variable scope problems in function definition #687
Comments
|
hmm - I think this might be related to running as a Spark application somehow since I see the very same thing running in a YARN cluster: Also, I'm not able to reproduce this using the regular (non-spark) python kernel in k8s... |

|
ok - this is an EG issue and was introduced by this commit: 2cdac42 @jcrist - we're going to need your help on this one. It seems the use of Your help is greatly appreciated! |
|
Hmmm, that's unfortunate. This looks to be due to ipython/ipython#62, and doesn't have a good workaround. The namespace thing was to avoid polluting the started kernel namespace with all the stuff enterprise gateway uses to setup a kernel. I recommend the following:
def start_ipython(locals, ns, **kwargs):
from IPython import embed_kernel
for k in list(locals):
if not k.startswith('__'):
del locals[k]
locals.update(ns)
embed_kernel(local_ns=locals, **kwargs)
if __name__ == '__main__':
# Existing code...
# Replace the `embed_kernel` call with this:
start_ipython(locals(), namespace, connection_file=connection_file, ip=ip)I've tested this works locally, and should fix things for you. I don't have time to test this myself on |
|
Thank you for your quick response - it's greatly appreciated! I have applied the changes above to the version you created (prior to #540). This does appear to address the scenario listed in this issue. However, any attempts to reference /hadoop/yarn/local/usercache/gateway/appcache/application_1559854930815_0039/container_e05_1559854930815_0039_01_000001/launch_ipykernel.py in __getattr__(self, name)
115 self._init_thread.join(timeout=None)
116 # now return attribute/function reference from actual Spark object
--> 117 return getattr(globals()[self._spark_session_variable], name)
118
119
/hadoop/yarn/local/usercache/gateway/appcache/application_1559854930815_0039/container_e05_1559854930815_0039_01_000001/launch_ipykernel.py in __getattr__(self, name)
113 else:
114 # wait on thread to initialize the Spark session variables in global variable scope
--> 115 self._init_thread.join(timeout=None)
116 # now return attribute/function reference from actual Spark object
117 return getattr(globals()[self._spark_session_variable], name)
/opt/conda/lib/python2.7/threading.pyc in join(self, timeout)
928 if not self.__started.is_set():
929 raise RuntimeError("cannot join thread before it is started")
--> 930 if self is current_thread():
931 raise RuntimeError("cannot join current thread")
932
/opt/conda/lib/python2.7/threading.pyc in currentThread()
1149 """
1150 try:
-> 1151 return _active[_get_ident()]
1152 except KeyError:
1153 ##print "current_thread(): no current thread for", _get_ident()
RuntimeError: maximum recursion depth exceeded |
|
Ahh, hmmm, this has to do with this bit of code, which is accessing raw Is there a noticeable lag if you initialize the spark context variables before starting the kernel? Since the spark application is already running, I wouldn't expect much of an issue? Otherwise you'll need to propagate the |
|
I see. So you're asking if we not create a thread, but do the init synchronously? Yeah, the spark context creation takes on the order of 5-10 seconds and we need that time to be in the background so users can attempt to do non-spark things first (and not have to wait the additional time for sc creation). I'm barely following what's going on but will try the EDIT: @jcrist Actually, I have no idea what to do here. 🙁 |
The python kernel launcher was not initializing the namespace used in the embed_kernel properly. This change reverts an earlier change to use the spark context variables from the global scope, instead moving them to the local namespace. Fixes jupyter-server#687
|
@jcrist - ok, I think I've battled through things and ferreted out what your comments were saying relative to the Could you please review the changes and let us know if we can make this better? |
The python kernel launcher was not initializing the namespace used in the embed_kernel properly. This change reverts an earlier change to use the spark context variables from the global scope, instead moving them to the local namespace. Fixes jupyter-server#687 Closes jupyter-server#688
|
Wow. I'm impressed by your engagement! Let me know, if I can help you somehow |
|
@seegy - if you'd like to take an updated image for a spin, I've pushed an image to To confirm you're running with the correct image, ensure that its I'd like to wait for @jcrist's opinion before merging. |
|
hey @kevin-bates , unfortunately, I'm on vacation the upcoming week. So, I will have no access to our k8s environment... |
|
@seegy , no worries. Enjoy your vacation! I moved this to WIP since we're still working things out. |
The python kernel launcher was not initializing the namespace used in the embed_kernel properly. This change reverts an earlier change to use the spark context variables from the global scope, instead moving them to the local namespace. Fixes jupyter-server#687 Closes jupyter-server#688
* Fix scoping issues relative to python kernels on Spark The python kernel launcher was not initializing the namespace used in the embed_kernel properly. This change reverts an earlier change to use the spark context variables from the global scope, instead moving them to the local namespace. Fixes #687 Closes #688
|
@seegy and @suryag10, Since this issue is now closed and the fix has been merged, I have updated the docker default images Thank you for reporting this issue and your timely testing - its been appreciated! |
|
|

|
@kevin-bates Thanks. Saved my day 👍 |
Hi there,
I'm using enterprise gateway on our kubernetes cluster (following this instructions).
Using a python notebook (in my case the kernel is
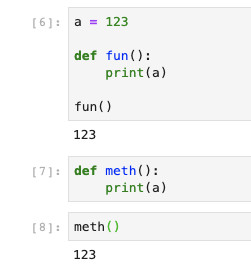
elyra/kernel-spark-py:dev) I found the problem, that I cannot use variables inside a function definition, which are defined outside.Example:
ends in:
Same with import...
Any ideas?
The text was updated successfully, but these errors were encountered: