Road to intel embree v3.9.0 and beyond #20
Comments
|
All done by this commit: 4433618 |
|
Hi, I've made a comparitive test between the older Embree 3.5 / 3.6 state and the current commit 4433618 for Embree 3.8. I obtain the following results for the different platforms: I could not identify any quality regression over previous aarch64 versions. The timings look acceptable to me. I refrain from arguing that any particular feature is x percent faster, because of the very high speed variation in the x64 results. I would not expect such major performance changes in the matured code basis. I'm unsure whether this is caused by new compiler settings, new compiler versions, lower ambient temperature on the mobile test hardware, or improvements in the code. Because of these high variations, I don't put much trust into my aarch64 timings. I would argue that we require better testing, as we discussed in #17 to reduce the uncertainty here. I did run into one compilation issue that is specific to IOS: The above-linked PDF file contains two remarks. I have noticed that some results look worse than on x64 and would argue we should investigate a bit. Please note that these issues have occurred in earlier Embree aarch64 already. I have just not noticed them earlier.
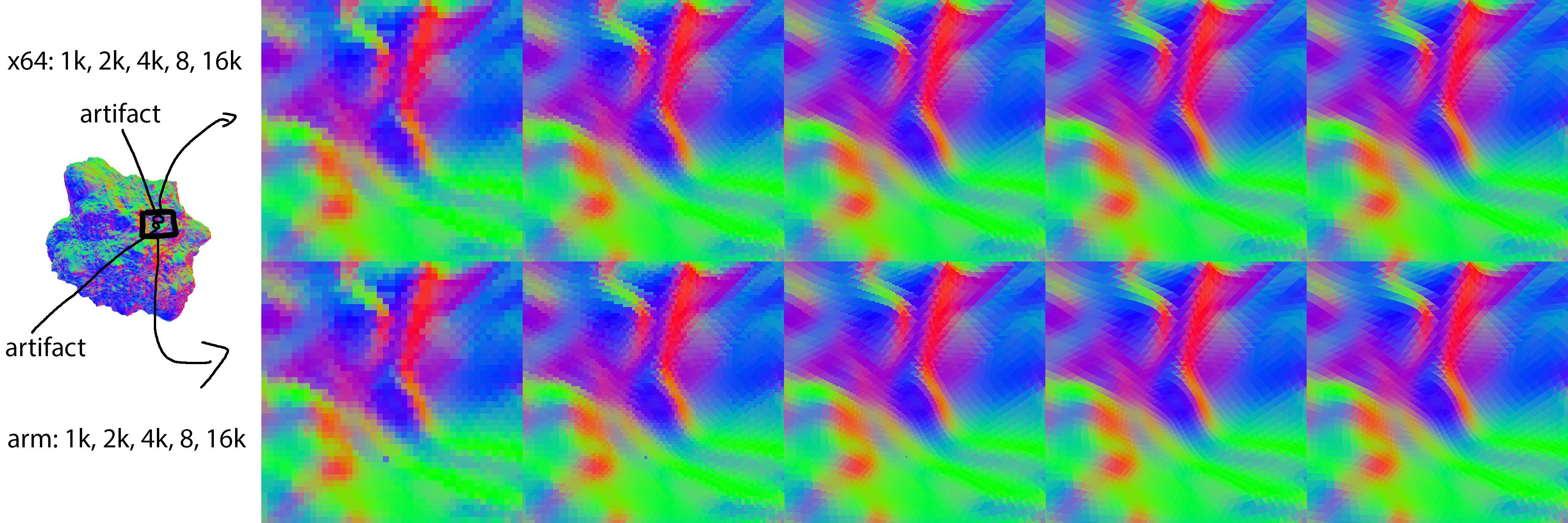
Windows x64: Android aarch64: iOS aarch64: Comparing Windows (left) to iOS (right):
Windows x64: Android aarch64: iOS aarch64: Comparing Windows (left) to iOS (right): Since these two artifacts are not located in the axis center and do not seem to occur on x64, I think it's worth to take a closer look. I will try to repro this in the original Embree tutorials with a particular camera setup. This should allow us to debug the problematic pixels. |








|
@maikschulze Awesome! As you may already know, I have added Windows CI build support for Github Actions: https://github.com/lighttransport/embree-aarch64/actions/runs/52064026 So its ready to run regression tests once your code is available. |
|
Hi, I've tried different approaches at rcp, sqrt and rsqrt precision but could not get rid off the artifact this way. I've then created higher resoluted images, up to 16K with a high contrast likelihood against the occluded backfase using color = abs(Ng). It turns out that these holes / artifacts also appear in x64. In both x64 and arm they are consistently appearing on the primitive edges. It's best to zoom in closely. The first x64 artifact appears in the second level (top row) whereas the arm artifact appear in the first level (bottom row): My data is available here: This makes me wonder whether we are seeing the following known issue: |
|
Thank you very much for the CI setup, @syoyo ! I will take a look at it and hopefully soon find the time to set up some public tests. |
@maikschulze The hole may be a bug in Embree, but may be inherent to displacement algorithm itself(e.g. the normal may face opposite direction due to insufficient sampling rate). In the latter case, we could implement reference displacement algorithm in NanoRT (https://github.com/lighttransport/nanort/tree/master/examples/vdisp ) and verify how it goes. For the former case, I'd recommend the following step to debug(what I did for debugging curve intersector of Embree)
This is a brute force way and time consuming, but should work well. |
|
Hi Syoyo, I've looked at the noise function and its effect on the surface curvature. It does not seem to create any overlap. The sampling density is sufficient, normals are not rotated inwards. The artifacts appear even when lowering the noise displacement to a very small factor, effectively resulting in a sphere-like subdivision. On x64 such a hole is reproducible with this ray: The surface's front face that should be hit is prim 4, which is indeed hit for any slight variation in ray origin or direction. Instead, for this particular ray it's missed and the back face prim 0 is hit. This setup enters: which then enters: Here, prim 4 is discarded because it fails to pass this test: I can imagine that Loader::gather is the cause here (called from GridSOAIntersector1::intersect) and may create a tiny gap between neighboring grid patches. I don't believe there's much I can do here with my limited understanding of the algorithm's numerics. Increasing the PlueckerIntersector1::intersect::eps if fed by GridSOAIntersector1 seems necessary but hacky to me if the factor is not properly determined. |
|
Hi, for the hole in the curve I have better news. While it is quite prevalent on arm, I fail to find holes on x64 curves. Moreover, I was able to fix the holes quickly by highly improving the rcp and rsqrt precision as a sanity check. Firstly, for arm the hole is reproducible in the 'interpolation' scene with this ray: When rendering with this camera: and removing everything but the curve with this shading: I get these results: x64: Comparison of x64 (left) and aarch64 (right) yields: aarch64 stabilized: Comparing x64 (left) to a 'stabilized' aarch64 (right) yields: The stabilized version contains the change of rcp and rsqrt functions like this: and four Newton-Raphson iterations inside |


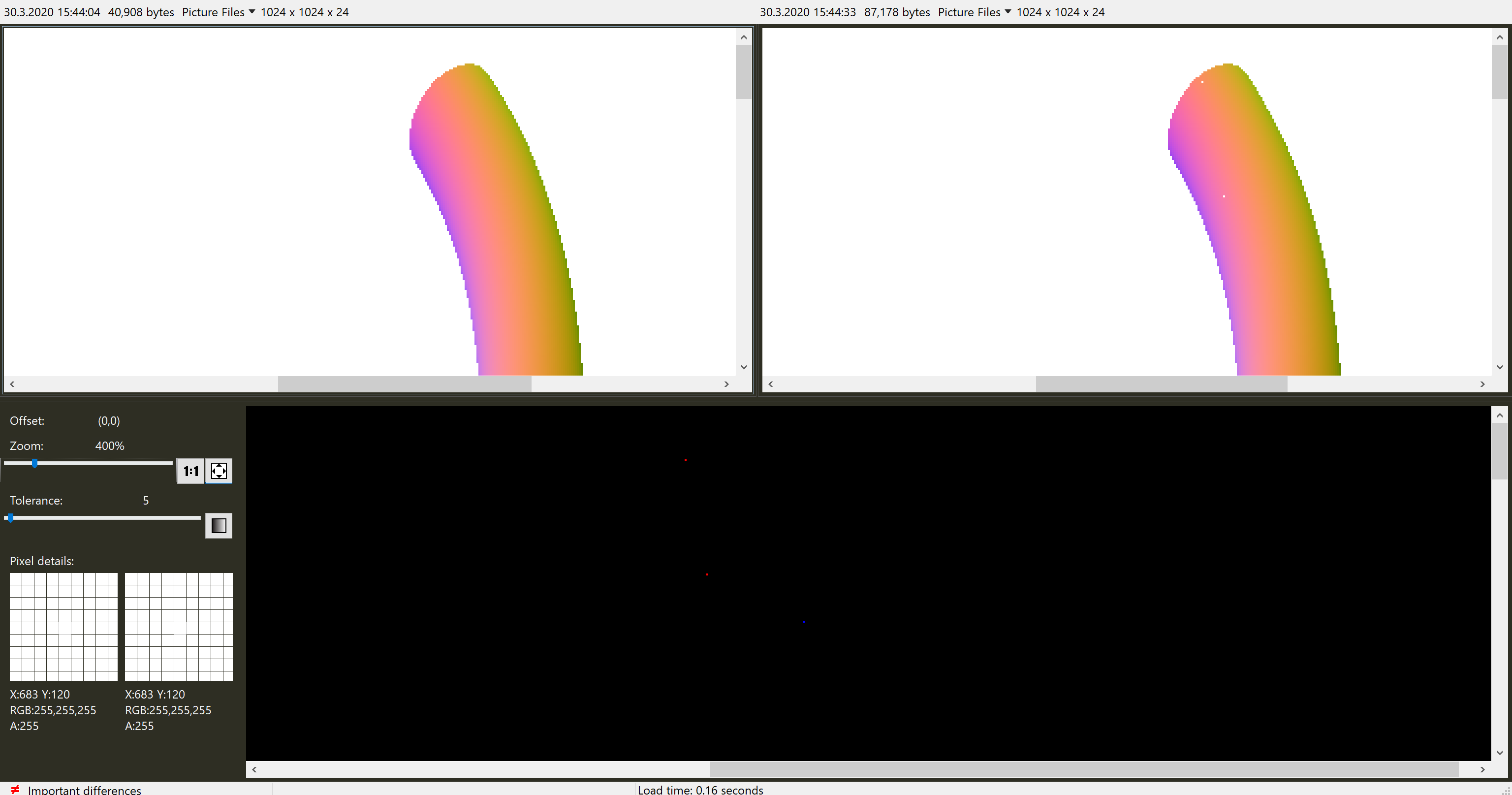


|
The issue is related to the five rsqrt functions (color, vec2, vec3, vfloat4, math): The issue appears when returning Two Newton-Raphson iterations suffice luckily. I will create a submit with the stabilizations in my fork. If we're not perfectly confident that we can skip the similar epilogue in the rcp functions, I argue we should re-add this there as well. While we still cannot guarantee water tightness without digging deep into numerical differences between SSE and NEON, I'm sure it will help with robustness. |
|
@maikschulze Good catch! > curve It looks ARM NEON's rsqrte and rcpe has less accuracy(6~8bits?) than SSE2(~12bits?), so we'll need 2x ~ 3x more rounds of Newton-Raphon iteration to get the same level of accuracy of SSE2. https://qiita.com/sanmanyannyan/items/4d06b00078dd4abc4225 I'm not sure > rsqrt equation. http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0802a/CIHDIACI.html I think using improved rsqrt and rcp also solves the displacement issue. |
The second line is exactly the equation of one round of Newton-Raphson iteration https://en.wikipedia.org/wiki/Fast_inverse_square_root#Newton's_method |
|
Filed an rcp/rsqrt issue to #24 |
|
@maikschulze Synched embree-aarch64 |
|
We are now |
neon-fixto embree-aarch64master(v3.6.1)verifysegfault on aarch64 linux #16aarch64-v3.8.0branch from intel embreev3.8.0(recent version as of writing this issue(2nd March, 2020))neon-fixtoaarch64-v3.8.0verifyfails to pass with internal tasking system #18aarch64-v3.8.0tomasterv3.9.0from Intel EmbreeNote
There are still some amount of work required for Improving NEON code path. So
neon-fixbranch will continue to alive even after syncing embree-aarch64 with intel embree v3.8.0.The text was updated successfully, but these errors were encountered: