Author: Andrew O’Reilly Nugent
- Iterative
- A model representing simulations at a given location will be run and re-run many times. The collective behavior of model simulations (an ensemble) is summarised to assess the quality of the results
- Containerized
- Models have a single defined operating environment that can be run on a virtualized machine.
- Traceable
- All data and sources are given identifiers that can be used to trace the provenance of a result
- Learning
- The simulated system may be better described by an altered representation of important model processes. The composition of ensembles will change as improved models rise and fall in popularity.
A version-controlled reporting framework that works with any FLINT-based workflow and enables the comparison of findings (in the same location) between a variety of models and datasets. The FLINT Science Comparison (FSC) Working Group will be able to evaluate the effectiveness of open science models and produce incremental model modifications over time thanks to this versioning and comparison.
At a high level, this looks simple:
- FSC Working Group will deploy and maintain an open-source science model.
- Open and closed datasets will be configured and maintained over time.
- The science community is invited to review the science model and the simulation reports
- Suggestions are made to improve the quality of the simulation over time.
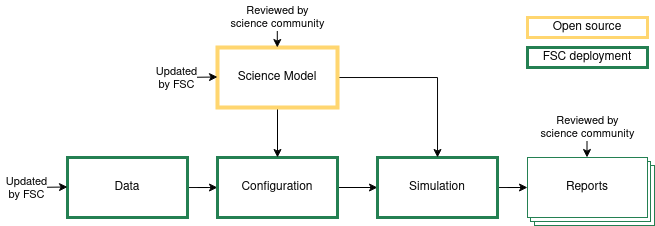
However, making the FSC assessment system last over time is a challenge. Models are frequently created for a particular report and then forgotten about. The likelihood that we will be able to provide an accurate judgment of the natural world is reduced by this long-term memory loss. We can recall a simulation at any point in the future by enlivening models using a distributed reproducibility system. Simulations that are repeated help us learn
- The FLINT computational engine runs landscape scale simulations of land use and land use change, including forest growth, harvest, and carbon flux. The FLINT can be run on local workstations, in a (commercially) managed environment, or on user-hosted cloud resources.
- The GCBM modules are one example of an open science forest model. The model requires information on forest areas, such as age, rainfall, temperature, growth rates, harvest, and disturbance records.
- Open datasets include the Hansen Forest cover dataset and the WorldClim BioClimatic datasets. Growth rates are available for some regions. Closed datasets include the site-specific growth rates and harvest and disturbance records. Forest managers typically best report forest locations/boundaries and forest age.
- An MLOps versioning system called Data Version Control (DVC). DVC records the exact model compilation and datasets used to create a specific report. It is independent of the hardware, model, or platform that created the result. DVC records ensure reproducibility, which means that the same results can be shown for an equivalent model with equivalent input data
- An ensemble is the collection of multiple reports, e.g., from different data sources or different science models, for a given location. Ensemble results can be assessed for agreement or coherence without needing access to the underlying data or computational platform that generated the result. Ensembles that agree tend to engender higher credibility than ensembles that do not agree.
- Data scientists may use local systems to execute these models. As an alternative, the generation of DVC-compliant reports can be automated using a continuous integration system (like Github Actions) whenever changes are made to the underlying dataset, such as when new data is collected. This has the potential to operate a FLINT-based open science model sustainably and efficiently. GitHub Actions can command cloud-hosted FLINT instances operating within protected environments, with access to otherwise closed data. Data does not leave the protected environment, however, a simulation record can be reported back to the open-source community for review.
- Data can be stored on cloud storage or in managed databases. Data storage may be open (e.g., Google Drive), open access, but the user pays to support hosting costs or closed. Spatially explicit data, like area boundaries and forest cover time series, are typically best stored in object storage (e.g., as files on S3). Alternatively, spatially referenced data, like harvest records for a specific forest stand (sometimes referred to as a forest coupe), can be stored in tabular databases or spreadsheets.

An overview of the steps (from top to bottom)
- A data science workflow is defined to compile simulation input
- Datasets are hosted on remote storage and indexed by DVC
- A standard report template is configured for each simulation, indexed by location
- GCBM.Belize, GCBM.Colombia, GCBM.Chile
- The automated integration system detects changes and re-runs the simulation
- Monitoring and observability services store a log of the new results
- The simulation report is publicly available from GitHub.
- a DVC Pipeline for the GCBM Science Model (link)
- metadata and version control
- a GitHub Action for the GCBM Science Model (link)
- automating integration when data/models are updated
- the GCBM Science Model in Belize using open, global data (slides)
- broad strokes template that should be globally applicable
- the GCBM Science Model in Chile using closed, local data (report)
- the report shows how models can be customized to increase accuracy
- Regionally appropriate growth and turnover parameters for Canada, Amazon, Scandinavia, Baltics, and Russia, and South East Asia
- Where growth is measured in cubic meters, an appropriate volume to biomass conversion is required
- Forest cover maps, potentially including one or more of
- Hansen et al. Global Forest Change
- Mapping by commercial remote sensing providers
- Average annual rainfall and temperature
- as described in Bioclimatic variables — WorldClim 1 documentation
- Clustering of eco-regions
- for example, using Holdridge life zones -Wikipedia
- Assessment of planting and harvest frequency
- Used to estimate initial stand age at the beginning of a simulation
- Where known, harvest regimes can be incorporated into the simulation, otherwise, a long term means harvest frequency can be used as a substitute.
- If used, an ecologically appropriate impact transition matrix
- This matrix describes the impact of management and disturbance on forest carbon stores across multiple pools
- For example, different harvesting techniques leave a varying amount of non-merchantable biomass on site.
- For example, fire can release biomass stored in post-harvest residues to the atmosphere
- Index spatially explicit simulation results by location (e.g., pixel, polygon, region), cross-referencing reports
- Reference indices: S2 Geometry , H3
- Compare the diversity of inputs (e.g., climate, forest cover) to compute the probability of the observed conditions relative to the space of possible environments
- Reward model improvements relative to simulation complexity
- Occam’s razor is given by the term 2^(−K(µ)), which weights the models’ performance in each environment inversely proportional to its complexity [Legg07; https://arxiv.org/abs/0712.3329]
- Small sample ensembles are difficult to bootstrap into a useful learning loop.
- The Optometrist algorithm [Baltz17] leverages human interpretation to guide parameter search within a fixed simulation budget [ie. Learning from human preferences]
- This approach is particularly aligned with existing international land sector reporting frameworks, which rely heavily on expert opinion and critique.