As of 2024, KataGo's is currently continuing its public distributed run, "kata1"! The website, where you can download the latest networks and find instructions to contribute if you wish, is here:
This run, continuing from the peak of KataGo's g170 run, has already improved in strength a bit, with hopefully much further room to improve. KataGo is able to win variously more than 80% or 90% of games against various classic and benchmark opponents even with a large handicap in computation power allowed, as well as performing favorably against the peak of its older 170 run. See here for some results.
Prior to opening up its first public distributed run, KataGo ran three major runs on cloud machines or clusters privately or with the help of sponsors (many thanks to Jane Street for supporting and making some of these earlier runs and the necessary experiments and testing possible!). The full history of networks and generated training data for all three of these runs is available here.
In reverse-chronological order:
KataGo's third major official run "g170" lasted from December 2019 to June 2020 for about 5 months (KataGo did not run entirely continuously during those 7 months) and reached significantly stronger than its competitors, including Leela Zero's using its strongest official 40-block nets. KataGo also took only 12-14 days to surpass its earlier 19-day "g104" run from June 2019. This is due to various training improvements which were not present in prior runs. By the end of the 5 months, it reached more than 700 Elo stronger than it. In addition to reaching stronger faster and running longer, this third run added major new features: support for Japanese rules, stronger handicap play, and more accurate score estimation.
Networks for g170 were released concurrently with major releases and development on the engine and analysis side, which can be seen in the history of the releases page. The training for g170 also included a variety of alternative and extendedly-trained neural nets which can be found here, including some smaller nets that are very strong given their size. These include a fast 10-block network that nearly matches the strength of many earlier 15 block nets, including KataGo best 15-block net from last year and Leela Zero's LZ150. And a very strong 15-block network that almost matches the strength of ELFv2, a 20-block network.
For particularly limited hardware, these small nets may be of interest to users! But note that KataGo's later networks are so vastly stronger (hundreds or even thousands of Elo) that even on weak hardware, so long as the later and larger nets are runnable at all, they likely dominate the smaller ones, even taking into account how much slower they are to evaluate.
Here is a graph of the improvement so over the course of the 157 training days of the run:
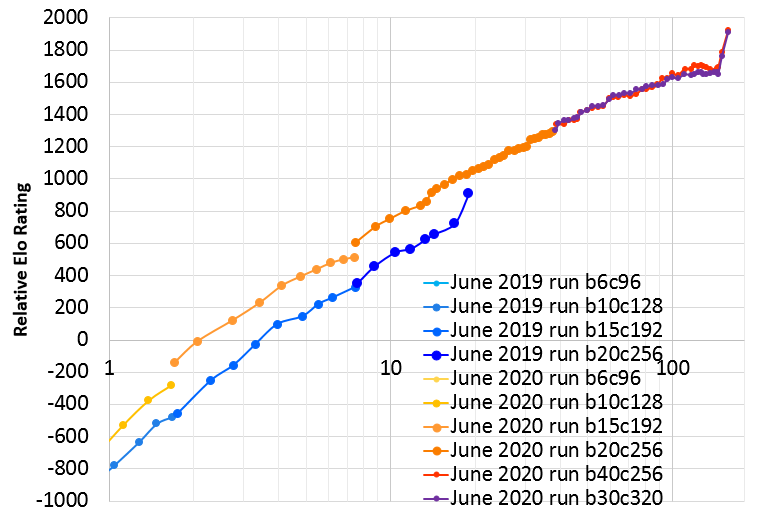 |
| X axis is days of training, log scale. (note: hardware is not entirely consistent during this time but most of the time was 44 V100 GPUs). Y axis is relative Elo rating based on some 1200-visit test matches. The abrupt jumps at the ends of each run are due to learning rate drops at the ends of those runs. The instability just before the jump in the June 2020 run, visible particularly in the 40-block Elo, is due to the last 40 days of that run being used to play with experimental changes, not all of which were improvements. 117 days is the last "clean" point prior to these changes. |
The first 117 days of the run were clean and adhered to "semi-zero" standards. In particular, game-specific input features and auxiliary training targets were used, most of which are described in KataGo's paper, and a few more here. However there was no use of outside data nor any special heuristics or expert logic encoded into the search for biasing or selecting moves, beyond some minor optimizations to end finished games a little faster. Only minimal adjustments were made to the ongoing training, via high-level hyperparameters (e.g. decaying the learning rate, the schedule for enlarging the neural net, etc). The last 40 days of the run then began to experiment with some limited ways of using external data to see the effects.
The run used about 46 GPUs for most of its duration. Of these, 40 were for self-play data generation, and up to 4 for training the main neural nets for the run, and 2 for gating games. Only 28 GPUs were used to surpass last year's run in the first 14 days. For days 14 to 38 this was increased to 36 GPUs, then from day 38 onward increased again to the current 46 GPUs, which was the number used for the rest of the run. One extra 47th GPU was used sometimes during the experimental changes in the last 40 days. Additionally, at times up to 3 more GPUs were used for training some extra networks such as extended smaller networks for end-users with weaker hardware, but these played no role in the run proper.
Just for fun, are tables of the Elo strength of selected versions, based on a few tens of thousands of games between these and other versions in a pool (1200 visits). These are based on fixed search tree size, NOT fixed computation time. For the first 117 days:
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b6c96-s175395328-d26788732 | (last selfplay 6 block) | 0.75 | -1184 |
| g170-b10c128-s197428736-d67404019 | (last selfplay 10 block) | 1.75 | -280 |
| g170e-b10c128-s1141046784-d204142634 | (extended training 10 block) | - | 300 |
| g170-b15c192-s497233664-d149638345 | (last selfplay 15 block) | 7.5 | 512 |
| g170e-b15c192-s1305382144-d335919935 | (extended training 15 block) | - | 876 |
| g170e-b15c192-s1672170752-d466197061 | (extended training 15 block) | - | 935 |
| g170-b20c256x2-s668214784-d222255714 | (20 block) | 15.5 | 959 |
| g170-b20c256x2-s1039565568-d285739972 | (20 block) | 21.5 | 1073 |
| g170-b20c256x2-s1420141824-d350969033 | (20 block) | 27.5 | 1176 |
| g170-b20c256x2-s1913382912-d435450331 | (20 block) | 35.5 | 1269 |
| g170-b20c256x2-s2107843328-d468617949 | (last selfplay 20 block) | 38.5 | 1293 |
| g170e-b20c256x2-s2430231552-d525879064 | (extended training 20 block) | 47.5 | 1346 |
| g170-b30c320x2-s1287828224-d525929064 | (30 block more channels) | 47.5 | 1412 |
| g170-b40c256x2-s1349368064-d524332537 | (40 block less channels) | 47 | 1406 |
| g170e-b20c256x2-s2971705856-d633407024 | (extended training 20 block) | 64.5 | 1413 |
| g170-b30c320x2-s1840604672-d633482024 | (30 block more channels) | 64.5 | 1524 |
| g170-b40c256x2-s1929311744-d633132024 | (40 block less channels) | 64.5 | 1510 |
| g170e-b20c256x2-s3354994176-d716845198 | (extended training 20 block) | 78 | 1455 |
| g170-b30c320x2-s2271129088-d716970897 | (30 block more channels) | 78 | 1551 |
| g170-b40c256x2-s2383550464-d716628997 | (40 block less channels) | 78 | 1554 |
| g170e-b20c256x2-s3761649408-d809581368 | (extended training 20 block) | 92 | 1513 |
| g170-b30c320x2-s2846858752-d829865719 | (30 block more channels) | 96 | 1619 |
| g170-b40c256x2-s2990766336-d830712531 | (40 block less channels) | 96 | 1613 |
| g170e-b20c256x2-s4384473088-d968438914 | (extended training 20 block) | 117 | 1529 |
| g170-b30c320x2-s3530176512-d968463914 | (30 block more channels) | 117 | 1643 |
| g170-b40c256x2-s3708042240-d967973220 | (40 block less channels) | 117 | 1687 |
Neural nets following some of the more experimental training changes in the last 40 days, where various changes to the training involving external data were tried, with mixed results:
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b30c320x2-s3910534144-d1045712926 | (30 block more channels) | 129 | 1651 |
| g170-b40c256x2-s4120339456-d1045882697 | (40 block less channels) | 129 | 1698 |
| g170e-b20c256x2-s4667204096-d1045479207 | (extended training 20 block) | 129 | 1561 |
| g170-b30c320x2-s4141693952-d1091071549 | (30 block more channels) | 136.5 | 1653 |
| g170-b40c256x2-s4368856832-d1091190099 | (40 block less channels) | 136.5 | 1680 |
| g170e-b20c256x2-s4842585088-d1091433838 | (extended training 20 block) | 136.5 | 1547 |
| g170-b30c320x2-s4432082944-d1149895217 | (30 block more channels) | 145.5 | 1648 |
| g170-b40c256x2-s4679779328-d1149909226 | (40 block less channels) | 145.5 | 1690 |
| g170e-b20c256x2-s5055114240-d1149032340 | (extended training 20 block) | 145.5 | 1539 |
Neural nets resulting from final learning rate drops. Some of the experimental uses of external data were continued here, but the large gains are most definitely due to learning rate drops rather than those uses. The last three nets in this table are KataGo's final nets from this run!
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b30c320x2-s4574191104-d1178681586 | (learning rate drop by 3.5x) | 150 | 1759 |
| g170-b40c256x2-s4833666560-d1179059206 | (learning rate drop by 3.5x) | 150 | 1788 |
| g170e-b20c256x2-s5132547840-d1177695086 | (learning rate drop by 2x) | 150 | 1577 |
| g170-b30c320x2-s4824661760-d122953669 | (learning rate drop by another 2x) | 157 | 1908 |
| g170-b40c256x2-s5095420928-d1229425124 | (learning rate drop by another 2x) | 157 | 1919 |
| g170e-b20c256x2-s5303129600-d1228401921 | (learning rate drop by another 2x) | 157 | 1645 |
And for comparison to the old 2019 June official run: (these Elos are directly measured rather than inferred, as these older networks competed directly in the same pool of test games):
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g104-b6c96-s97778688-d23397744 | (last selfplay 6 block) | 0.75 | -1146 |
| g104-b10c128-s110887936-d54937276 | (last selfplay 10 block) | 1.75 | -476 |
| g104-b15c192-s297383936-d140330251 | (last selfplay 15 block) | 7.5 | 327 |
| g104-b20c256-s447913472-d241840887 | (last selfplay 20 block) | 19 | 908 |
KataGo's g170 run as of June 2020 ended up significantly stronger than other major open-source bots in a variety of tests and conditions.
For some tests versus Leela Zero and ELF, see #254, as well as #test-results in https://discord.gg/bqkZAz3 and various casual tests run by various users in https://lifein19x19.com/viewtopic.php?f=18&t=17195 and https://lifein19x19.com/viewtopic.php?f=18&t=17474 at various points in KataGo's progression. See also the paper for test results regarding KataGo's June 2019 run ("g104") against some opponents. As a result of some further improvements, the most notable of which are documented here along with other research notes, KataGo's June 2019 run learned somewhere between 1.5x and 2x less efficiently than more recent and much better June 2020 run ("g170").
Based on some of these tests, although most of these used all different parameters and match conditions and hardware, if one were to try to put Leela Zero on the same Elo scale as in the above tables, one could maybe guess LZ272 to be very roughly somewhere between 1250 and 1450 Elo. But note also that the above Elos, due to being computed primarily by match games with earlier networks in the same run (although selected with high variety to avoid "rock-paper-scissors" issues) are likely to not be fully linear/transitive to other bots. Or even to other KataGo networks, particularly for larger differences. For example, it would not be surprising if one were to take two networks that were a large 400 Elo apart, and discover that in a direct test that the stronger one did not win quite precisely win 10 games per 1 lost game as the Elo model would predict, although one might expect still something close.
On 9x9 (KataGo's same networks can handle all common board sizes), KataGo topped the CGOS ladder in May 2020 using one V100 GPU, playing more than 100 games against other top bots including many specially-trained 9x9 bots, as well as many games against moderately weaker 9x9 bots. Against the strongest several opponents, it won close to half of these games, while losing only one game ever (the rest of the games were draws). An alternate version configured to be more aggressive and/or even to deliberately overplay won more than half of its games against the strongest opponents, drawing slightly less often at the cost of losing a few additional games.
The first serious run of KataGo, "g65", ran for 7 days in February 2019 on up to 35 V100 GPUs. This is the run featured the early versions of KataGo's research paper. It achieved close to LZ130 strength before it was halted, or up to just barely superhuman.
Following some further improvements and much-improved hyperparameters, KataGo performed a second serious run, "g104", in May-June 2019 with a max of 28 V100 GPUs, surpassing the February run after just three and a half days. The run was halted after 19 days, with the final 20-block networks reaching a final strength slightly stronger than LZ-ELFv2! (This is Facebook's very strong 20-block ELF network, running on Leela Zero's search architecture). Comparing to the yet larger Leela Zero 40-block networks, KataGo's network falls somewhere around LZ200 at visit parity, despite only itself being 20 blocks. Recent versions of the paper have been updated to reflect this run. Here is a graph of Elo ratings of KataGo's June run compared to Leela Zero and ELF based on a set of test games, where the X axis is an approximate measure of self-play computation required (note: log scale).
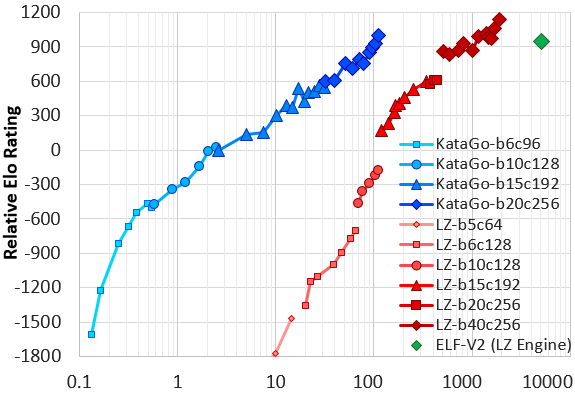 |
| June run of KataGo vs LZ and ELF. X axis is approx selfplay compute spent, log scale. Y axis is relative Elo rating. Leela Zero goes up to LZ225 on this graph. KataGo trains efficiently compared to other bots. See paper for details. |
See also https://github.com/lightvector/GoNN for some earlier research, mostly involving supervised neural net training on professional Go games. KataGo is essentially a continuation of that research, but that old repo has been preserved since the changes in this repo are not backwards compatible, and to leave the old repo intact to continue as a showcase of the many earlier experiments performed there. Several of KataGo's major improvements over AlphaZero, such as global pooling and ownership auxiliary prediction, came directly out of these experiments in neural net training and architecture.