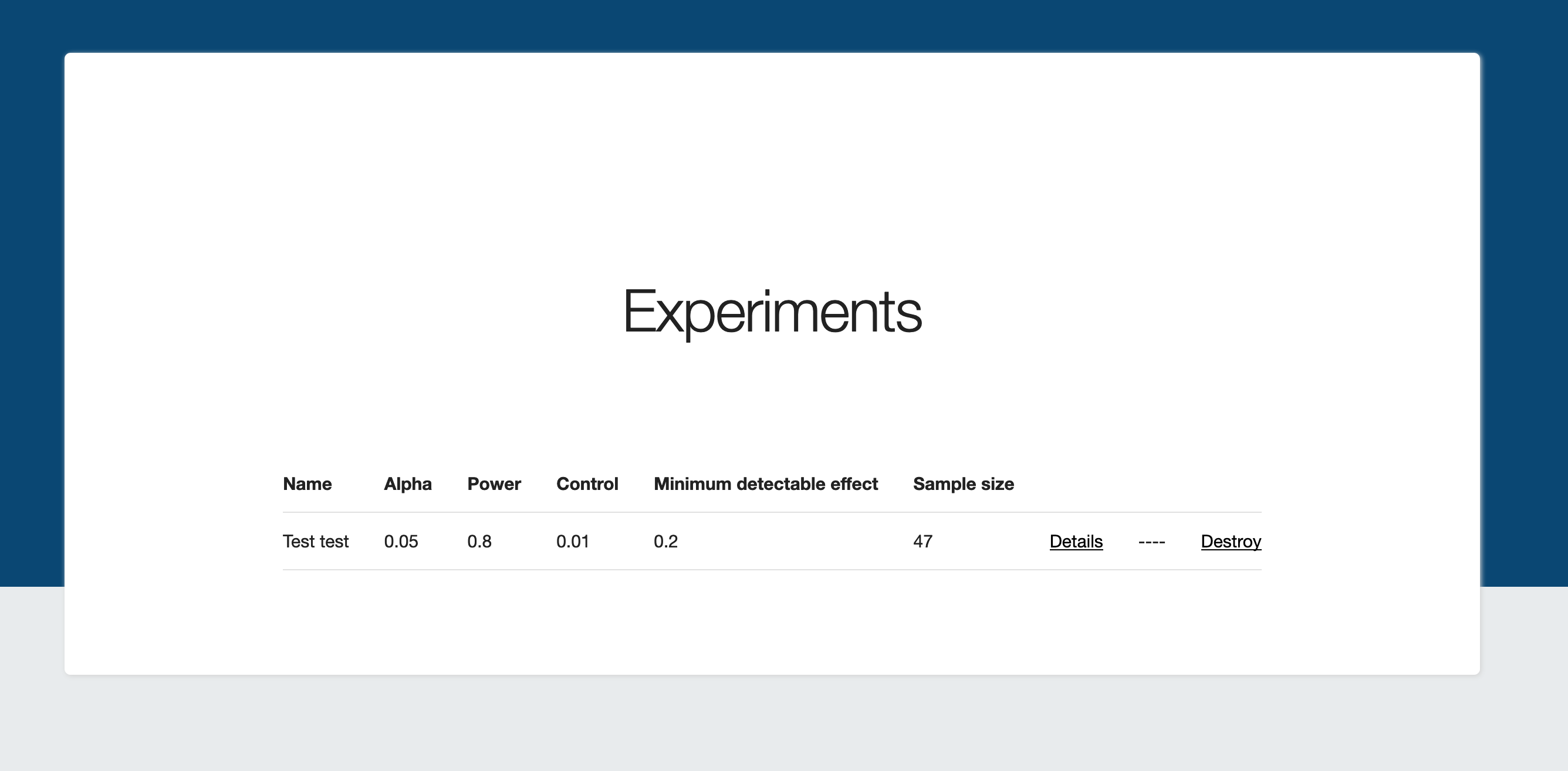
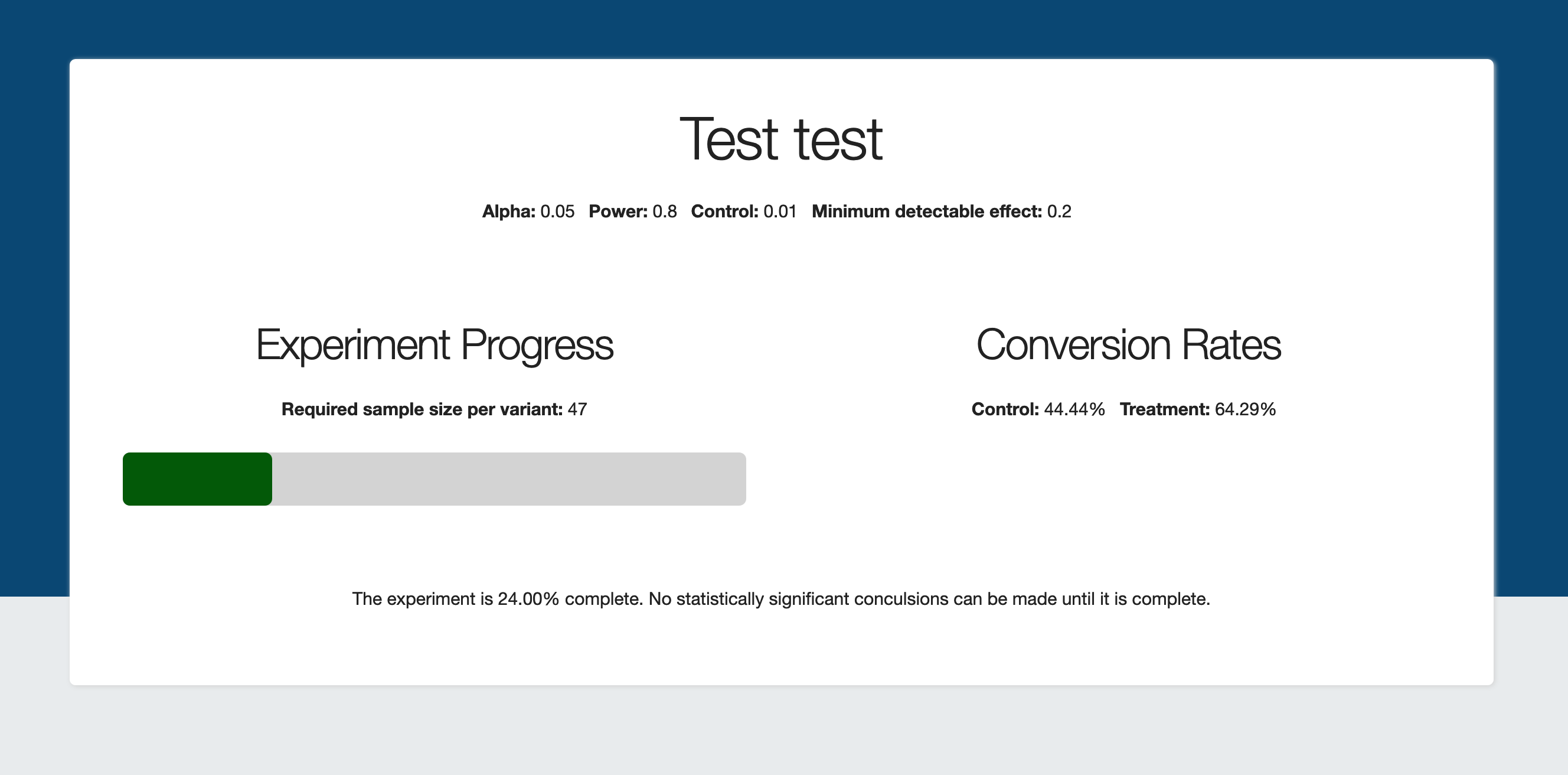
Click on a particular experiment to see how far along it is, and what conclusions
can be drawn from it (if any):
Add these lines to your application's Gemfile:
git_source(:github) { |repo| "https://github.com/#{repo}.git" }
gem 'hyp', github: 'murphydbuffalo/hyp'And then run:
$ bundleFinally, run the installation generator:
$ rails g hyp:installThis will:
- Create
config/initializers/hyp.rb. - Add
mount Hyp::Engine => '/hyp'to the top of yourconfig/routes.rbfile. - Add the migrations for creating Hyp's database tables to your
db/migratedirectory.
hyp:install takes two optional flags: --db-interface, and --user-class.
--db-interface tells Hyp which ORM/ODM your application uses. It can be either
active_record or mongoid. It defaults to active_record.
If you add --db-interface mongoid the generator will:
- Add
Hyp.db_interface = :mongoidtoconfig/initializers/hyp.rb. - Not add the aforementioned migrations.
- Create models that know how to talk to Mongoid. Hooray!
In Hyp we associate each trial with a particular user using a "has and belongs
to many" relationships between the user and experiment. The --user-class option
tells Hyp what class you'd like to use as the "user" in your experiments.
It can be any string that can be #constantize'd to a valid class from your
application code. It defaults to 'User' if not present.
If you add --user-class MyClass the generator will add
Hyp.user_class_name = 'MyClass' to config/initializers/hyp.rb.
Hyp provides the Hyp::ExperimentMailer#notify_experiment_done method to send
an email summarizing the results of an experiment.
Hyp also lets you run arbitrary code upon completion of an experiment via the
Hyp.experiment_complete_callback attribute.
To set this up open config/initializers/hyp.rb and set
Hyp.experiment_complete_callback to an object that responds to #call, such
as a lambda. Hyp will pass the ID of the Hyp::Experiment when it invokes #call.
For example:
# /config/initializers/hyp.rb
Hyp.experiment_complete_callback = ->(experiment_id) {
Hyp::ExperimentMailer.notify_experiment_done(experiment_id, 'dev@example.com')
.deliver_later
}In the above example we're using #experiment_complete_callback to send email
via the Hyp::ExperimentMailer, but you can run whatever code you like here.
#notify_experiment_done takes the ID of an experiment and a string
representing the email address that should receive the email.
Hyp runs HTTP Basic Auth on the ExperimentsController in the production and
staging environments. Be sure to set the HYP_USERNAME and HYP_PASSWORD
environment variables, which will be the credentials required to log in.
Hyp runs two-tailed hypothesis tests for the difference of two sample proportions: the proportion of users who converted on the control variant of a feature and the proportion of users who converted on the treatment (new, experimental) variant of a feature.
Our hypotheses are as follows:
- Null hypothesis, h0: (control - treatment) = 0
- Alternate hypothesis, hA: (control - treatment) != 0
The effect size of the test is the difference between those two proportions.
We calculate a z-score for that effect size, which is how many standard deviations it is from the mean of a normal distribution.
This standard deviation calculation relies on the size of the sample the proportions are calculated for, and we determine this sample size prior to the running the experiment based the values of alpha, statistical power, minimum detectable effect, and the control proportion you have selected for it. See Creating experiments and calculating sample sizes for more details.
Using our z-score we then calculate a p-value, or the probability of an effect size at least as large as ours occurring by random chance given that the null hypothesis is true.
If this p-value is is lower than the experiment's level of alpha we have a statistically significant result.
It is up to you to interpret the the results of the hypothesis test. A higher treatment conversion rate may be good, signifying a greater percentage of users who visited a page and clicked on the sign up button. It may also be bad, perhaps signifying that a greater percentage of existing customers clicked the button to cancel their account.
An experiment might tell you that while the results are significant, it is the control variant that performs better, and therefore that you should not replace it with the treatment.
Perhaps no significant result will be detected. Keep in mind that you only have a percentage chance of detecting positive results (if they exist) equal to your chosen level of statistical power.
You might decide to replace the existing variant of the feature even if there is no statistically significant difference between the two variants simply because you prefer the code or aesthetic quality of one variant. The Signal v. Noise blog has an excellent post on this topic.
Beware! We talk about statistics below. If you'd rather just use Hyp and not get a refresher math course feel free to skip this section. If you want to be confident that Hyp works properly or are simply curious to learn more, please continue :).
When you create an experiment Hyp will calculate the necessary sample size for it to satisfy some parameters you have specified. If you're not already intimately familiar with A/B testing this warrants some explanation. Why do we need to know our sample size ahead of time? Can't we just run the experiment until a significant result is found? The answer, sadly, is no.
Check out Evan Miller's excellent blog post How not to run an A/B test to get a sense of why this is.
In short, if you run your test until you find a significant result you're gaming the system and tricking yourself into thinking your results are statistically valid when they may not be. Specifically, you could find a significant result after 500 trials and stop the experiment, not realizing that after 1000 trials the result would not have been significant.
On the other hand, you can also run your experiment for too long and get too large of a sample size. The larger your sample the smaller its standard deviation will be, and we determine statistical significance by measuring how many standard deviations from the mean a result is. Therefore, with a large enough sample size any result will be found statistically significant by virtue of the standard deviation being very small. This can mean running an experiment only to find a significant result that you don't care about, maybe a 0.00001% increase in some metric.
What we want is the smallest sample size that will effectively find us significant results that we actually care about.
"Effectively" means balancing the likelihood of false positives and false negatives
in our experiments. There is always some chance of each. As we'll discuss below
we can choose different levels of alpha and power to set the probabilities
of false positives and negatives, and these parameters are part of what dictates
the sample size we'll need.
The sample size calculation also requires data about the existing control variant and something called the minimum detectable effect.
So what are all of these parameters and why do you need to provide them in order to calculate the sample size?
Also known as the significance level, alpha is the threshold at which we deem a p-value to be statistically significant. If our p-value is lower than our chosen level of alpha we reject the null hypothesis and accept the alternate hypothesis.
All this means is that if we assume the null hypothesis is true and there really is no difference between the control and treatment conversion rates, then the effect size we saw would happen by random chance less often than our chosen level of alpha.
For example an alpha level of 5% means that we will only deem significant results that would happen less than 5% of the time, assuming the null hypothesis is true.
Changing this parameter involves a trade off: a lower alpha means a lower risk of false positives but a higher risk of false negatives because the criteria for a result being significant is more stringent.
Alpha is required to be one of two conventional values: 0.05 or 0.01.
This is the probability of detecting a positive result (rejecting the null hypothesis) if one is present. Higher power means a lower probability of false negatives (not rejecting the null hypothesis when it is false). Larger sample sizes allow you to have higher levels of power.
All else being equal, decreasing alpha means decreasing power because a lower alpha makes it harder to classify a result as significant.
Power is required to be one of two conventional values: 0.80 or 0.90.
In our sample size calculations power is very closely related to another concept: the minimum detectable effect, or MDE.
The smallest effect size you would care to detect. We don't want to run an experiment only to find out that the result, although statistically significant, is not large enough to deliver business value.
The level of power we calculate is for an effect size at least as large as your MDE. So if 1% is the smallest effect size that matters to your business for a given experiment, and your power level is 80%, your experiment will have an 80% chance of detecting a significant 1% effect.
If your experiment achieves a bigger effect size than your chosen MDE then your power will be even higher than the level you chose. The opposite is also true, if your experiment's effect size is smaller than the specified MDE you will have lower power.
Hyp treats MDE as an absolute percentage. So if the control variant converts 10% of the time and your MDE is 5%, then the treatment variant needs to convert at least 15% of time to satisfy the MDE.
You must have existing data for, or a reasonable estimate of, the conversion rate of the current variant of the feature. If you don't have data on an existing version of the feature - maybe you haven't released it yet - go and gather some data before running experiments on it.
In practice this isn't a terrible experience. Release a version of your feature and gather data on its conversion rate until you have a few hundred examples. Now you're ready to go with a reasonable estimate of the feature's conversion rate AND you've had time to work out any major kinks in the release before you start experimenting with different versions of it.
The closer this value is to 0.5 the larger the required sample size will be. This is because there is greater variance in the distribution as its conversion rate approaches 0.5. Think of it this way: if the control conversion rate is 100% then we always know what will happen. The user will always convert. This means there is no variation in the outcomes. The closer the conversion rate comes to 50% the less able we are to predict what will happen.
At a 50% conversion rate conversions and non-conversions are equally likely to occur. Thus the closer to 50% the conversion rate is, the more variability there is in the probability distribution of our experiment and the larger the sample size that is required to guarantee the levels of alpha and power we have chosen.
The sample size calculation is telling us the smallest sample size required for each variant in order to guarantee our chosen levels of power and alpha, given our control conversion rate and an effect size at least as big as our MDE.
If your experiment ends up having an effect size larger than your MDE, great! That means you have even higher statistical power than you were aiming for, and thus a lower risk of false negatives.
I like to think of it as having various levers to pull and tradeoffs to make. If you want lower alpha and higher power, you'll need a higher sample size. If you want to be able to detect very small effects, you'll need a higher sample size. If there is a ton of variability in the control variant's probability distribution you'll need a higher sample size.
But conversely, if you only care about very large effect sizes, or if you don't need a high level of power, or a low level of alpha, then you can get away with a smaller sample size.
For a more in-depth discussion of these concepts check out my blog post on the subject: Why do I need such a large sample size for my A/B test?
It's worth mentioning that there may be parts of your application that you'd like to test, but probably shouldn't. Typically this happens when the thing you want to test:
- Is important for your application
- Does not get enough usage to satisfy the required sample size of the experiment in a reasonable amount of time.
The combination of those things means that you could be running an experimental variant for many weeks that provides a substantially worse result than the control.
For example, if you want to test the copy on an email that doesn't get sent out very often, but which is critical for users to take some action in when it is sent you may not want to A/B test it. Of course, this is a judgment call. If you are very confident that the experimental variant you want to try out will not perform much worse than the control, then you maybe comfortable running the experiment for a long time.
CRUD experiments. It's almost always preferable to use Hyp::ExperimentRepo rather than directly querying for or creating a Hyp::Experiment. The repo handles things like eager loading, and being able to talk to both ActiveRecord and Mongoid.
.list(offset: 0, limit: 25)- List experiments with their variants eager loaded..find(id)- Retrieve an experiment by ID with its variants eager loaded..find_by(hash)- Retrieve an experiment by a hash with its variants eager loaded..create(hash)- Create an experiment, including control and treatment variants.
Conditionally execute code for a given user and experiment depending upon which variant the user has been assigned to.
.run(experiment_name, user:, control:, treatment:, record_trial: false)- This methods queries for an experiment with the given name and then invokes#callon whatever you pass tocontrolortreatment(presumable a lambda or proc) depending on the variant the user has been assigned to.
If no experiment is found then the control block is called.
record_trial defaults to false. If set to true it records a trial for the
user and experiment.
has_manyHyp::Variants, an experiment will always have two variants. When an experiment is destroyed so are its dependent variants.has_manyHyp::ExperimentUserTrials. When an experiment is destroyed so are its dependent user trials.
#alpha- the significance level of the experiment. A float that is either 0.05 or 0.01.#control- the conversion rate of the existing variant of the feature. A float between 0.0 and 1.0.#created_at- Timestamp#minimum_detectable_effect- the minimum detectable effect (MDE) of the experiment. This is the smallest effect size you care about. A float between 0.0 and 1.0.#name- the name of the experiment, a string.#power- the statistical power of the experiment. A float that is either 0.80 or 0.90.#updated_at- Timestamp
#control_conversion_rate- The percentage of users who have been exposed to the control variant that have converted.#control_variant- the control instance ofHyp::Variantfor this experiment.#conversion_query_param(user)- Return a Base64 encoded string for use as a:hypquery param on a URL. When a user visits the URL you can record a conversion by callingHyp::QueryParam.record_event_for(params[:hyp]).#effect_size- The difference between the control and treatment conversion rates. A float.#finished?- Has the experiment recorded#sample_sizetrials for each variant? Finished experiments cannot have any more trials or conversions recorded.#loser- Returnsnilif the experiment is notfinished?, if no significant result was found, or if the#effect_sizeis lower than the#minimum_detectable_effect. Otherwise returns the losing variant.#progress- What fraction of the required sample size (for all variants) has been met? A float from 0.0 to 1.0.#record_conversion(user)- Finds or creates a trial for the user and experiment (represented as anExperimentUserTrialin the database) with theconvertedfield set totrue.#record_trial(user)- Finds or creates a trial for the user and experiment (represented as anExperimentUserTrialin the database).#sample_size- The number of trials per variant required to reach statistical significance for the experiment's#powerand#minimum_detectable_effect. A positive integer.#significant_result?- Is the result statistically significant?#started?- Have any trials been recorded for the experiment? Experiments that have started cannot be edited.#treatment_conversion_rate- The percentage of users who have been exposed to the treatment variant that have converted.#treatment_variant- the treatment instance ofHyp::Variantfor this experiment.#trial_query_param(user)- Return a Base64 encoded string for use as a:hypquery param on a URL. When a user visits the URL you can record a trial by callingHyp::QueryParam.record_event_for(params[:hyp]).#winner- Returnsnilif the experiment is notfinished?, if no significant result was found, or if the#effect_sizeis lower than the#minimum_detectable_effect. Otherwise returns the winning variant.
belongs_toaHyp::Experiment, which will always have two variants.has_manyHyp::ExperimentUserTrials.
.control- Database scope that queries for control variants..treatment- Database scope that queries for treatment variants.
#created_at- Timestamp#name- The name of the variant, either'control', or'treatment'.#updated_at- Timestamp
#control?- Is this the control variant, the existing variant of the feature that currently exists in your app?#treatment?- Is this the treatment variant, the new variant of the feature that you'd like to compare to the control?
belongs_toaHyp::Experiment.belongs_toaHyp::Variant.belongs_toaUser(or whatever the result of#constantizeingHyp.user_class_nameis).
converted- Boolean, defaults tofalse.
after_create- If you've setHyp.experiment_complete_callbackto an object that responds to#callin theconfig/intializers/hyp.rbfile that object will have#callinvoked with the#idof the experiment once it has run to completion.
Useful for running email related experiments. Generate and parse base64 encoded strings for use as URL query parameters. These query params contain the info necessary for Hyp to record a trial or conversion for a given experiment and user.
.record_event_for(base64_encoded_string)- Parses a base64 encoded string generated by the#to_smethod described below, and records the appropriate event by calling the#record_eventmethod described below.
#new(experiment:, user:, event_type:)#to_s- Returns the base64 encoded version of a string of the format"#{experiment_id}:#{user_id}:#{event_type}"whereevent_typeis either'conversion'or'trial'.#record_event- Record either a trial or a conversion - depending on the value ofevent_type- for the given user and experiment.
#notify_experiment_done(experiment_id, receiver_email)- Send an email toreceiver_emailsummarizing the results of an experiment.ExperimentMaileris anActionMailersubclass so it returns an instance ofMail::Messagewhich you can use to actually send email by calling#deliver_nowor#deliver_lateron ion it.
There are RSpec unit tests for code that doesn't depend on Rails in the spec/lib
directory. Run these with rspec spec/lib.
There is also a bare-bones Rails application under spec/dummy that is used to
test out Hyp while it's mounted on a Rails app.
All specs that test Rails-dependent code live inside this dummy app. You can run those specs with:
cd spec/dummyrspec spec
You can also boot up the dummy application to play around with Hyp in the browser. To run the dummy app you need to:
Run a local Postgres servercreatedb dummy_developmentcd spec/dummybundle installbundle exec rake db:migraterails s
In the future we will add a second dummy app that uses Mongoid.
You can preview the #notify_experiment_done email by starting up the dummy app and visiting the mailer preview path for that email.
Do it!
The gem is available as open source under the terms of the MIT License.