Bert In Latin aMericA
Bilma is a BERT implementation in tensorflow and trained on the Masked Language Model task under the https://sadit.github.io/regional-spanish-models-talk-2022/ datasets.
The regional models can be downloaded from http://geo.ingeotec.mx/~lgruiz/regional-models-bilma/. You will also need to download the vocabulary file which is common to all the model and regions.
The accuracy of the models trained on the MLM task for different regions are:
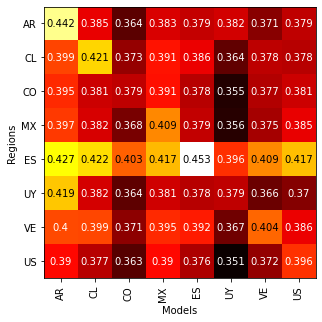
We also fine tuned the models for emoticon prediction, the resulting accuracy is as follows:

You will need TensorFlow 2.4 or newer.
You can see the demo notebooks for a quick guide on how to use the models.
Clone this repository and then run
bash download-emoji15-bilma.sh
to download the MX model. Then to load the model you can use the code:
from bilma import bilma_model
vocab_file = "vocab_file_All.txt"
model_file = "bilma_small_MX_epoch-1_classification_epochs-13.h5"
model = bilma_model.load(model_file)
tokenizer = bilma_model.tokenizer(vocab_file=vocab_file,
max_length=280)
Now you will need some text:
texts = ["Tenemos tres dias sin internet ni senal de celular en el pueblo.",
"Incomunicados en el siglo XXI tampoco hay servicio de telefonia fija",
"Vamos a comer unos tacos",
"Los del banco no dejan de llamarme"]
toks = tokenizer.tokenize(texts)
With this, you are ready to use the model
p = model.predict(toks)
tokenizer.decode_emo(p[1])
which produces the output:  each emoji correspond to each entry in
each emoji correspond to each entry in texts.