- Что такое DWH
- Data Lake
- Витрины данных
- ETL и ETL-запросы
- Разработка ETL-процесса
- Элементы ETL-процесса
- Что такое Hadoop?
- Data Vault
- Apache Kafka
- Greenplum
- Распределенная файловая система HDFS
- MapReduce
- Pig и Hive
- NoSQL базы данных: HBase и Cassandra
- Spark
- Чем отличается PostgreSQL от ClickHouse?
- Зачем в ClickHouse на движке MergeTree прописывается ORDER BY?
- Как работает запрос на джойн таблиц в ClickHouse, если выполнять по ключу, который отсортирован и не отсортирован?
- Какие существуют архитектуры DWH?
- В чём преимущество Data Vault, если у нас происходят частые изменения на источнике?
- ETL и ELT: разница, преимущества и недостатки.
- Что выбрать, если меняется структура данных на источнике?
- Apache Flink
- Обработка потоков данных
- Lambda и Kappa архитектуры
- Microservices and Big Data
- Data Mesh
- Security in Big Data
- Data Governance
- Machine Learning with Big Data
- Cloud Solutions for Big Data
DWH — Data warehouse — Корпоративное хранилище данных (КХД) — склад всех нужных и важных для принятия решений данных компании.
Потребность в КХД сформировалась примерно в 90-х годах прошлого века, когда в секторе enterprise стали активно использоваться разные информационные системы для учета множества бизнес-показателей. Каждое такое приложение успешно решало задачу автоматизации локального производственного процесса, например, выполнение бухгалтерских расчетов, проведение транзакций, HR-аналитика и т.д.
При этом схемы представления (модели) справочных и транзакционных данных в одной системе могут кардинально отличаться от другой, что влечет расхождение информации. Кроме того, большое разнообразие моделей данных затрудняет получение консолидированной отчетности, когда нужна целостная картина из всех прикладных систем. Поэтому возникли корпоративные хранилища данных (Data Warehouse, DWH) – предметно-ориентированные базы данных для консолидированной подготовки отчётов, интегрированного бизнес-анализа и оптимального принятия управленческих решений на основе полной информационной картины.
Архитектура КХД
Вышеприведенное определение DWH показывает, что это средство хранения данных является реляционным. Однако, не стоит считать КХД просто большой базой данных с множеством взаимосвязанных таблиц. В отличие от традиционной SQL-СУБД, Data Warehouse имеет сложную многоуровневую (слоеную) архитектуру, которая называется LSA – Layered Scalable Architecture. По сути, LSA реализует логическое деление структур с данными на несколько функциональных уровней. Данные копируются с уровня на уровень и трансформируются при этом, чтобы в итоге предстать в виде согласованной информации, пригодной для анализа.
Классически LSA реализуется в виде следующих уровней:
- Операционный слой первичных данных(Primary Data Layer или стейджинг)
Здесь выполняется загрузка информации из систем-источников в исходном качестве и сохранением полной истории изменений. Здесь происходит абстрагирование следующих слоев хранилища от физического устройства источников данных, способов их сбора и методов выделения изменений. - Ядро хранилища (Core Data Layer)
Центральный компонент, который выполняет консолидацию данныхиз разных источников, приводя их к единым структурам и ключам. Именно здесь происходит основная работа с качеством данных и общие трансформации, чтобы абстрагировать потребителей от особенностей логического устройства источников данных и необходимости их взаимного сопоставления. Так решается задача обеспечения целостности и качества данных. - Аналитические витрины (Data Mart Layer)
Тут данные преобразуются к структурам, удобным для анализа и использования в BI-дэшбордах или других системах-потребителях. Когда витрины берут данные из ядра, они называются регулярными. Если же для быстрого решения локальных задач не нужна консолидация данных, витрина может брать первичные данные из операционного слоя и называется соответственно операционной. Также бывают вторичные витрины, которые используются для представления результатов сложных расчетов и нетипичных трансформаций. Таким образом, витрины обеспечивают разные представления единых данных под конкретную бизнес-специфику. - Сервисный слой (Service Layer)
Обеспечивает управление всеми вышеописанными уровнями. Он не содержит бизнес-данных, но оперирует метаданными и другими структурами для работы с качеством данных, позволяя выполнять сквозной аудит данных (data lineage), использовать общие подходы к выделению дельты изменений и управления загрузкой. Также здесь доступны средства мониторинга и диагностики ошибок, что ускоряет решение проблем.
LSA – слоеная архитектура DWH: как устроено хранилище данных

Все слои, кроме сервисного, состоят из области постоянного хранения данных и модуля загрузки и трансформации. Области хранения содержат технические (буферные) таблицы для трансформации данных и целевые таблицы, к которым обращается потребитель. Для обеспечения процессов загрузки и аудита ETL-процессов данные в целевых таблицах стейджинга, ядра и витринах маркируются техническими полями (мета-атрибутами). Еще выделяют слой виртуальных провайдеров данных и пользовательских отчетов для виртуального объединения (без хранения) данных из различных объектов. Каждый уровень может быть реализован с помощью разных технологий хранения и преобразования данных или универсальных продуктов, например, SAP NetWeaver Business Warehouse (SAP BW).
В чём разница между обычной базой данных и DWH
- Типы хранимых данных.
Обычные СУБД хранят данные строго для определенных подсистем. База данных склада хранит складские запасы и ничего более. База данных кадровиков хранит данные по персоналу, но не товары или сделки. DWH, как правило, хранит информацию разных подразделений — там найдутся данные и по товарам, и по персоналу, и по сделкам. - Объемы данных.
Обычная БД, которая ведется в рамках стандартной деятельности компании, содержит только актуальную информацию, нужную в данный момент для функционирования определенной системы. В DWH пишутся не столько копии актуальных состояний, сколько исторические данные и агрегированные значения. Например, состояние запасов разных категорий товаров на конец смены за последние пять лет. Иногда в DWH пишутся и более крупные пачки данных, если они имеют критическое значение для бизнеса — допустим, полные данные по продажам и сделкам. То есть, по сути, это копия СУБД отдела продаж. - Место в рабочих процессах.
Информация обычно сразу попадает в рабочие базы данных, а уже оттуда некоторые записи переползают в DWH. Склад данных, по сути, отражает состояние других БД и процессов в компании уже после того, как вносятся изменения в рабочих базах.
DWH — это система данных, отдельная от оперативной системы обработки данных. В корпоративных хранилищах в удобном для анализа виде хранятся архивные данные из разных, иногда очень разнородных источников. Эти данные предварительно обрабатываются и загружаются в хранилище в ходе процессов извлечения, преобразования и загрузки, называемых ETL. Решения ETL и DWH — это (упрощенно) одна система для работы с корпоративной информацией и ее хранения.
Что дают DWH-решения для BI и принятия решений в компании
Понятное дело, что просто так тратить деньги и время на консервирование кучи разных записей, которые и так можно накопать в других базах данных, никто не станет. Ответ заключается в том, что DWH необходима для того, чтобы делать BI — business intelligence.
Что такое BI с DWH? Бизнес-аналитика (BI) — это процесс анализа данных и получения информации, помогающей компаниям принимать решения.
Допустим, у вас в онлайн-магазине упала выручка. Менеджеры зовут на помощь бизнес-аналитика и просят его разобраться. Тот идет в DWH, вынимает оттуда данные по продажам, выручке, количеству пользователей, расходам — и собирает отчет, который в подробностях и с цифрами говорит о причинах падения финансовых показателей. Менеджеры внимательно смотрят на эту информацию и принимают решения по реорганизации ассортимента товаров и маркетинговых политик. Если бы такого аналитического отчета не было — управленцам пришлось бы искать проблему наугад.
Логичный вопрос: казалось бы, зачем держать для этого всего DWH? Аналитики вполне могут ходить в базы данных разных систем и просто выдергивать оттуда то, что им надо.
Ответ: так, конечно, тоже можно делать. Но — не нужно. И вот почему:
- Доступ к нужным данным.
Если компания большая, на получение данных из разных источников нужно собирать разрешения и доступы. У каждого подразделения в такой ситуации, как правило, свои базы данных со своими паролями, которые надо будет запрашивать отдельно. В DWH все нужное уже будет под рукой в готовом виде. Можно просто пойти и дернуть там необходимую статистику. - Сохранность нужных данных.
Данные в DWH не теряются и хранятся в виде, удобном для принятия решений: есть исторические записи, есть агрегированные значения. В операционной базе данных такой информации может и не быть. Например, админы уж точно не будут хранить на складском сервере архив запасов за 10 лет — БД склада в таком случае была бы слишком тяжелой. А вот хранить агрегированные запасы со склада в DWH — это нормально. - Устойчивость работы бизнес-систем.
DWH оптимизируется для работы аналитиков, а эти ребята могут запрашивать очень большие объемы информации. Если они будут делать это с помощью DWH — ничего страшного, даже если их запрос будет обрабатываться очень долго. А если запросить слишком много записей с боевой базы данных сервера — он может уйти в отказ до конца выполнения запроса от аналитики и создать проблемы для других систем. DWH исключает риск того, что аналитики что-то повесят или сломают.
Почему бизнес-аналитика невозможна без DWH
DWH и бизнес-аналитики переводят управление компаниями из искусства в науку. Имея под рукой результаты измерений по сотням показателей, можно выдвигать гипотезы и ставить эксперименты. Правильные решения легко подтверждаются объективными цифрами, которые достают аналитики из DWH.
Оптимальные управленческие решения — это не всегда максимизация прибыли. Это еще и выращивание новых производственных мощностей, минимизация негативного влияния на экологию, достойное качество жизни сотрудников, лояльность клиентов и стабильность бизнеса в долгосрочной перспективе. Все эти, казалось бы, сложные и эфемерные показатели можно анализировать с помощью BI и данных из DWH.
Без DWH и аналитиков управление бизнесом превращается в слепую езду по льду — возможно, при определенной сноровке вы попадете куда надо, но шансов улететь в сугроб или в столб все же куда больше.
(наверх)
Data Lake (Озеро данных) – это метод хранения данных системой или репозиторием в натуральном (RAW) формате, который предполагает одновременное хранение данных в различных схемах и форматах. Обычно используется blob-объект (binary large object) или файл. Идея озера данных в том чтобы иметь логически определенное, единое хранилище всех данных в организации (enterprise data) начиная от сырых, необработанных исходных данных (RAW data) до предварительно обработанных (transformed) данных, которые используются для различных задач: отчеты, визуализация, аналитика и машинное обучение.
Data Lake (озеро данных) включает структурированные данные из реляционных баз данных (строки и колонки), полуструктурированные данные (CSV, лог файлы, XML, JSON), неструктурированные данные (почтовые сообщения, документы, pdf) и даже бинарные данные (видео, аудио, графические файлы).
Data Lake (озеро данных), кроме методов хранения и описания данных, предполагает определение источников и методов пополнения данных.
При этом используются следующие термины:
- источники – sources;
- настройки каналов – pipelines;
- регулярность обновлений – schedulers;
- владельцы – custodians;
- время хранения – retention time;
- метаданные – другие “данные о данных”.
Data Lake (озеро данных) может использовать единый репозиторий в качестве хранилища данных (HDFS, EDW, IMDG, Cloud и т.д.) либо использовать модульную концепцию источников хранения данных для разных требований по безопасности, скорости, доступности при соблюдении условий хранения данных: неизменяемые RAW данные, согласованное время хранения (retention time), доступность.
В 2010-х годах, с наступлением эпохи Big Data, фокус внимания от традиционных DWH сместился озерам данных (Data Lake). Однако, считать озеро данных новым поколением КХД не совсем корректно по следующим причинам:
- Разное целевое назначение
DWH используется менеджерами, аналитиками и другими конечными бизнес-пользователями, тогда как озеро данных – в основном Data Scientist’ами. Напомним, в Data Lake хранится неструктурированная, т.н. сырая информация: видеозаписи с беспилотников и камер наружного наблюдения, транспортная телеметрия, графические изображения, логи пользовательского поведения, метрики сайтов и информационных систем, а также прочие данные с разными форматами хранения (схемами представления). Они пока непригодны для ежедневной аналитики в BI-системах, но могут использоваться Data Scientist’ами для быстрой отработки новых бизнес-гипотез с помощью алгоритмов машинного обучения; - Разные подходы к проектированию
Дизайн DWH основан на реляционной логике работы с данными – третья нормальная форма для нормализованных хранилищ, схемы звезды или снежинки для хранилищ с измерениями. При проектировании озера данных архитектор Big Data и Data Engineer большее внимание уделяют ETL-процессам с учетом многообразия источников и приемников разноформатной информации. А вопрос ее непосредственного хранения решается достаточно просто – требуется лишь масштабируемая, отказоустойчивая и относительно дешевая файловая система, например, HDFS или Amazon S3; - Цена
обычно Data Lake строится на базе бюджетных серверов с Apache Hadoop, без дорогостоящих лицензий и мощного оборудования, в отличие от больших затрат на проектирование и покупку специализированных платформ класса Data Warehouse, таких как SAP, Oracle, Teradata и пр.
Таким образом, озеро данных существенно отличается от КХД. Тем не менее, архитектурный подход LSA может использоваться и при построении Data Lake. Например, именно такая слоенная структура была принята за основу озера данных в Тинькоф-банке:
- на уровне RAW хранятся сырые данные различных форматов (tsv, csv, xml, syslog, json и т.д.);
- на операционном уровне (ODD, Operational Data Definition) сырые данные преобразуются в приближенный к реляционному формат;
- на уровне детализации (DDS, Detail Data Store) собирается консолидированная модель детальных данных;
- уровень MART выполняет роль прикладных витрин данных для бизнес-пользователей и моделей машинного обучения.
В данном примере для структурированных запросов к большим данным используется Apache Hive – популярное средство класса SQL-on-Hadoop. Само файловое хранилище организовано в кластере Hadoop на основе коммерческого дистрибутива от Cloudera (CDH). Традиционное DWH банка реализовано на массивно-параллельной СУБД Greenplum. От себя добавим, что альтернативой Apache Hive могла выступить Cloudera Impala, которая также, как Greenplum, Arenadata DB и Teradata, основана на массивно-параллельной архитектуре. Впрочем, выбор Hive обоснован, если требовалась высокая отказоустойчивость и большая пропускная способность. Подробнее о сходствах и различиях Apache Hive и Cloudera Impala мы рассказывали здесь. Возвращаясь к кейсу Тинькофф-банка, отметим, что BI-инструменты считывают данные из озера и классического DWH, обогащая типичные OLAP-отчеты информацией из хранилища Big Data. Это используется для анализа интересов, прогнозирования поведения, а также выявления текущих и будущих потребностей, которые возникают у посетителей сайта банка.
(наверх)
Витрины данных — подмножество (срез) хранилища данных, представляющее собой массив тематической, узконаправленной информации, ориентированной, например, на пользователей одной рабочей группы или департамента.
Концепция имеет ряд несомненных достоинств:
- Аналитики видят и работают только с теми данными, которые им реально нужны.
- Целевая БД максимально приближена к конечному пользователю.
- Витрины данных обычно содержат тематические подмножества заранее агрегированных данных, их проще проектировать и настраивать.
- Для реализации витрин данных не требуется высокомощная вычислительная техника. Но концепция витрин данных имеет и очень серьёзные пробелы. По существу, здесь предполагается реализация территориально распределённой информационной системы с мало контролируемой избыточностью, но не предлагается способов, как обеспечить целостность и непротиворечивость хранимых в ней данных.
(наверх)
ETL
В переводе ETL (Extract, Transform, Load) — извлечение, преобразование и загрузка. То есть процесс, с помощью которого данные из нескольких систем объединяют в единое хранилище данных.
Представьте ритейлера с розничными и интернет-магазинами. Ему нужно анализировать тенденции продаж и онлайн, и офлайн. Но бэкэнд-системы для них, скорее всего, будут отдельными. Они могут иметь разные поля или форматы полей для сбора данных, использовать системы, которые не могут «общаться» друг с другом.
И вот тогда наступает момент для ETL.
ETL-система извлекает данные из обеих систем, преобразует их в соответствии с требованиями к формату хранилища данных, а затем загружает в это хранилище.
Схема всегда выглядит так: сначала извлечение данных из одного или нескольких источников, потом их подготовка к интеграции, после этого идет загрузка, и извлеченные данные попадают в общую базу.
Проектирование и разработка процесса ETL
Процесс ETL реализуется путем либо разработки приложения ETL, либо создания комплекса встроенных программных процедур, либо использования ETL-инструментария. Приложения ETL извлекают информацию из исходных БД источников, преобразуют ее в формат, поддерживаемый БД назначения, а затем загружают в эту БД преобразованные данные.
Цель любого ETL-приложения состоит в том, чтобы своевременно доставить данные из внешних систем в систему, с которой работают пользователи. Как правило, ETL-приложения используются при переносе данных внешних источников в ХД систем бизнес-аналитики. Поэтому организация процесса ETL является составной частью проекта разработки практически любого ХД.
Проектирование и разработка etl -процесса является одной из самых важных задач проектировщика ХД.
Для ХД процесс ETL имеет следующие свойства:
- Во-первых, объем данных, который выбирается из систем источников данных и помещается в ХД, как правило, бывает достаточно большим, до десятков Гб.
- Во-вторых, процесс ETL является необходимой составной частью эксплуатации ХД. Периодичность процесса ETL определяется не только потребностью пользователя в своевременных данных, но и размером загружаемой порции данных. По оценкам специалистов, ETL-процесс может занимать до 80% времени.
- В-третьих, на разных стадиях процесса ETL формируются метаданные ХД и обеспечивается качество данных.
- В-четвертых, во время процесса ETL может произойти потеря данных, поэтому необходимо обеспечивать контроль за поступлением данных в ХД.
- В-пятых, процесс ETL обладает свойством восстанавливаемости после сбоев без потери данных.
Процесс ETL состоит из трех основных стадий:
- Извлечение данных На этой стадии отбираются и описываются данные внешних источников (начинают формироваться метаданные ХД), которые должны храниться в ХД (релевантные данные).
- Преобразование данных На этой стадии релевантные данные преобразуются в формат представления данных в ХД, правила преобразования сохраняются в метаданных ХД, формируются ключевые поля таблиц физической структуры ХД, выполняется очистка данных.
- Загрузка данных На этой стадии данные загружаются в ХД, выполняется построение агрегатов.
Подходы к реализации ETL-процесса
Существует несколько подходов к реализации процесса ETL. Общепринятый подход состоит в извлечении данных из систем источников, размещении их в промежуточной области дисковой памяти (Data Staging Area), выполнении в этой промежуточной области процедур преобразования и очистки данных, а затем загрузки данных в ХД. Размещение извлеченных данных в промежуточной области означает запись данных в БД или файлы дисковой подсистемы.
Еще один подход к реализации процесса ETL:
Преобразование данных выполняется на сервере ХД, в процессе их загрузки. Использование такого подхода определяется вычислительными возможностями сервера ХД. Обычно такой подход применяется для MPP серверов ХД.
В зависимости от того, кто извлекает данные из систем источников, реализация ETL-процесса может быть выполнена следующими способами.
- ETL-сервер периодически подключается к системам, источникам данных, опрашивает их, извлекает результаты выполнения запросов и размещает их у себя для дальнейшей обработки.
- Триггеры систем источников данных отслеживают изменения в данных и размещают измененные данные в отдельных таблицах, которые затем экспортируются на ETL-сервер.
- Специально разработанное приложение в системах источниках данных периодически опрашивает их и экспортирует данные на ETL-сервер.
- Используются log-журналы БД систем источников, которые содержат все транзакции изменения данных. Измененные данные извлекаются из log-журналов и сохраняются на сервере системы источника данных для последующего импорта в ETL-сервер.
В зависимости от того, где выполняется процесс извлечения данных из систем источников, реализация ETL-процесса может быть выполнена следующими способами.
- ETL-процесс выполняется на выделенном ETL-сервере, который располагается между системами источниками данных и сервером ХД. В этом случае процесс ETL не использует вычислительных ресурсов сервера ХД и серверов систем источников данных.
- ETL-процесс выполняется на сервере ХД. В этом случае сервер ХД должен иметь достаточное дисковое пространство для выполнения ETL-процесса, использование ресурсов сервера не должно сильно влиять на производительность запросов пользователей к ХД.
- ETL-процесс выполняется на серверах систем источников данных для ХД. В этом случае изменения в данных сразу же отражаются в ХД. Такой подход используется при разработке ХД реального времени.
Таким образом, при проектировании процесса ETL проектировщик ХД должен на основе анализа требований к функционированию ХД совместно с руководителем ИТ-проекта выбрать программно-аппаратное решение для реализации ETL-процесса, а именно – точно определить, где и каким способом будет выполняться ETL-процесс. На это решение может сильно повлиять бюджет проекта. Например, может быть недостаточно финансовых средств, чтобы реализовать процесс ETL на выделенном сервере.
ETL на практике
Современные инструменты ETL собирают, преобразуют и хранят данные из миллионов транзакций в самых разных источниках данных и потоках. Эта возможность предоставляет множество новых возможностей: анализ исторических записей для оптимизации процесса продаж, корректировка цен и запасов в реальном времени, использование машинного обучения и искусственного интеллекта для создания прогнозных моделей, разработка новых потоков доходов, переход в облако и многое другое.
Облачная миграция Процесс переноса данных и приложений в облако называют облачной миграцией. Она помогает сэкономить деньги, сделать приложения более масштабируемыми и защитить данные. ETL в таком случае используют для перемещения данных в облако.
Хранилище данных Хранилище данных — база данных, куда передают данные из различных источников, чтобы их можно было совместно анализировать в коммерческих целях. Здесь ETL используют для перемещения данных в хранилище данных.
Машинное обучение Машинное обучение — метод анализа данных, который автоматизирует построение аналитических моделей. ETL может использоваться для перемещения данных в одно хранилище для машинного обучения.
Интеграция маркетинговых данных Маркетинговая интеграция включает в себя перемещение всех маркетинговых данных — о клиентах, продажах, из социальных сетей и веб-аналитики — в одно место, чтобы вы могли проанализировать их. ETL используют для объединения маркетинговых данных.
Интеграция данных IoT То есть данных, собранных различными датчиками, в том числе встроенными в оборудование. ETL помогает перенести данные от разных IoT в одно место, чтобы вы могли сделать их подробный анализ.
Репликация базы данных — данные из исходных баз данных копируют в облачное хранилище. Это может быть одноразовая операция или постоянный процесс, когда ваши данные обновляются в облаке сразу же после обновления в исходной базе. ETL можно использовать для осуществления процесса репликации данных.
Бизнес-аналитика Бизнес-аналитика — процесс анализа данных, позволяющий руководителям, менеджерам и другим заинтересованным сторонам принимать обоснованные бизнес-решения. ETL можно использовать для переноса нужных данных в одно место, чтобы их можно было использовать.
Популярные ETL-системы
Cloud Big Data — PaaS-сервис для анализа больших данных (big data) на базе Apache Hadoop, Apache Spark, ClickHouse. Легко масштабируется, позволяет заменить дорогую и неэффективную локальную инфраструктуру обработки данных на мощную облачную инфраструктуру. Помогает обрабатывать структурированные и неструктурированные данные из разных источников, в том числе в режиме реального времени. Развернуть кластер интеграции и обработки данных в облаках можно за несколько минут, управление осуществляется через веб-интерфейс, командную строку или API.
IBM InfoSphere — инструмент ETL, часть пакета решений IBM Information Platforms и IBM InfoSphere. Доступен в различных версиях (Server Edition, Enterprise Edition и MVS Edition). Помогает в очистке, мониторинге, преобразовании и доставке данных, среди преимуществ: масштабируемость, возможность интеграции почти всех типов данных в режиме реального времени.
PowerCenter — набор продуктов ETL, включающий клиентские инструменты PowerCenter, сервер и репозиторий. Данные хранятся в хранилище, где к ним получают доступ клиентские инструменты и сервер. Инструмент обеспечивает поддержку всего жизненного цикла интеграции данных: от запуска первого проекта до успешного развертывания критически важных корпоративных приложений.
iWay Software предоставляет возможность интеграции приложений и данных для удобного использования в режиме реального времени. Клиенты используют их для управления структурированной и неструктурированной информацией. В комплект входят: iWay DataMigrator, iWay Service Manager и iWay Universal Adapter Framework.
Microsoft SQL Server — платформа управления реляционными базами данных и создания высокопроизводительных решений интеграции данных, включающая пакеты ETL для хранилищ данных.
OpenText — платформа интеграции, позволяющая извлекать, улучшать, преобразовывать, интегрировать и переносить данные и контент из одного или нескольких хранилищ в любое новое место назначения. Позволяет работать со структурированными и неструктурированными данными, локальными и облачными хранилищами.
Oracle GoldenGate — комплексный программный пакет для интеграции и репликации данных в режиме реального времени в разнородных IT-средах. Обладает упрощенной настройкой и управлением, поддерживает облачные среды.
Pervasive Data Integrator — программное решение для интеграции между корпоративными данными, сторонними приложениями и пользовательским программным обеспечением. Data Integrator поддерживает сценарии интеграции в реальном времени.
Pitney Bowes предлагает большой набор инструментов и решений, нацеленных на интеграцию данных. Например, Sagent Data Flow — гибкий механизм интеграции, который собирает данные из разнородных источников и предоставляет полный набор инструментов преобразования данных для повышения их коммерческой ценности.
SAP Business Objects — централизованная платформа для интеграции данных, качества данных, профилирования данных, обработки данных и отчетности. Предлагает бизнес-аналитику в реальном времени, приложения для визуализации и аналитики, интеграцию с офисными приложениями.
Sybase включает Sybase ETL Development и Sybase ETL Server. Sybase ETL Development — инструмент с графическим интерфейсом для создания и проектирования проектов и заданий по преобразованию данных. Sybase ETL Server — масштабируемый механизм, который подключается к источникам данных, извлекает и загружает данные в хранилища.
Open source ETL-средства
Большинство инструментов ETL с открытым исходным кодом помогают в управлении пакетной обработкой данных и автоматизации потоковой передачи информации из одной системы данных в другую. Эти рабочие процессы важны при создании хранилища данных для машинного обучения.
Некоторые из бесплатных и открытых инструментов ETL принадлежат поставщикам, которые в итоге хотят продать корпоративный продукт, другие обслуживаются и управляются сообществом разработчиков, стремящихся демократизировать процесс.
Open source ETL-инструменты интеграции данных:
Apache Airflow — платформа с удобным веб-интерфейсом, где можно создавать, планировать и отслеживать рабочие процессы. Позволяет пользователям объединять задачи, которые нужно выполнить в строго определенной последовательности по заданному расписанию. Пользовательский интерфейс поддерживает визуализацию рабочих процессов, что помогает отслеживать прогресс и видеть возникающие проблемы.
Apache Kafka — распределенная потоковая платформа, которая позволяет пользователям публиковать и подписываться на потоки записей, хранить потоки записей и обрабатывать их по мере появления. Kafka используют для создания конвейеров данных в реальном времени. Он работает как кластер на одном или нескольких серверах, отказоустойчив и масштабируем.
Apache NiFi — распределенная система для быстрой параллельной загрузки и обработки данных с большим числом плагинов для источников и преобразований, широкими возможностями работы с данными. Пользовательский веб-интерфейс NiFi позволяет переключаться между дизайном, управлением, обратной связью и мониторингом.
CloverETL (теперь CloverDX) был одним из первых инструментов ETL с открытым исходным кодом. Инфраструктура интеграции данных, основанная на Java, разработана для преобразования, отображения и манипулирования данными в различных форматах. CloverETL может использоваться автономно или встраиваться и подключаться к другим инструментам: RDBMS, JMS, SOAP, LDAP, S3, HTTP, FTP, ZIP и TAR. Хотя продукт больше не предлагается поставщиком, его можно безопасно загрузить с помощью SourceForge. CloverDX по-прежнему поддерживает CloverETL в соответствии со стандартным соглашением о поддержке.
Jaspersoft ETL — один из продуктов с открытым исходным кодом TIBCO Community Edition, позволяет пользователям извлекать данные из различных источников, преобразовывать их на основе определенных бизнес-правил и загружать в централизованное хранилище данных для отчетности и аналитики. Механизм интеграции данных инструмента основан на Talend. Community Edition прост в развертывании, позволяет создавать витрины данных для отчетности и аналитики.
Apatar — кроссплатформенный инструмент интеграции данных с открытым исходным кодом, который обеспечивает подключение к различным базам данных, приложениям, протоколам, файлам. Позволяет разработчикам, администраторам баз данных и бизнес-пользователям интегрировать информацию разного формата из различных источников данных. У инструмента интуитивно понятный пользовательский интерфейс, который не требует кодирования для настройки заданий интеграции данных. Инструмент поставляется с предварительно созданным набором инструментов интеграции и позволяет пользователям повторно использовать ранее созданные схемы сопоставления.
(наверх)
Разработка ETL-процесса Как правило, при конструировании процесса ETL для ХД придерживаются следующей последовательности действий.
- Планирование ETL-процесса, которое включает в себя разработку диаграммы потоков данных от систем-источников, определение преобразований, метода генерации ключей и последовательности операций для каждой таблицы назначения.
- Конструирование процесса заполнения таблиц измерений, которое включает в себя разработку и верификацию процесса заполнения статических таблиц измерений, разработку и верификацию механизмов изменения для каждой таблицы измерений.
- Конструирование процесса заполнения таблиц фактов, которое включает в себя разработку и верификацию процесса первоначального заполнения и периодического дополнения таблиц фактов, построение агрегатов и разработку процедур автоматизации процесса ETL.
Сначала создается обобщенный план, в котором отражается перечень систем –источников данных и указываются планируемые целевые области данных (данных, которые будут размещаться в ХД). Источник целевых данных определяется на основе сформулированных бизнес-требований к ХД. Как правило, источники данных существенно различаются: от БД и текстовых файлов до SMS-сообщений. Это обстоятельство может значительно усложнить задачу преобразования данных.
Назначение таких высокоуровневых описаний источников дает, с одной стороны, разработчикам представление и о создаваемой системе, и о существующих источниках данных, а с другой, руководству организации, — понимание сложности, связанной с процессами преобразования данных.
К составлению обобщенного плана лучше всего приступать, когда разработана многомерная модель ХД. Тогда для каждой таблицы многомерной схемы можно определить таблицы – источники данных.
На этой стадии планирования необходимо зафиксировать все обнаруженные расхождения в определениях данных и схемах кодирования.
Детальное планирование ETL-процесса во многом зависит от использования выбранных ETL-инструментов. К настоящему времени разработано достаточно много таких инструментов как компаниями производителями комплексных решений в области ХД (IBM, Oracle, MicroSoft), так и сторонними производителями программного обеспечения (Sunopsis). Поэтому задача выбора подходящих ETL-инструментов должна быть решена до того, как приступать к детальному планированию.
Программное обеспечение этого класса предназначено для извлечения, приведения к общему формату, преобразованию, очистки и загрузки данных в хранилище. Существуют два подхода к написанию ETL-процедур:
- их можно написать вручную;
- можно воспользоваться специализированными средствами ETL.
Каждый из подходов имеет ряд преимуществ и недостатков, поэтому выбор того или иного метода реализации процедур ETL определяется требованиями к подсистеме загрузки данных в каждом конкретном случае.
Написание вручную:
- возможность использования широко распространенных парадигм программирования, например, объектно-ориентированного программирования;
- возможность применения многих существующих методик и программных средств, позволяющих автоматизировать процесс тестирования разрабатываемых процедур загрузки данных ;
- доступность человеческих ресурсов;
- возможность построения наиболее производительного решения с использованием при программировании всех преимуществ систем управления базами данных (СУБД), задействованных в проекте;
- возможность построения наиболее гибкого решения.
Применение ETL-инструментов:
- упрощение процесса разработки, и, главное, процесса поддержания и модификации процедур ETL;
- ускорение процесса разработки системы, возможность использования готовых наработок, поставляемых вместе со средствами ETL;
- возможность использования встроенных систем управления метаданными, позволяющих синхронизовать метаданные между СУБД, средством ETL, а также инструментами визуализации данных;
- возможность автоматической документации написанных процедур;
- многие средства ETL предоставляют собой средства увеличения производительности подсистемы загрузки данных, которые включают в себя возможность распараллеливания вычислений на различных узлах системы, использование хеширования и многие другие.
Конструирование процесса заполнения таблиц измерений
Для таблиц измерений ХД, которые не будут изменяться со временем, в разработке процесса ETL первой основной задачей является выбор первичного ключа таблицы. Выбор ключа осуществляется проектировщиком ХД на основе анализа источников данных.
Второй основной задачей является проверка наличия в измерении отношений "один к одному" и "один ко многим". Как правило, для такой проверки используется сортировка.
Затем следует рассмотреть изменяющиеся измерения, определить тип изменений и описать процедуры работы с такими измерениями.
Загрузка таблиц измерений выполняется либо путем перезаписи таблицы измерения (для небольших по объему таблиц), либо загружаются только изменения в данных таблиц измерений.
Конструирование процесса заполнения таблиц фактов При конструировании процесса заполнения таблиц фактов проектировщик решает следующие основные задачи:
- проанализировать построенные таблицы фактов; рассмотреть процесс загрузки таблиц фактов;
- рассмотреть и проанализировать построенные агрегаты;
- рассмотреть процесс загрузки агрегатов.
Процесс загрузки таблиц фактов бывает двух типов: первоначальная загрузка и периодическая загрузка изменений.
Проблемы, связанные с первоначальной загрузкой, состоят в том, что с большой долей вероятности вы не получите корректных исторических данных из-за больших объемов данных. Поэтому важно оценить, какой тип загрузки для какой таблицы фактов подходит наилучшим образом.
(наверх)
Извлечение данных
Целью процесса извлечения данных является быстрое извлечение релевантных данных из источников данных.
Процесс извлечения данных из источников данных можно разбить на следующие основные типы:
- извлечение данных при помощи приложений, основанных на выполнении SQL-команд. Эти приложения функционируют совместно с другими приложениями систем источников данных;
- извлечение данных при помощи встроенных в СУБД механизмов импорта/экспорта данных. Использование таких механизмов, как правило, обеспечивает более быстрое извлечение данных, чем с помощью команд SQL;
- извлечение данных с помощью специально разработанных приложений.
Процесс извлечения данных может выполняться ежедневно, еженедельно или, в редких случаях, ежемесячно. Отметим, что существует целый класс систем бизнес-аналитики, которые требуют извлечения данных в режиме реального времени: например, системы, анализирующие биржевые операции (каждую секунду), или системы в области телекоммуникаций.
Процесс извлечения данных может выполняться либо в среде оперативных систем обработки данных (источников), либо в среде функционирования ХД.
Преобразование данных
Процесс преобразования данных источников включает в себя следующие основные действия.
- Преобразование типов данных:
- преобразования, связанные с кодировкой данных, например, EBCDIC -> ASCII / UniCode;
- преобразование строковых данных;
- преобразование форматов данных для представления даты или времени.
- Преобразования, связанные с нормализацией или денормализацией схемы данных:
- преобразование денормализации схемы с целью увеличения производительности выполнения запросов к ХД;
- нормализация схемы ХД с целью обеспечения простоты SQL-запросов.
- Преобразования ключей, связанные с обеспечением соответствия бизнес-ключей суррогатным ключам ХД.
- Преобразования, связанные с обеспечением качества данных в ХД.
Как правило, данные источников не обладают необходимым уровнем качества данных. Заметим, что данные в ХД должны быть:
- точными – данные должны содержать правильные количественные значения метрик или давать объяснения, почему невозможно такие значения иметь;
- полными – пользователи ХД должны знать, что имеют доступ ко всем релевантным данным;
- согласованными – никакие противоречия в данных не допускаются: агрегаты должны точно соответствовать подробным данным;
- уникальными – одни и те же объекты предметной области должны иметь одинаковые наименования и идентифицироваться в ХД одинаковыми ключами;
- актуальными – пользователи ХД должны знать, с какой частотой данные обновляются (т.е. на какую дату данные действительны).
Для обеспечения качества данные при преобразовании подвергаются процедуре очистки. Процедура очистки данных необходима, поскольку системы бизнес-аналитики не работают с несогласованными и неточными данными, иначе бизнес-анализ становится бессмысленным.
Процедура очистки данных включает в себя согласование форматов данных, кодирование данных, исключение ненужных атрибутов (например, комментариев), замещение кодов значениями (например, почтового индекса наименованием населенного пункта), комбинирование данных из различных источников под общим ключом (например, собрать все данные о покупателях), обнаружение одинаково поименованных атрибутов, которые содержат различные по смыслу значения.
Очистку данных можно разделить на следующие типы:
- конвертация и нормализация данных (приведение к одинаковому кодированию текста, форматам даты и т. д.);
- стандартизация написания имен, представления адресов, устранение дубликатов;
- стандартизация наименований таблиц, индексов и т.д.;
- очистка, основанная на бизнес-правилах предметной области.
Процедуры очистки также включают в себя создание меток статуса фактов в таблицах измерения (нормальный, ненормальный, невозможный, выходящий за границы, анализируемый или нет и т.д.), распознавание случайных и зашумленных значений (замещение их NULL-значением или оценкой), унификация использования NULL-значений, маркирование фактов с изменившимся статусом (например, покупатель аннулировал контракт), агрегирование фактов и т.п.
Загрузка данных
Основная цель процесса загрузки данных состоит в быстрой загрузке данных в ХД. Отметим некоторые особенности выполнения процесса загрузки данных в ХД.
-
Во-первых, загрузка данных, основанная на использовании команд обновления SQL, является медленной. Каждая команда SQL выполняется СУБД по определенному плану выполнения, и ее обработка включает выполнение нескольких фаз. Поэтому загрузка с помощью встроенных в СУБД средств импорта/экспорта является предпочтительной.
-
Во-вторых, индексы таблиц загружаются медленно. Во многих случаях целесообразно удалить индекс и построить его заново.
-
В-третьих, следует максимально использовать параллелизм при загрузке данных. Измерения могут производиться одновременно с фактами и секциями таблиц. Аналогично факты и секции таблиц могут загружаться одновременно с измерениями.
Следует заметить, что при загрузке данных должна быть гарантирована ссылочная целостность данных, а агрегаты должны быть построены и загружены одновременно с подробными данными.
Настройка производительности загрузки данных в ХД выполняется администратором ХД с помощью набора процедур, предусмотренных используемой СУБД.
(наверх)
Hadoop - инструмент для обработки Big Data. Hadoop - это проект Apache, является системой для распределённых вычислений. При этом эта система является масштабируемой и отказоустойчивой.
История Hadoop
Начинался как проект в Apache Nutch
В 2004 году Google публикует статьи про GFS и MapReduce
На основе этих статей формируется распределённая файловая система
Системные принципы Hadoop
- Горизонтальное (Scale-out) масштабирование вместо вертикального (Scale-Up)
- Отправление кода к данным
- Умение обрабатывать падения нод и отказы оборудования
- Инкапсуляция сложности работы распределённых и многопоточных приложений
Масштабирование
- Вертикальное
- Добавить дополнительные ресурсы к существующему железу (CPU, RAM)
- Если нельзя улучшить железо, то надо покупать более мощное новое
- Закон Мура не успевает за ростом объёма данных
- Горизонтальное
- Добавить больше машин к существующему кластеру
- Приложение поддерживает добавлние/удаление серверов
- Просто масштабировать "вниз"
(наверх)
Большинство компаний сегодня накапливают различные данные, полученные в процессе работы. Часто данные приходят из различных источников — структурированные и не очень, иногда в режиме реального времени, а иногда они доступны в строго определенные периоды. Все это разнообразие нужно структурированно хранить, чтоб потом успешно анализировать, рисовать красивые отчеты и вовремя замечать аномалии. Для этих целей проектируется хранилище данных (Data Warehouse, DWH).
Data Vault - это один из подходов к построению такого универсального хранилища.
Data Vault состоит из трех основных компонентов — Хаб (Hub), Ссылка (Link) и Сателлит (Satellite).
Хаб
Хаб — основное представление сущности (Клиент, Продукт, Заказ) с позиции бизнеса. Таблица-Хаб содержит одно или несколько полей, отражающих сущность в понятиях бизнеса. В совокупности эти поля называются «бизнес ключ». Идеальный кандидат на звание бизнес-ключа это ИНН организации или VIN номер автомобиля, а сгенерированный системой ID будет наихудшим вариантом. Бизнес ключ всегда должен быть уникальным и неизменным. Хаб так же содержит мета-поля load timestamp и record source, в которых хранятся время первоначальной загрузки сущности в хранилище и ее источник (название системы, базы или файла, откуда данные были загружены).
Таблицы Хабы

Ссылка
Таблицы-Ссылки связывают несколько хабов связью многие-ко-многим. Она содержит те же метаданные, что и Хаб. Ссылка может быть связана с другой Ссылкой, но такой подход создает проблемы при загрузке, так что лучше выделить одну из Ссылок в отдельный Хаб.
Таблица-ссылка

Сателлит
Таблицы-Сателлиты содержат все описательные атрибуты Хаба или Ссылки (контекст). Помимо контекста Сателлит содержит стандартный набор метаданных (load timestamp и record source) и один и только один ключ «родителя». В Сателлитах можно без проблем хранить историю изменения контекста, каждый раз добавляя новую запись при обновлении контекста в системе-источнике. Для упрощения процесса обновления большого сателлита в таблицу можно добавить поле hash diff: MD5 или SHA-1 хеш от всех его описательных атрибутов. Для Хаба или Ссылки может быть сколь угодно Сателлитов, обычно контекст разбивается по частоте обновления. Контекст из разных систем-источников принято класть в отдельные Сателлиты.
Таблицы-Сателлиты

Таблицы Data Vault: хабы, ссылки, спутники

Как с этим работать?

Сначала данные из операционных систем поступают в staging area. Staging area используется как промежуточное звено в процессе загрузки данных. Одна из основных функций Staging зоны это уменьшение нагрузки на операционные базы при выполнении запросов. Таблицы здесь полностью повторяют исходную структуру, но любые ограничения на вставку данных, вроде not null или проверки целостности внешних ключей, должны быть выключены с целью оставить возможность вставить даже поврежденные или неполные данные (особенно это актуально для excel-таблиц и прочих файлов). Дополнительно в stage таблицах содержатся хеши бизнес ключей и информация о времени загрузки и источнике данных.
После этого данные разбиваются на Хабы, Ссылки и Сателлиты и загружаются в Raw Data Vault. В процессе загрузки они никак не агрегируются и не пересчитываются.
Business Vault — опциональная вспомогательная надстройка над Raw Data Vault. Строится по тем же принципам, но содержит переработанные данные: агрегированные результаты, сконвертированные валюты и прочее. Разделение чисто логическое, физически Business Vault находится в одной базе с Raw Data Vault и предназначен в основном для упрощения формирования витрин.
Когда нужные таблицы созданы и заполнены, наступает очередь витрин данных (Data Marts). Каждая витрина это отдельная база данных или схема, предназначенная для решения задач различных пользователей или отделов. В ней может быть специально собранная «звезда» или коллекция денормализованных таблиц. Если возможно, таблицы внутри витрин лучше делать виртуальными, то есть вычисляемыми «на лету». Для этого обычно используются SQL представления (SQL views).
Заполнение Data Vault
Cначала загружаются Хабы, потом Ссылки и затем Сателлиты. Хабы можно загружать параллельно, так же как и Сателлиты и Ссылки, если конечно не используется связь link-to-link.
Есть вариант и вовсе выключить проверку целостности и загружать все данные одновременно. Как раз такой подход соответствует одному из основных постулатов DV — «Загружать все доступные данные все время (Load all of the data, all of the time)» и именно здесь играют решающую роль бизнес ключи. Суть в том, что возможные проблемы при загрузке данных должны быть минимизированы, а одна из наиболее распространенных проблем это нарушение целостности. Подход, конечно, спорный, но лично я им пользуюсь и нахожу действительно удобным: данные все равно проверяются, но после загрузки. Часто можно столкнуться с проблемой отсутствия записей в нескольких Хабах при загрузке Ссылок и последовательно разбираться, почему тот или иной Хаб не заполнен до конца, перезапуская процесс и изучая новую ошибку. Альтернативный вариант — вывести недостающие данные уже после загрузки и увидеть все проблемы за один раз. Бонусом получаем устойчивость к ошибкам и возможность не следить за порядком загрузки таблиц.
Преимущества и недостатки
[+] Гибкость и расширяемость.
С Data Vault перестает быть проблемой как расширение структуры хранилища, так и добавление и сопоставление данных из новых источников. Максимально полное хранилище «сырых» данных и удобная структура их хранения позволяют нам сформировать витрину под любые требования бизнеса, а существующие решения на рынке СУБД хорошо справляются с огромными объемами информации и быстро выполняют даже очень сложные запросы, что дает возможность виртуализировать большинство витрин.
[+] Agile-подход из коробки.
Моделировать хранилище по методологии Data Vault довольно просто. Новые данные просто «подключаются» к существующей модели, не ломая и не модифицируя существующую структуру. При этом мы будем решать поставленную задачу максимально изолированно, загружая только необходимый минимум, и, вероятно, наша временнáя оценка для такой задачи станет точнее. Планирование спринтов будет проще, а результаты предсказуемы с первой же итерации.
[–] Обилие JOIN'ов
За счет большого количества операций join запросы могут быть медленнее, чем в традиционных хранилищах данных, где таблицы денормализованы.
[–] Сложность.
В описанной выше методологии есть множество важных деталей, разобраться в которых вряд ли получится за пару часов. К этому можно прибавить малое количество информации в интернете и почти полное отсутствие материалов на русском языке (надеюсь это исправить). Как следствие, при внедрении Data Vault возникают проблемы с обучением команды, появляется много вопросов относительно нюансов конкретного бизнеса. К счастью, существуют ресурсы, на которых можно задать эти вопросы. Большой недостаток сложности это обязательное требование к наличию витрин данных, так как сам по себе Data Vault плохо подходит для прямых запросов.
[–] Избыточность.
Довольно спорный недостаток, но я часто вижу вопросы об избыточности, поэтому прокомментирую этот момент со своей точки зрения.
(наверх)
Кафка - это распределённое, отказоусойчивое, горизонтально масштабируемое хранилище, основной структурой данных в котором является append-only лог, которое поддерживает потоковую обработку данных и имеет развитую экосистему коннектеров для интеграции с базами данных и другими хранилищами
Apache Kafka - в силу своей архитектуры Kafka может быть и базой данных, и системой очередей и платформой для потоковой обработки данных.
С одной стороны кафка позваляет публиковать потоки данных, сообщения, метрики, логи или картинки и с другой стороны подписываться. При этом кафка умеет справляться практически с любыми объемами информации, отлично масштабируется горизонтально, хранит все данные на диске, обладает высокой отказоустойчивостью.
Распределённое хранилище - это система, которая как правило работает на нескольких машинах, каджая из этих машин в свою очередь является кусочком хранилища. Для пользователя это все представляется в виде единого целого.
Горизонтальное масштабирование - эта техника позволяющая обеспечивать работоспособность системы даже в случае увеличенной нагрузки. Путём добавляния машин.
Потоковая обработка данных - получение на входе некого непрерывно-пополняющегося набора данных, такая же непрерывная обработка этих данных и подача результата на выход.
Kafka vs Queue
Системы очередей обычно состоят из 3х базовых компонентов:
- Сревер
- Продюсер - отправляет сообщения в именнованную очередь
- Консюмер - считывает сообщения (pull и push)
Жизненный цикл сообщений в системе очередей:
- Продьюсер отправляет сообщение на сервер
- Консьюмер фетчит сообщение и его уникальный идентификатор сервера
- Сервер помечает сообшение
- Консьюмер обрабатывает сообщение следую некой бизнес логике
- Отправляет запрос обратно на сервер либо подтверждая успешную обработку сообщения, либо сигнализирую об ошибке
- В случае успеха, сообщение удаляется с сервера навсегда
- В случае неудаче сообщение отправляется другому консьюмеру
Отличие кафки от очередей - то как сообщения хранятся на сервере(брокере) и как отправляются консьюмерам. Сообщения в кафке не удаляются по мере обработки консьюмерами, данные в кафе хранятся сколько угодно. Одно и тоже сообщение может быть обработано несколько раз разными консьюмерами и в разных контекстах.
Структура данных
Каждое сообщение состоит из:
- Ключа (key)
- Значения (Value)
- Timestamp
- Опциональный набор метаданных (Headers)
Партиция - распределённый отказоустойчивый лог
Сообщения хранятся в именнованных топиках, каждый топик состоит мз одной и более партицей, распределёных между брокерами внутри одного кластера. Это важно для горизонтального масштабирования кластера, так как она позволяет клиентам писать и читать сообщения с нескольких брокеров одновременно. Когда новое сообщение добавляется в топик, оно записывается в одну из партицей этого топика. Сообщения с одинаковыми ключами записываются в одну и туже партицию. У каждой партиции есть лидер, или брокер, который работает с клиентами лидер принимает сообщения от продьюсеров и отдаёт консьюмерам.
(наверх)
В основе Greenplum две вещи:
- база данных PostgreSQL;
- архитектурная концепция MPP.
MPP — massively parallel processing, или массивно-параллельная обработка данных. Такая архитектура весьма сложно устроена под капотом, но ее можно свести к простому концептуальному описанию. Это умная автоматическая разбивка данных по разным серверам (шардинг) с умной автоматической системой выполнения запросов к этим данным. Всё вместе это позволяет хранить петабайты записей и выполнять запросы к ним за вполне разумный срок.
Разбивку большого количества данных по серверам базы данных (шардинг) можно сделать и руками, например, первый миллион записей хранится на первом сервере, а второй на втором. Если сразу всем клиентам системы понадобится прочитать записи с одного сервера — этот сервер может не выдержать. Масштабировать такую систему тоже очень сложно.
Greenplum берет на себя все эти заботы и организует шардирование своими силами, заботясь обо всех нюансах. А еще Greenplum можно настраивать на различные стратегии выполнения запросов, ориентируясь на количество записей, количество процессоров и памяти на каждой машине.
Greenplum поддерживает реляционную модель данных, сохраняет неизменность данных, поэтому ее можно применять для данных, чувствительных к точности и структурности. Например, для финансовых операций. Greenplum — хороший выбор для банков, ритейла и других компаний, где проводят большое число транзакций и их нельзя потерять.
От систем типа ClickHouse Greenplum отличается сферой применения. Если Clickhouse больше подходит для статистики, то Greenplum намного ближе к полноценной СУБД с индексами и хитрыми запросами. Это позволяет быстрее обращаться к определенным записям. При этом Greenplum справляется с аналитическими нагрузками от бизнес-аналитики до машинного обучения. Сама система за хранение данных не отвечает, для этих целей она использует PostgreSQL.
Главное отличие между PostgreSQL и Greenplum заключается в следующем:
- архитектура – Greenplum реализует массивно-параллельную обработку без разделения ресурсов, а PostgreSQL – классическую клиент-серверную технологию. В Greenplum для повышения надежности к типовой топологии master-slave добавлен резервный главный сервер (Secondary master instance), включаемый вручную при отказе основного мастера.
- структура хранения данных. Greenplum – это одновременно хранилище данных и база транзакционных или операционных данных с распараллеливанием вычислительных процессов и хранения информации в нескольких экземплярах PostgreSQL на разных физических серверах с функцией колоночного хранения и сжатия.
- сценарии применения. Greenplum предназначен для одновременной обработки транзакционных событий обработки и отлично подходит для обширной OLAP-аналитики больших данных. PostgreSQL – хороший вариант для баз данных небольшого размера с OLTP-кейсами.
(наверх)
HDFS (Hadoop Distributed File System) - это распределённая файловая система в hadoop. Как и любая другая файловая система она служит для хранения данных.
HDFS:
- Работает на кластере серверов
- Для пользователя как "Один большой диск"
- Работает поверх обычных файловых систем (ext3, ext4, XFS)
- Не теряет данные если выходят из строя диски или сервера
HDFS подходит для:
- Хранения больших данных
- Терабайты, петабайты
- Миллионы файлов
- Файлы размером от 100 Мбэ
- Стриминга данных
- Паттерн "write once / read many times"
- Оптимизация под последовательное чтение
HDFS не подходит для:
- Low-latency reads
- Высокая пропускная способность вместо быстрого доступа к данным
- HBase помогает решить эту задачу
- Большого количество небольших файлов
- Лучше миллион больших файлов, чем миллиард маленьких
- Многопоточная запись
- Один процесс записи на файл
- данные дописываются в конец файла
Демоны HDFS

Namenode
Отвечает за:
- Файловое пространство
- Мета-информацию
- Расположение блоков файлов
Запускается на 1й выделенной машине
Datanode
Отвечает за:
- Хранение и передачу блоков данных
- Отправку сообщений о состоянии на Namenode
Запускается на каждой машине кластера
Файлы и блоки
- Файлы в HDFS состоят из блоков
блок - еденица хранения данных - Управление через Namenode
- Хранится в Datanode
Реплицируются по машинам в процессе записи:
-
Один и тот же блок хранится на нескольких Datanode
-
Фактор репликации по умлочанию равен 3
-
Это нужно для fault-tolerance и упрощения доступа
-
Стандартный размер блоков 64 Мб или 128 Мб
-
Основной мотив этого - снизить стоимость seek time по сравнению со скоростью передачи данных (transfer rate)
Репликация блоков
- Namenode определяет, где распологать блоки
- Баланс между надёжностью и производительностью
- Попытка снизить нагрузку на сеть
- Попытка улучшить надёжность
Фактор репликации по умлочанию равен 3
- 1-я реплика на локальную машину
- 2-я реплика на другую машину из той же стойки
- 3-я реплика на другую машину из другой стойки
Namenode Использование памяти
Чем больше кластер, тем больше ОЗУ требуется Больше размер блока -> меньше блоков Меньше блоков -> больше файлов в FS
Если Namenode падает, то HDFS не работает Namenode - это едина точка отказа Она должна быть на отдельной надёжной машиной.
Доступ к HDFS
- Direct Access
- Взаимодействует с HDFS с помощью нативного клиента
- Java, C++
- Клиент запрашивает метаданные от NN
- Клиент напрямую запрашивает данные от DN
- Используется для MapReduce
- Через Proxy Server
- Доступ к HDFS через Proxy Server - middle man
- ответ в форматие JSON, XML
- Серверы REST, Thrift и Avro - механизм сериализации
(наверх)
Для работы с HDFS через командную строку
$hdfs dfs (значит, что будем работать непосредственно с фаловой системой) -<command> -<option><URL>
$hdfs dfs -ls / (листинг корневой директории)
URI
hdfs://localhost:8020/user/home
Для того чтобы ссылка считалась URI необходимо наличие:
- либо scheme+authority+path,
- либо sheme+path,
- либо только path.
Вывод списка команд
$hdfs dfs - help
Информация по командк
$hdfs dfs - help <command>
Основные команды в shell
ls - листинг директории и статистика файлов
mkdir - создать директорию
$hdfs dfs -mkdir /data/new_path
cat - вывод источника в stdout
- Весь файл:
$hdfs dfs -cat /dir/file.txt - Полезно вывод перенаправить через pipe в less, head, tail и т.д.
- Получить первые 100 строк из файла:
$hdfs dfs -cat /dir/file.tx | head -n 100
text - аналог команды cut, который разархивирует архивы
tail - выводит последние сроки файла
$hdfs dfs -cat /dir/file.tx | tail - плохо
$hdfs dfs -tail /dir/file.tx - хорошо
cp - копировать файл из одного места в другое
$hdfs dfs -cp /dir/file1 /otherDir/file2
Подходит только для небольших файлов
distcp - копирует большие файлы, или много файлов
$hdfs dfs -distcp /dir/file1 /otherDir/file2
mv - перемещения файла
$hdfs dfs -mv /dir/file1 /dir2
put(copyFromLocal) - копирование локального файла в HDFS
$hdfs dfs -put loaclfile /dir/file
get(copyToLocal) - копирование файла bp HDFS в локальную FS
$hdfs dfs -get /dir/file loaclfile
rm - удалить файл в корзину
$hdfs dfs -rm /dir/file
rm -r - рекурсивно удалить директорию
$hdfs dfs -rm -r /dir
du - размер файла или директории в байтах
$hdfs dfs -du /dir
du -h - размер в удобно читаемом формате
$hdfs dfs -du -h /dir
fsck - проверка некосистентности файловой системы. Показывает проблемы. Не устраняет проблем, только информация.
$hdfs fsck <path>
dfsadmin - команда для администрирования HDFS
$hdfs dfsadmin -<command>
$hdfs dfsadmin -report - отображает статистику по HDFS
$hdfs dfsadmin -safemode - включение безопасного режима
balancer - балансирует блоки HDFS по серверам
(наверх)
Файловая система реализуется в Java Api с помощью абстрактного класса FileSystem org.apache.hadoop.fs.FileSystem Абстракный класс представляет абстрактную фаловую систему Это именно класс, а не интерфейс
Hadoop представляет несколько конкретных реализаций:
- org.apache.hadoop.fs.LocalFileSystem Подходит для нативных FS, использующих локальные диски
- org.apache.hadoop.hdfs.DistributedFileSystem Реализация распределённой фаловой системы HDFS
- org.apache.hadoop.hdfs.HftpFileSystem Доступ к HDFS в read-only режиме через HTTP
- org.apache.hadoop.fs.ftp.FTPFileSystem Файловая система поверх FTP-сервера
Объект Path представляет файл или директорию Path - это URI в FS
Объект Configuration
Объект Configuration хранит конфигурацию сервера и клиента
Использует простую парадигму key-value
Чтение данных из файла
- Создать объект FileSystem
- Открыть InputStream, указывающий на path
- Скопировать данные по байтам используя IOUtils
- Закрыть InputStream
Запись данных в файл
- Создать объект FileSystem
- Открыть OutputStream
- Указываем на Path из FileSystem
- Используем FSDataOutputStream
- Автоматически создаются все директории в пути, если не существуют
- Копируем данные по байтам использую IOUtils
Создание объекта path класса Path для файла /data/logs.txt, расположенного в HDFS (демон NameNode работает на сервере server0, порт 9000)
Path path = new Path("hdfs://server0:9000/data/logs.txt");
(наверх)
MapReduce - модель распределённых вычислений для обработки больших объёмов данных MapReduce - не алгоритм, мы можем говорить, что алгоритмы могут быть реализованы с помощью MapReduce MapReduce используется, когда для вычислений не хватает памяти и возникает необходимость проведения паралельных вычислений
Map - обработка данных
Reduce - свёртка данных
Схема MapReduce
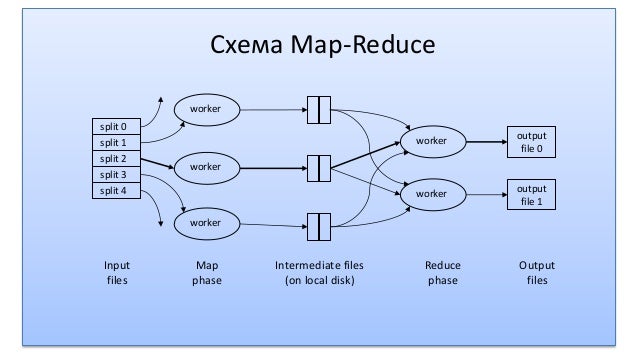
Входные данные
- Входные данные должны быть разделяемы
- Данные в каждом split должны быть независимы
- Один воркер обрабатывает один сплит
- Воркер запускается там, где лежит его сплит
Передача данных между Map и Reduce
- Промежуточные данные пишутся на локальный диск, а не в HDFS
- Для каждого редьюсера маппер создаёт свой файл с данными
- Данные - это пара (Key, Value)
- Данные с одним ключом попадают на один редьюсер
- Редьюсеры начинают работать после завершения всех мапперов

Результат MapReduce задачи
- Каждый редьюсер пишет в один файл
- Число редьюсеров задаёт пользователь
- Данные сохраняются в HDFS
- Данные вида Key -> Value
- Формат данных определяется пользователем
Фреймворк MapReduce обеспечивает:
- Подготовку данных
- Запуск всех нужных воркеров
- Взаимодействие между маппером и редьюсером
- Обработку ошибок
Работа демонов в MapReduce
MapReduce в Hadoop-е основан на HDFS-е, это означает, что на нашем кластере есть машины, сервера, на которых запущены демоны datanode, непосредственно демоны файловой системы HDFS. Работают поверх локальной файловой системы линукс и обсепечивают взаимодействие с фаловой системой HDFS. Кроме того есть отдельный сервер на котором находится демон namenode, не хранит данные, но отвечает за хранение метаинформации (блоки каких файлов где хранятся). В MapReduce существует два типа демонов:
- jobtracker - это процесс который в целом отвечает за запуск задачи.
- tasktracker - запущен на каждой машине кластера. Отвечает за запуск конкретных воркеров на конкретном сервере.
Обычно в кластере располагают tasktracker и datanode совместно, таким образом обеспечивается наилучшее взаимодействие между HDFS и MapReduce в Hadoop-е
jobtracker
- Управляет запуском тасков и определяет, на каком tasktracker будет запущен воркер
- Управляет процессом работы MapReduce задач (jobs)
- Мониторит прогресс выполнения задач
- Перезапускает зафейленные или медленные таски
tasktracker
- Отвечает за работу всех worker на одном сервере
- Получает от jobtracker информацияю о том какой worker на каких данных нужно запустить
- Посылает в jobtracker статистику о прогруссе выполненения задачи
- Сообщает в jobtracker об удачном завершении или падении воркера
Система слотов
- Для каждого tasktracker определяется число слотов
- Таск запускается на одном слоте
- M маппером + R редьюсеров = N слотов
- Для каждого слота определяется кол-во потребляемой ОЗУ
Опциональные функции
- partition (k2, v2, |reducers|) -> № of reducer
- распределяет ключи по редьюсерам
- часто просто хеш от key: hash(k2) mod n
- combine
- Мини-reducers которые выполняются после завершения фазы map
- Используется в качетсве оптимизации для снижения сетевого трафика на reduce
- Не должен менять тип ключа и значения
(наверх)
Hadoop Streaming:
- Используется стандартный механизм ввода/вывода в Unix для взаимодействия программы и Hadoop
- Разработка MR задачи почти на любом языке программирования
- Обычно используется:
- Для обработки текста
- При отсутствии опыта программирования на Java
- Для быстрого написания прототипа
Streaming в MapReduce
- На вход функции
map()данные подаются через стандартный ввод - В
map()они обрабатываются построчно - Функция
map()пишет парыkey/value, разделяемые через символ табуляции, в стандартный вывод - На вход функции
reduce()данные подаются через стандартный ввод, отсортированный по ключам - Функция
reduce()пишет парыkey/valueв стандартный вывод
Запуск задачи через Streaming Framework
hadoop jar $HADOOP_HOME/hadoop/hadoop-streamin.jar \
-D mapred.job.name="Name of job" \ Название задачи
-files smthMap.py, smthReduce.py \ Файлы, которые нужно донести
-input inputfile.txt Входные данные
-output /tmp/Name of job/ \ Куда записывать
-mapper smthMap.py \
-combiner smthReduce.py \
-reducer smthReduce.py
(наверх)
При разработке MapReduce программ необходимо реализовывать одни и теже алгоритмы для разных наборов данных. С помощью эти программ можно запустить MapReduce программы для анализа данных.
(наверх)
Pig - высокоуровневая платформа поверх Hadoop, разработан в Yahoo! в 2006 году
- Язык программирования высокого уровня Pig Latin
- Код программы преобразуется в MapReduce задачи
Для чего нужен Pig?
- Для написания задач MapReduce требуются программисты
- Которые должны уметь думать в стиле "map&reduce"
- Скорее всего должны знать язык Java
- Pig предоставляет язык, который могут использовать:
- Аналитики
- Data scientist-ы
- Статистики
Основные возможности Pig
- Join Datasets
- Sort Datasets
- Filter
- Data Types
- Group By
- Пользовательские функции
Компоненты Pig
- Pig Latin - набор команд, разработан для описания последовательности преобразования данных
- Компидятор Pig - преобразует программы на языке Pig Latin в mapReduce задачи
- Среда выполнения
Режимы выполнения
- Local
- Запускается в рамках одной JVM
- Работает исключительно с локальной файловой системой
$pig -x local
- Hadoop(MapReduce)
- Pig преобразует программу Pig Latin в задачи MapReduce и выполняет их на кластере
$pig -x mapreduce
Запуск Pig
- Скрипт
- Выполняются команды из файла
$pig script.pig
- Grunt
- Интерактивная оболочка для выполнения команд Pig
- Можно запускать скрипты из Grunt командной run или exec
- Embedded
- Можно выполнять команды Pig, используя класс PigServer
- Имеется программный доступ к Grunt через класс PigRunner
Pig Latin
Строительные блоки
- Field (поле) - часть данных
- Tuple (кортеж) - упорядоченный набор полей, заключённый в скобки "( )"
- Bag (мешок) - коллекция кортежей, заключённная в скобки "{ }"
Схожесть с реляционными БД
- Bag - это таблица БД
- Tuple - это строка в таблице
- Но: Bag не требует, чтобы все tuples содержали одно и тоже число полей
Операции DUMP и STORE
- DUMP - выводит результат на экран
- STORE - сохраняет результаты (обычно в файл)
Загрузка в файл
LOAD 'data' [USING function][AS schema];
(наверх)
Apache Hive – это SQL интерфейс доступа к данным для платформы Apache Hadoop. Hive позволяет выполнять запросы, агрегировать и анализировать данные используя SQL синтаксис. Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными, как с обыкновенной таблицей или реляционной СУБД. Запросы HiveQL транслируются в Java-код заданий MapReduce.
Запросы Hive создаются на языке запросов HiveQL, который основан на языке SQL, но не имеет полной поддержки стандарта SQL-92. Однако, этот язык позволяет программистам использовать их собственные запросы, когда неудобно или неэффективно использовать возможности HiveQL. HiveQL может быть расширен с помощью пользовательских скалярных функций (UDF), агрегаций (UDAF кодов), и табличных функций (UDTF).
HiveQL отличается от стандартного SQL, в частности :
- разные способы определения операций join для максимальной производительности;
- в HiveQL нет некоторых функций, операций и операторов SQL (UPDATE и DELETE statements, INSERT для отдельных строк);
- HiveQL позволяет вставлять пользовательский код для ситуаций, которые не вписываются в типовой SQL, предоставляя соответствующие инструменты для обработки входа и выхода – определенные пользователем функции: User Defined Function (UDF), User Defined Aggregate Function (UDAF), User Defined Tabular Function (UDTF);
- HiveQL не поддерживает типы данных даты и времени, т.к. они рассматриваются как строки.
Особенности улья:
- Масштабируемость: масштабируемость кластера hadoop
- Масштабируемость: поддержка пользовательских функций
- Отказоустойчивость: хорошая отказоустойчивость
архитектура улья:
- Пользовательский интерфейс: напишите оператор sql и отправьте его в улей
- Синтаксический анализатор: компилятор, скомпилируйте наш оператор sql в программу mapreduce
- Оптимизатор, оптимизируйте оператор sql
- Исполнитель: отправить задачу mapreduce, выполнить
- База данных метаданных: метаданные куста содержат отношения сопоставления между таблицами и данными hdfs. По умолчанию используется derby, вместо этого обычно используется mysql.
Как в большинстве СУБД, в Hive есть несколько способов запуска SQL-запросов [5]:
- интерфейс командной строки – Hive Shell (CLI, Command Line Interface);
- подключение к БД через JDBC или ODBC с помощью драйвера Hive;
- использование клиента, установленного на уровне пользователя (среднее звено классической трехуровневой архитектуры). Этот клиент общается с сервисами Hive, работающими на сервере. Такой подход можно применять в приложениях, написанных на разных языках (C++, Java, PHP, Python, Ruby), используя эти клиентские языки со встроенным SQL для доступа к базам данных. По сути, таким образом реализуется web-UI Хайв.
Hive включает в себя следующие обязательные компоненты:
- HCatalog для управления таблицами и хранилищами Hadoop, который снабжает пользователей различными инструментами обработки больших данных, включая MapReduce и Apache Pig для более простого чтения и записи данных.
- WebHCat предоставляет сервисы, которые можно использовать для запуска задач Hadoop MapReduce, Pig, заданий (jobs) или операций с метаданными Hive с помощью интерфейса HTTP в стиле REST.
(наверх)
Как хранить данные?
- Память
- Файлы
- Базы
Память: плюсы
- Широкий выбор структур данных
- Возможность создавать свои типы данных
- Быстрый доступ к данным: чтение, изменение, дополнение
Память: минусы
- Размер данных ограничен оперативной памятью
- Данные сущетсвуют пока жив процесс
- Нужно реализовывать механизмы одновременного доступа
- Низкая надёжность
Память: примеры
- Игра на Dendy
- Компиляторы
- Word, Excel
- IDE
Файлы: плюсы
- Существенно больший объём данных
- Свобода в формате и структуре данных
- Простые механизмы доступа к данным в файле
- Отсутствие третьей стороны при работе с данными
Файлы: минусы
- Сложно вносить изменения в файл
- Медленный доступ к данным
- Тяжело организовать совместный доступ к данным
- Отсутствие контроля целостности данных
- Сложные механизмы доступа к данным, расположенным в нескольких файлах
Файлы: примеры
- Игры на ПК
- Word, Excel
- Поисковый индекс
Реляционная Модель Данных (РМД)
- Структурный аспект
- Аспект целостности
- Аспект обработки
Реляционные Базы Данных: ACID Atomicity - Атомарность Consistensy - Согласованность Isolation - Изолированность Durability - Надёжность
РБД: плюсы
- Универсальный доступ к данным (SQL)
- Контроль за целостностью (ACID)
- Одновременный доступ к данным
- Повышенная безопасность
РБД: минусы
- Тяжело хранить иерархические данные
- Проблемы с масштабируемостью
РБД: примеры
- Системы документооборота
- Интернет магазины
- Социальные сети
(наверх)
Основные черты NoSQL
- Применение различных типов хранилищ
- Нефиксированная схема БД
- Использование многопроцессорности
- Линейная масштабируемость
- Сокращение времени разработки
Базовые события в становления NoSQL
- Big Table(Google)
- Dynamo(Amazon)
- CAP Theorem
Основные свойства системы
- Consistensy - непротиворечивость данных
- Availability - доступность данных
- Partitionability -разделяемость данных на изолированные части
CAP Theorem Можно иметь только два из трёх свойств в любой shared-data системе
Consistensy Models
- Строгая
- Последовательная
- Причинная
- Процессорная
- Слабая
- Консистентность в конечном счёте
- Консистентность по выходу
- Консистентность по входу
BASE вместо ACID
- Basically Available - базовая доступность
- Soft State - гибкое состояние
- Eventually Consistent - согласованность в конечном счёте
Типы NoSQL
- Key/Value (модель данных: хеш-таблица)
- Amazon S3
- Voldemort
- Column-based (модель данных: разряженная матрица)
- HBase
- Cassandra
- Document-based (модель данных: дерево)
- MongoDB
- OrientDB
- Graph-based (модель данных: граф)
- Allegro
- InfiniteGraph
(наверх)
Особенности HBase
- Распределённая база данных
- Работает на кластере серверов
- Легко горизонтально масштабируется
- NoSQL база данных
- Не предоставляет SQL-доступ
- Не предоставляет реляционной модели
- Column-Oriented хранилище данных
- нет фиксированной структуры колонок
- произвольное число колонок
- Спроектирована для поддержки больших таблиц
- Миллиарды строк и миллионы колонок
- Поддержка произвольных операций чтения/записи
- Основана на идеях Google BigTable
- BigTable поверх GFS => HBase поверх HDFS
- Масштабируемость с помощью шардирования
- Автоматический fail-over
- Простой Java API
- Интеграция с MapReduce
Когда нужно использовать HBase
- Большие объёмы данных
- Паттерн доступа к данным:
- Выборка по заданному ключу
- Последовательный скан в диапазоне ключей
- Свободная схема данных
- Строки могут существенно отличаться по своей структуре
- В схеме может быть множество колонок и большинство из них будет равно null
Когда НЕ нужно использовать HBase
- Традиционный доступ к данным в стиле РБД
- Приложения с транзакциями
- Реляционная аналитика ('group by', 'join')
- Плохо подходит для доступа к данным на основе текстовых запросов (LIKE %text%)
HBase Column Families
Column Family описывает общие свойства колонок:
- Сжатие
- Количество версий данных
- Время жизни (Time To Live)
- Операция хранения только в памяти (In-memory)
- Хранится в отдельном файле (HFile/StoreFile)
- Конфигурция CF статична
- Задаётся в процессе создания таблицы
- Количество CF ограничено небольшим числом
- Колонки наоборот НЕ статичны
- Создаются в runtime
- Могут быть сотни тысяч для одной CF
HBase Timestamps
- Ячейки имеют несколько версий данных
- Настраивается в конфигурации ColumnFamily
- По умолчанию равно 3
- Данные имеют timestamp
- Задаётся неявно при записи
- Явно указывается клиентом
- Версии хранятся в убывающем порядке ts
- Последнее значение читается первым
(наверх)
Масштабируемость в HBase
- Таблица делится на регионы
- Регион - это группа строк, которые хранятся вместе
- Еденица шардинга
- Динамически делится пополам, если становится большим
- RegionServer - демон, который управляет один или несколькими регионами
- Регион принадлежит только одному RS
- MasterServer (HMaster) - демон, который управляет всеми RS
HBase Regions
Регион - это диапазон ключей: (Start Key; Stop Key)
- Start Key включается в регион
- Stop Key не включается
- По умолчанию есть только один регион
- Моэно предварительно задать количество регионов
- Припревышении лимита, регион разбивается на 2 части
HBase Regions Split
- Регионы более сбалансированы по размеру
- Быстрое восстановление, если регион повредился
- Баланс нагрузки на RegionServer
- Split - это быстрая операция
(наверх)
Так же как и MapReduce, Spark предназначен для анализа больших объёвом данных. Также с одной стороны является фреймворком, с другой стороны является неким подходом. Тоесть некоторой парадигмой в которой могут быть реализованы алгоритмы для обработки больших объёмов данных.
Преимущества Spark
- Следующая ступень в обработке BigData:
- Интерактивные задачи
- Интерактивная аналитика
- Может работать с разными типами данных (текст, графы, базы данных)
- Может обрабатывать данные по частям (batch) и в потоке (streaming)
- Имеет 80 высокоуровневых функций для обработки данных (кроме map и reduce)
(наверх)
Apache Spark - это высокопроизводительный фреймворк для обработки больших данных, который использует параллелизм в памяти для ускорения вычислений. Он предоставляет набор инструментов для работы с данными, включая мощный API для распределенной обработки данных.
В Spark операторы используются для выполнения различных операций над данными, таких как фильтрация, преобразование, агрегирование и соединение. Операторы Spark можно разделить на три основные категории:
-
Трансформации (Transformations): Трансформации используются для преобразования данных из одного формата в другой, например, для фильтрации, сортировки, объединения или группировки данных. Трансформации являются ленивыми, что означает, что они не выполняются немедленно, а только когда выполняется действие (Action).
-
Действия (Actions): Действия используются для выполнения операций над данными и вывода результатов. Действия запускают вычисления и могут приводить к перераспределению данных или сохранению результатов в файлы или базы данных. Некоторые из наиболее распространенных действий в Spark включают count, collect, reduce, save и foreach.
-
Передача функций (Function Passing): Spark поддерживает передачу функций в качестве аргументов для выполнения операций. Это позволяет определять пользовательские функции для преобразования или агрегирования данных, а также использовать встроенные функции для выполнения операций над данными.
Среди наиболее распространенных операторов Spark можно выделить следующие:
filter(): Фильтрует элементы в RDD (Resilient Distributed Datasets), возвращая только те, которые соответствуют определенному условию.map(): Применяет функцию к каждому элементу в RDD, возвращая новый RDD с результатами.flatMap(): Аналогично map, но каждый элемент может быть преобразован в 0 или более элементов в новом RDD.reduce(): Выполняет агрегацию данных путем применения функции к каждой паре элементов в RDD и возвращения результата.groupByKey(): Группирует элементы в RDD по ключу, возвращая пары (ключ, последовательность значений).sortByKey(): Сортирует элементы в RDD по ключу.union(): Объединяет два RDD в один RDD.join(): Выполняет соединение двух RDD на основе ключевого поля.distinct(): Удаляет дублирующиеся элементы из RDD, возвращая новый RDD с уникальными элементами.sample(): Возвращает случайную выборку элементов из RDD с заданной вероятностью.take(): Возвращает первые n элементов из RDD.count(): Возвращает количество элементов в RDD.collect(): Собирает все элементы из RDD и возвращает их в виде массива на драйвер-узел.foreach(): Применяет функцию к каждому элементу в RDD, выполняя заданное действие.cache(): Кэширует RDD в памяти, чтобы ускорить повторное использование.
Кроме того, Spark предоставляет набор операторов для работы с файлами и базами данных, такие как:
textFile(): Загружает текстовый файл в RDD.wholeTextFiles(): Загружает несколько текстовых файлов в RDD как пары (имя файла, содержимое файла).sequenceFile(): Загружает файлы в формате Sequence, используемые в Hadoop, в RDD.saveAsTextFile(): Сохраняет RDD в текстовый файл.saveAsSequenceFile(): Сохраняет RDD в формат Sequence, используемый в Hadoop.saveAsObjectFile(): Сохраняет RDD в сериализованном формате в файл.
В целом, операторы Spark позволяют удобно и эффективно обрабатывать данные в распределенной среде, осуществлять преобразования, агрегацию и анализ данных. Благодаря мощным инструментам и поддержке большого количества источников данных, Spark стал одним из самых популярных фреймворков для работы с большими данными.
(наверх)
(наверх)
Как работает запрос на джойн таблиц в ClickHouse, если выполнять по ключу, который отсортирован и не отсортирован?
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)
(наверх)